跳至主要內容
牛牛码特
场景设计
计算机基础
八股题库
牛牛码特
欢迎来到牛哥的技术世界~
欢迎来到
牛哥的技术世界~
二本逆袭
校招进腾讯
3W+粉丝
后端专家
腾讯二进宫
字节面试官
面试经验1000场
关于作者
牛哥
二本毕业
,靠着校招进了
腾讯
,一路走来:
腾讯→外企→字节→腾讯
。现在专注技术学习,已经帮助
1000+ 开发者
拿到心仪的offer。本站所有文章都为我的原创文章,希望能用我的经验,让你少走弯路,早日实现技术梦想!
关于本站
第一站:【计算机基础】 — 打牢地基,才能起飞
我把抽象的计算机底层逻辑,画成了你能跟着走的故事线,每篇 20张+ 手绘技术图,连协议细节都用生活例子讲透了。
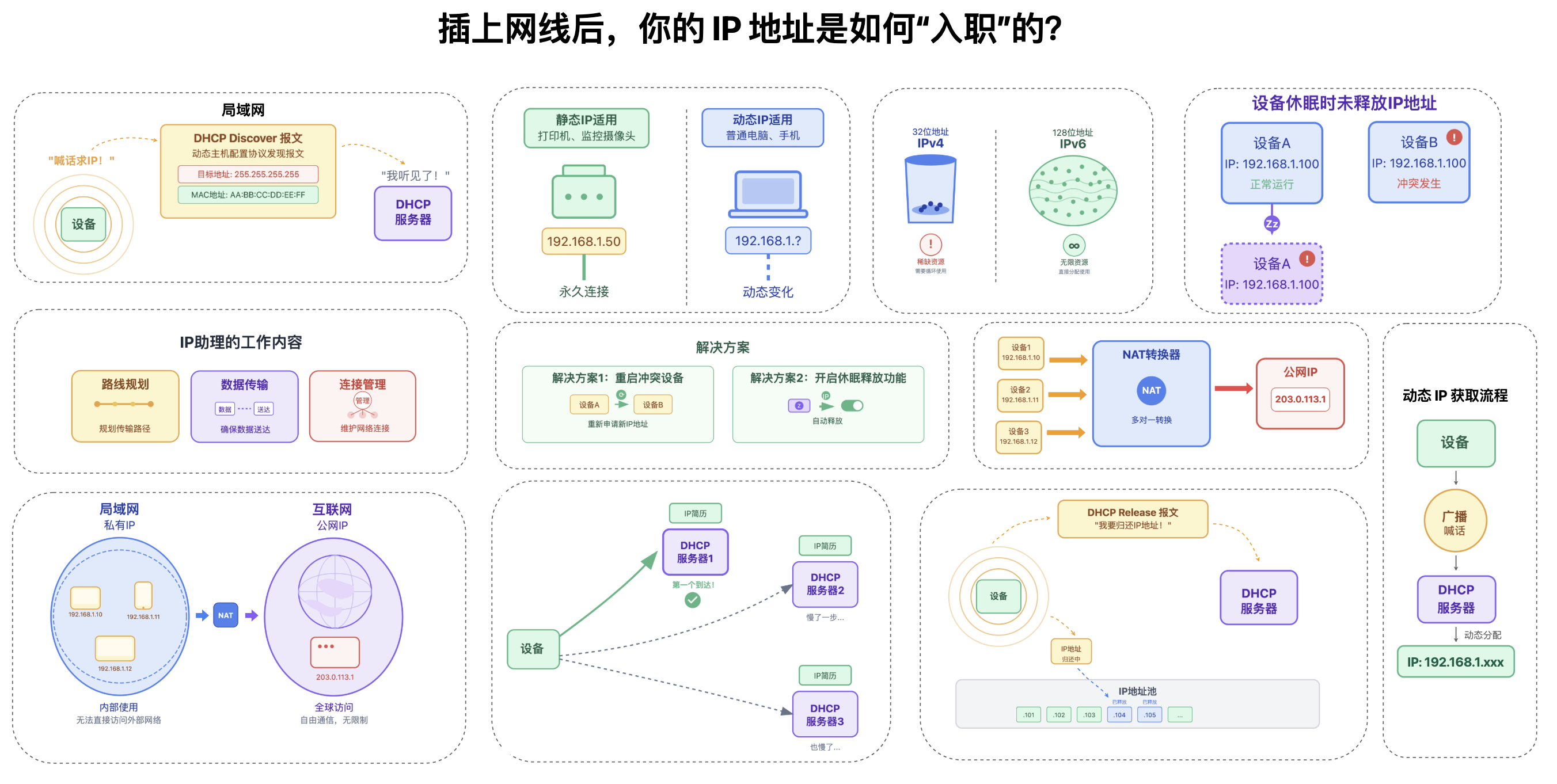
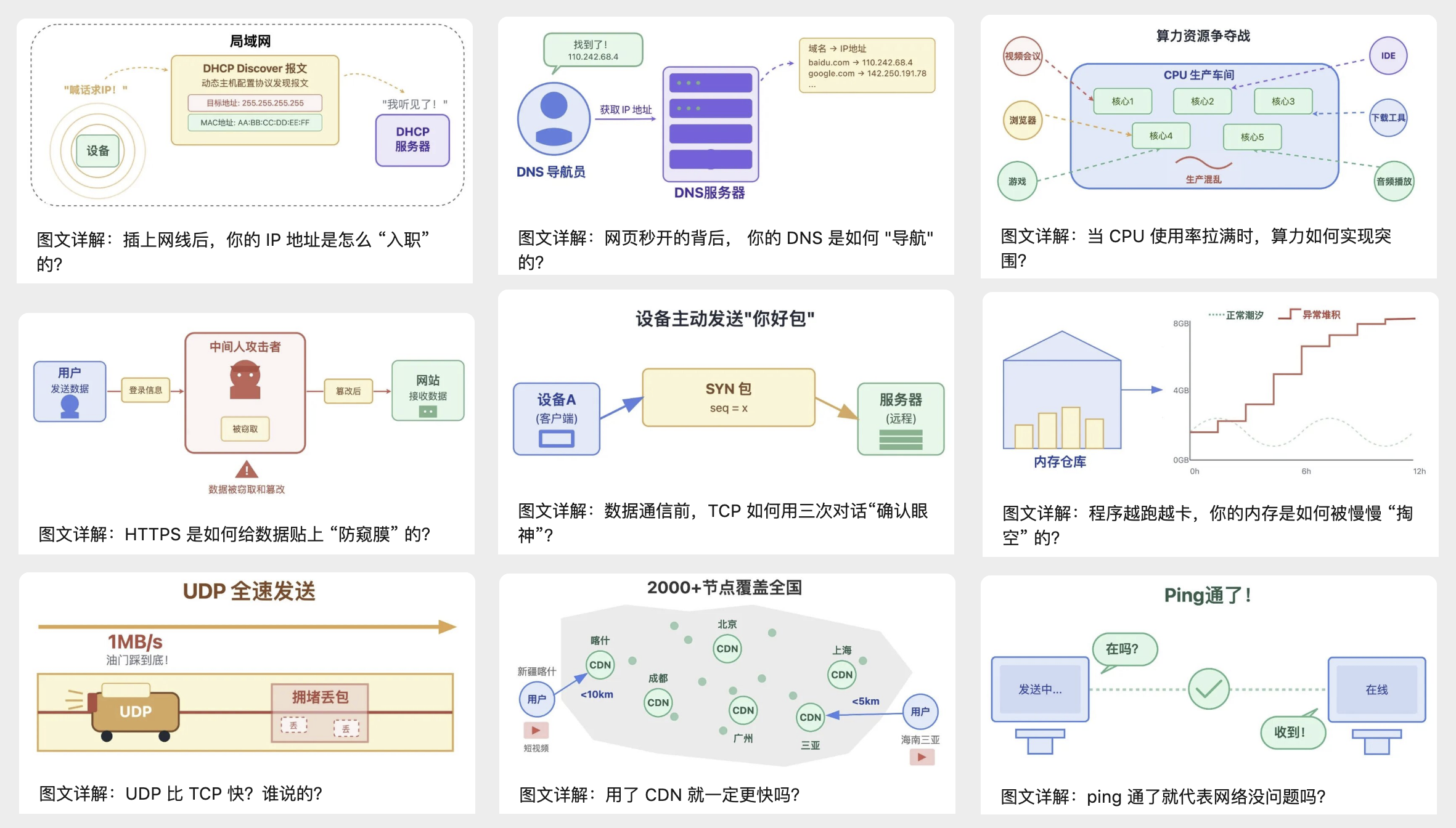
剧情式拆解网络协议:
把 IP、DNS、HTTPS、TCP 这些枯燥协议变成剧情化的故事 — 比如
插上网线后,IP 地址是怎么像「新员工入职」一样绑定到设备的?
HTTPS 又是如何给数据贴上防窥膜的?
顺着这些故事走下来,枯燥的网络协议就变得直观又好懂。
场景化解读操作系统:
把 CPU调度、内存泄露这些复杂的操作系统知识,裹上生活场景的外衣 — 原来
CPU 分配算力的逻辑
,就像工厂车间的调度员安排工人干活;
内存被占满的过程
,就是小偷一点点搬空内存仓库的过程,复杂概念瞬间直观;
打破认知误区:
针对「
UDP 比 TCP 快?
」「
ping 通了就代表网络没问题?
」这些想当然的常识,我用实测数据 + 对比图拆解真相,让你搞懂不同场景该选什么技术,而不是盲目跟风追热门。
第二站:【场景设计】 — 从会用到会设计
光把基础嚼碎了还不够,后端工程师的核心竞争力从来都是用技术解决实际问题。网站这个模块的核心思路是 「场景拆解→核心问题→技术选型→方案落地」 ,每篇都聚焦真实工作中一定会遇到的场景,拒绝空洞理论:
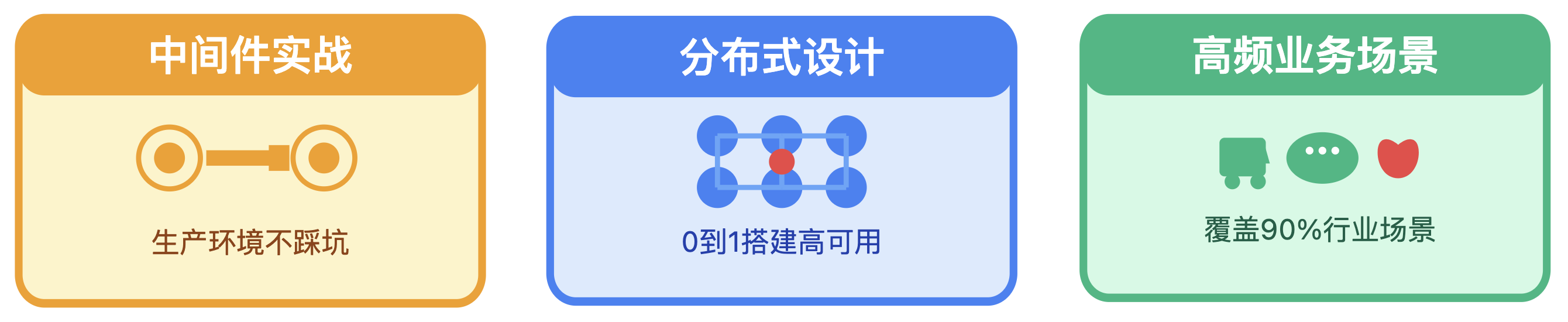
中间件实战:
不教你怎么安装配置,只讲生产环境怎么用不踩坑 — 比如「
消息队列积压了怎么快速恢复?
」,全是能直接落地的操作细节;
分布式设计:
从 0 到 1 教你搭建高可用系统 — 比如「
异地多活架构怎么落地才不翻车?
」,每一步都推导为什么这么选,方案权衡、性能瓶颈、容错处理全讲透;
高频业务场景:
覆盖社交、电商等行业 90% 高频场景 — 比如「
抗百万并发的点赞系统怎么实现?
」,每篇都附流程图、核心代码片段、优化技巧,抄起来就能用。
第三站:【八股题库】 — 不是背题,是会答题
面试中绕不开的必考点还有八股文,但八股考的从来不是背答案,而是对知识的理解深度。这个模块整理了 600 + 面试真题,不止给答案,更告诉你面试官想考察什么,帮你跳出「背了又忘」的循环:
Java 题库:
作为企业级开发的常青树,覆盖从基础语法到 JVM、集合、并发的全链路知识点。开始前强烈建议先读《
Java 面试题库指南
》— 里面有知识地图、学习方法,帮你找准定位,效率翻倍;
Golang 题库:
针对高并发、云原生领域的新势力,从基础到进阶系统梳理。同样附《
Go 语言面试题库指南
》,帮你避免盲目刷题,每一步都有明确方向;
后端核心组件:
围绕 MySQL、Redis、Kafka 三大必备工具,不止讲怎么用,更深入底层逻辑 — 比如 Redis 的持久化机制、MySQL 的索引优化,让你从会用组件升级为能调优、能排错。
学习交流
如果你在编程面试、技术提升的路上苦苦摸索,别错过牛哥的公众号
牛牛码特
,定期更新系列知识,帮你精准攻克面试难关。点个关注👆,优质内容不错过!
关注牛哥公众号:
牛牛码特
,回复:
1
,即可获得
秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
公众号