关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
大家好,我是牛哥。
今天咱们来聊一道后端面试高频考题 — 服务雪崩与熔断降级。
为了让知识点更成体系,整篇对话我将分为四个部分层层推进。
面试官:我看你做过电商后端,知道服务雪崩吗?
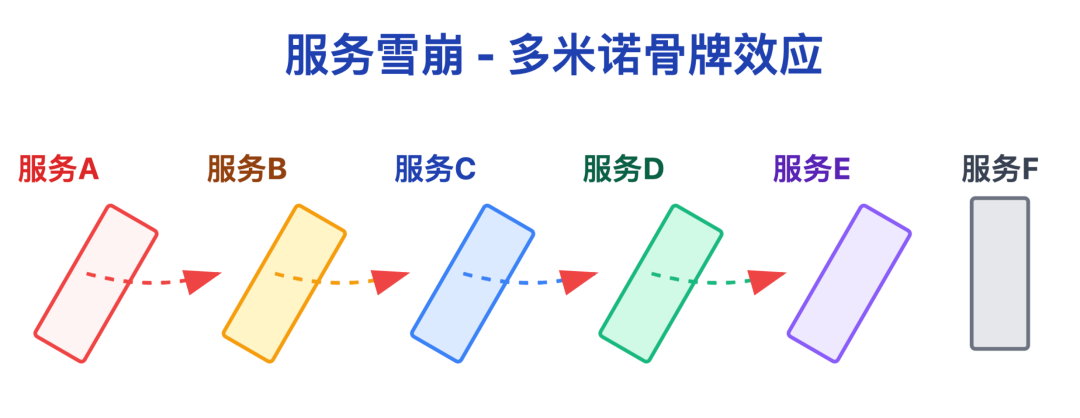
我:知道的,服务雪崩其实就是「依赖链路里的故障连锁反应」。
简单来说就像多米诺骨牌,一个服务倒了,后面依赖它的全跟着受影响,尤其微服务链路长的时候,雪崩传播速度特别快。
面试官:明白了,能举个实际场景中服务雪崩的例子吗?这样更直观
我:可以的,就拿电商最常见的 "商品 - 库存 - 仓储" 链路来说吧。
从正常运行到服务雪崩会经历三个阶段。
第一阶段:正常运行
电商系统中的商品、库存、仓储服务依次调用,正常运行。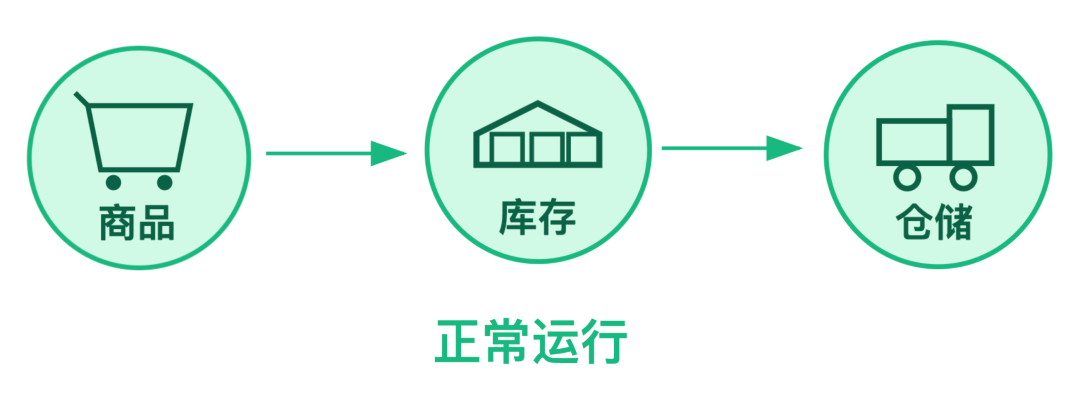
第二阶段:线程阻塞
这个时候,仓储服务突然故障,库存服务每次查询实时库存,响应时间都变得很慢,时间一长,库存服务的线程全被这类调用阻塞。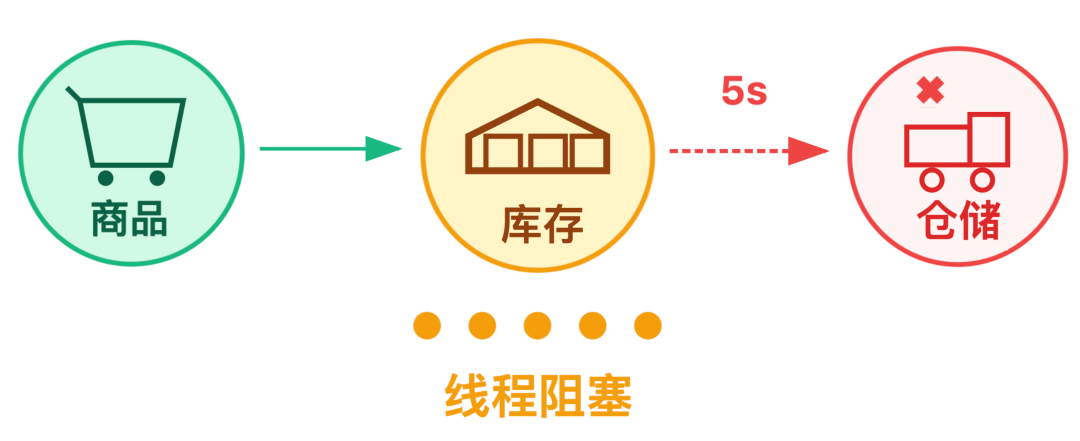
第三阶段:雪崩瘫痪
接着,库存服务没法及时响应,又会拖累上游的商品服务;最终商品服务的线程全部被占满。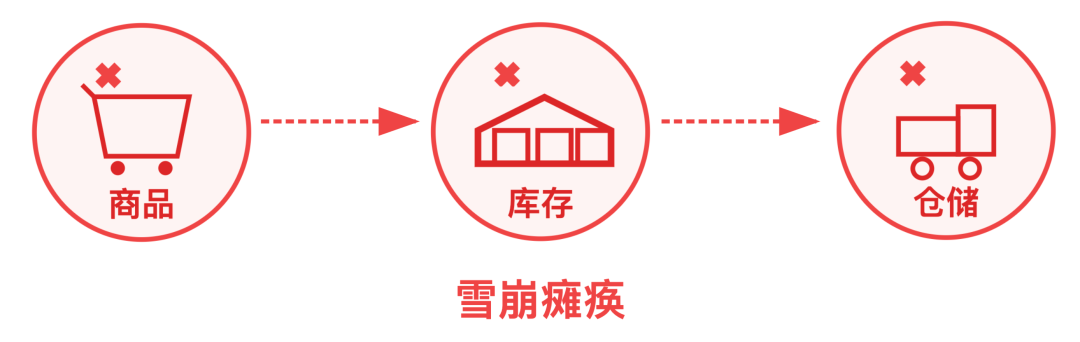
用户打开商品详情页时,加载半天没动静,好不容易点了下单,还弹出 "系统繁忙" 的提示。
整个交易链路就这么彻底瘫痪了,这就是典型的服务雪崩。
面试官:了解了,那雪崩一旦发生,一般有哪些手段能应对?总不能等着链路自己恢复吧?
我:主流的有两种核心手段,熔断和降级,但它俩应对的场景不一样,不能混着用。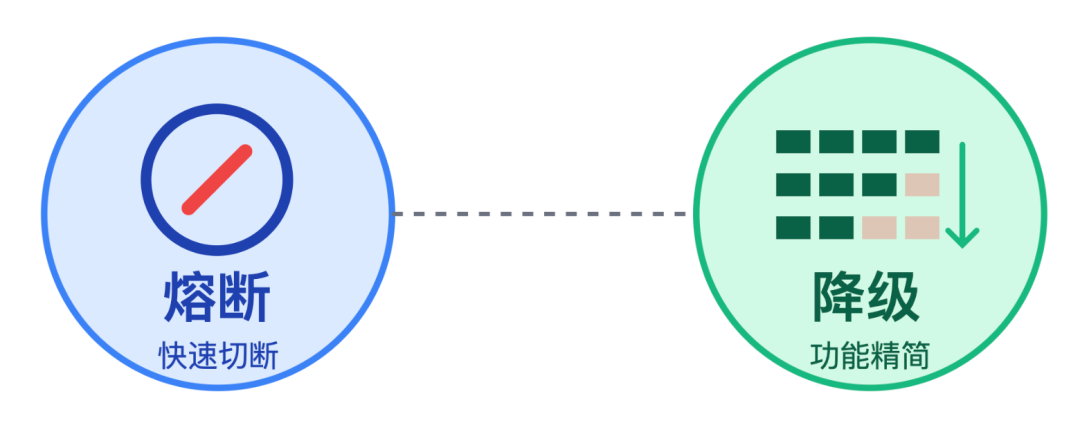
面试官:哦?熔断和降级都是解决雪崩的,他俩有啥区别?
我:这俩区别还挺大的。
熔断的核心目标是「防故障扩散」,适用于依赖服务出现明确故障的场景 - 比如库存服务因为依赖仓储出了故障,这时候得用熔断阻断故障扩散
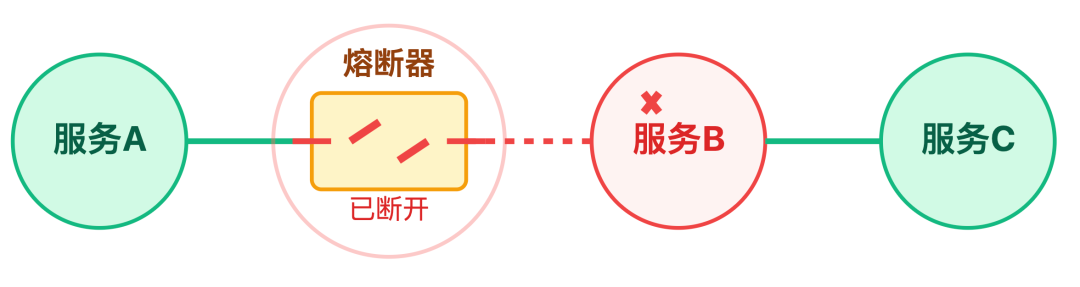
降级核心目标是「保核心可用」,适用于系统自身资源达到瓶颈的场景 - 比如大促期间,流量超了服务器扛不住,就需要用降级保核心功能

简单说,熔断是「故障隔离」工具,降级是「资源释放」工具,是应对不同问题的两种解法。
面试官:那先说说熔断吧,它具体怎么阻断故障扩散的?
我:熔断就像给商品服务和库存服务之间的调用装了个智能安全阀。
正常情况下,商品服务每次查库存都会实时调用库存服务;
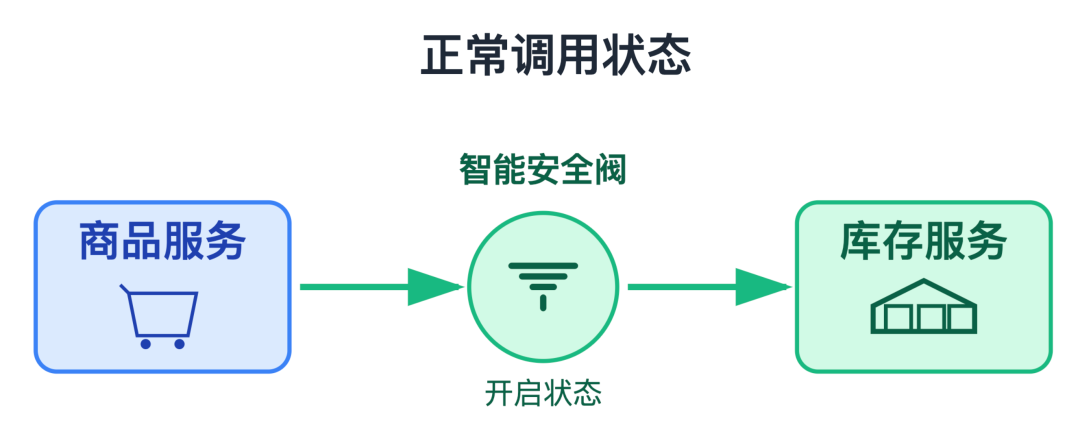
但是一旦请求出现超时或报错,并且错误率超过我们设置的阈值,熔断就会触发。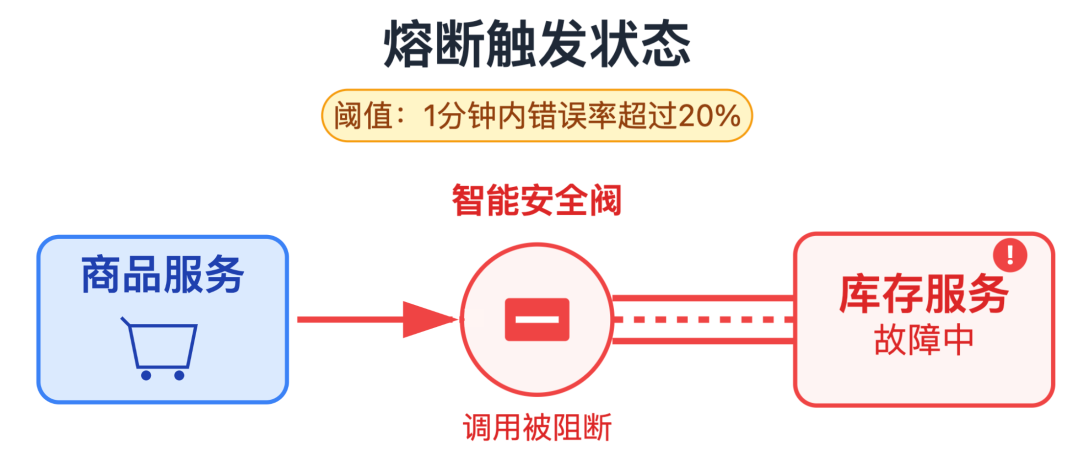
面试官:那触发后会怎么做?直接不让商品服务调用库存了?用户看不到库存,不影响下单吗?
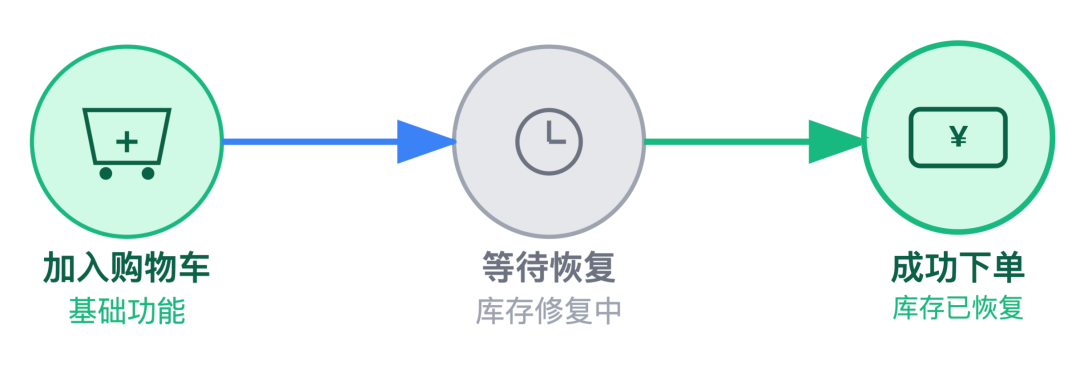
我:触发后确实会暂时阻断调用,但不会让用户完全无法操作。
我们会设置「友好的降级返回」,比如返回 "当前库存查询稍忙,可先将商品加入购物车,稍后尝试下单" 的提示,而不是直接报错。

这样做有两个好处:
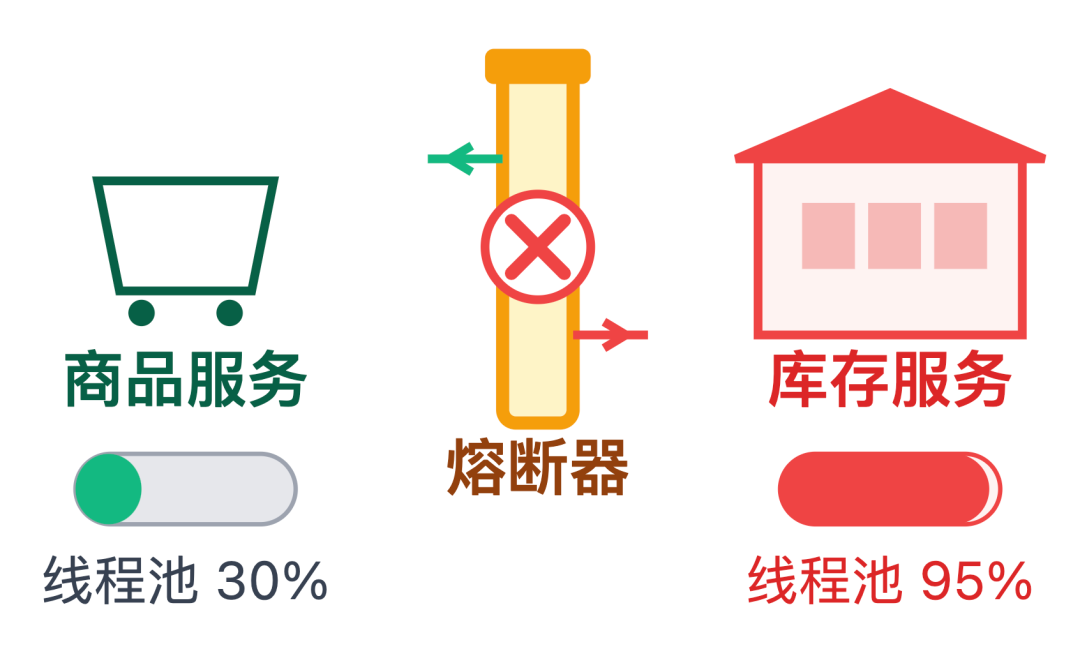
面试官:考虑得挺周全,那库存服务恢复后,熔断怎么知道要重新打开调用呢?总不能一直阻断吧?
我:这里有个关键设计叫「熔断状态机」,可以把它想象成智能红绿灯。
它通过关闭、打开、半开三种灯态,实现对故障的精准拦截和智能恢复。
熔断状态机 — 智能红绿灯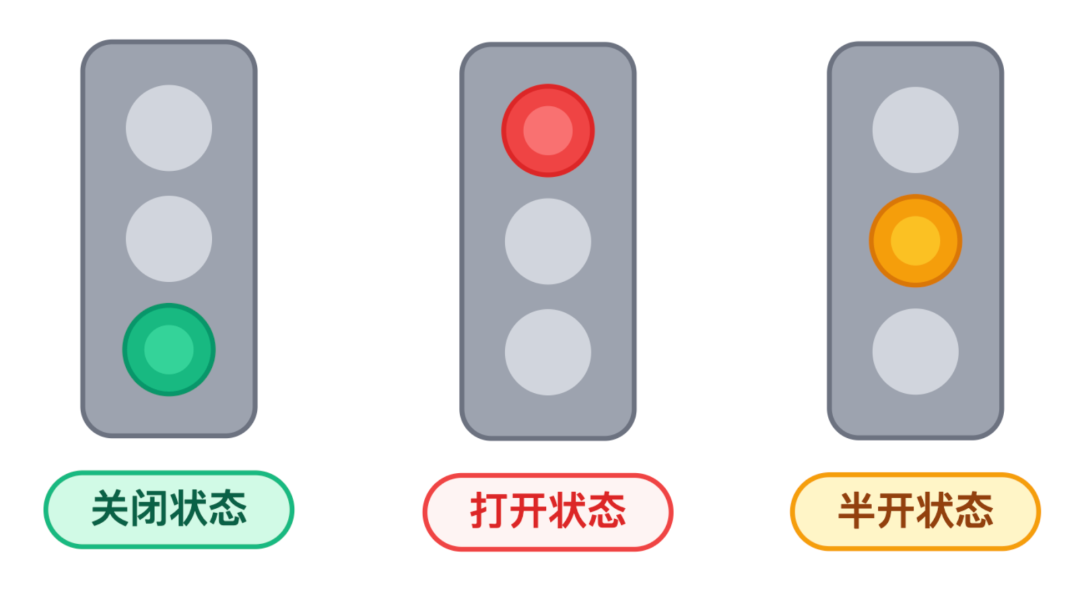
正常时是绿灯(熔断关闭),调用像车流一样顺畅通过。一旦错误率超标,状态立刻变成红灯(熔断打开),所有调用都被拦住,直接返回降级提示,而且会保持红灯 5 分钟左右。
状态切换:绿灯 → 红灯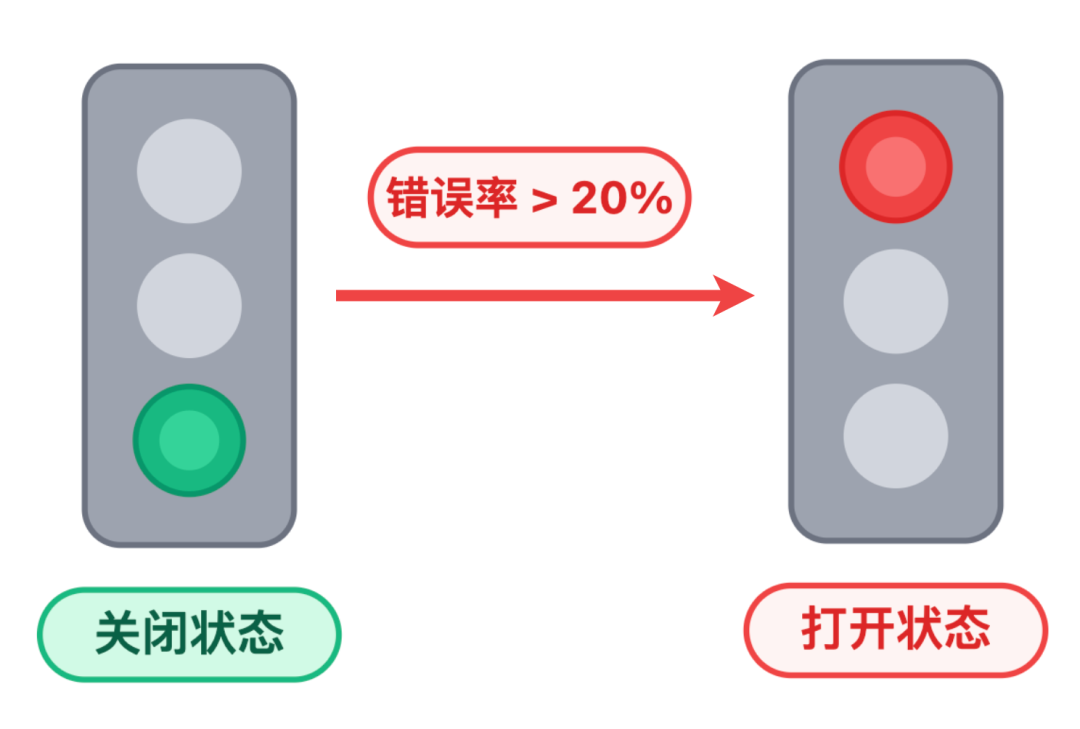
等红灯时间到了,状态会进入黄灯(熔断半打开):只允许 10 辆左右的请求车试探着通过。
状态切换:红灯 → 黄灯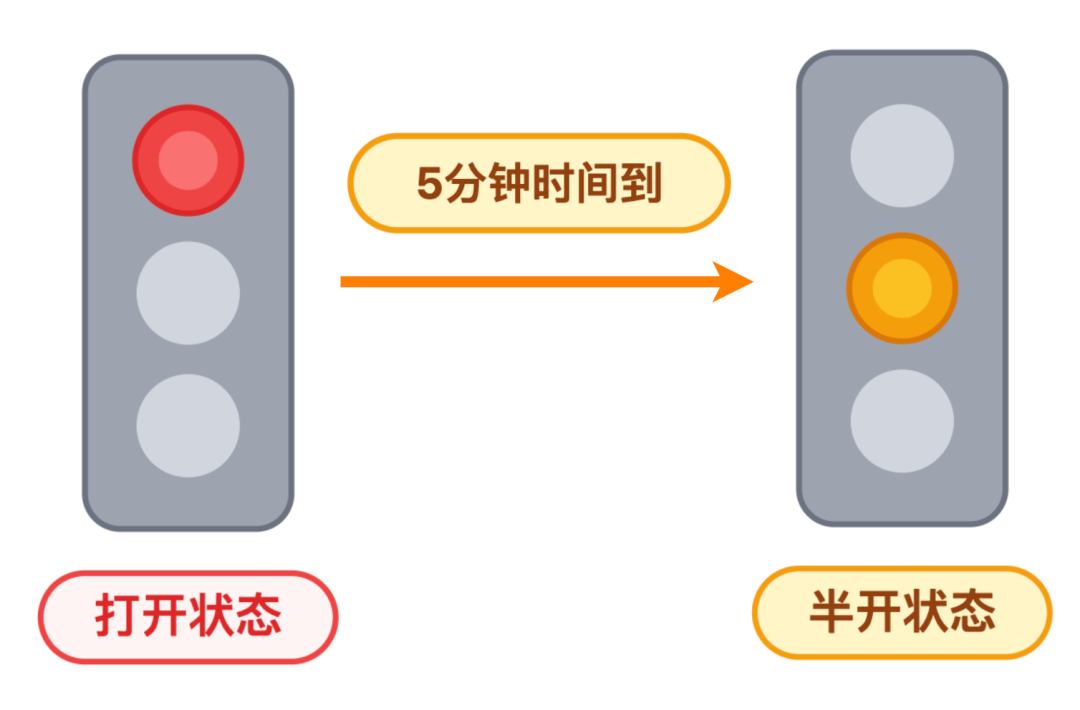
如果这 10 辆车的通过失败率低于 5%,说明下游路通了,状态就切回绿灯,正常通行;如果失败率还是很高,那就继续保持红灯,稍后再尝试。
状态切换:黄灯 → 绿灯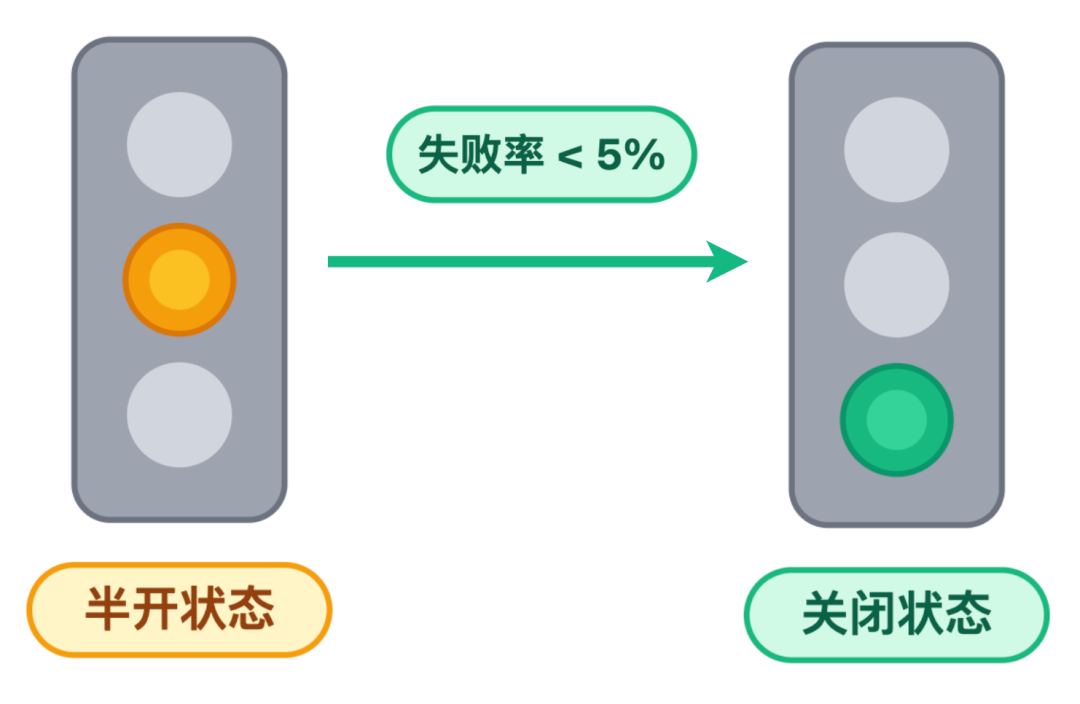
这种「绿灯放行、红灯拦截、黄灯试探」的逻辑,让这个智能红绿灯既不会因盲目放行引发新拥堵,也不会一直拦着耽误路恢复,特别贴合分布式系统的稳定性需求。
面试官:那再聊聊降级吧,什么时候该用降级?
我:降级主要用在「系统自身资源不够用」的情况。
最典型的就是电商大促。比如平时商品服务能扛 2 万 QPS,大促期间预估流量会涨到 6 万,但服务器的 CPU、内存最多只能扛 4 万。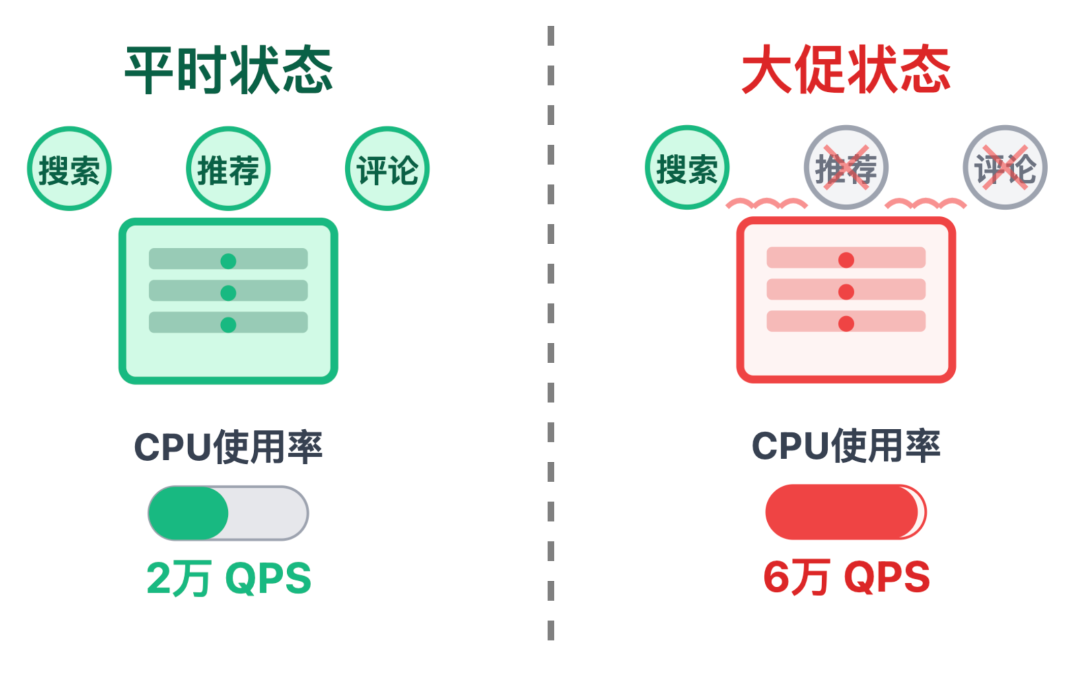
这时候没有任何服务故障,就是资源不够,再硬扛的话所有接口都会变慢,甚至崩掉,这时候就得降级。
面试官:那具体怎么降?有什么策略吗?
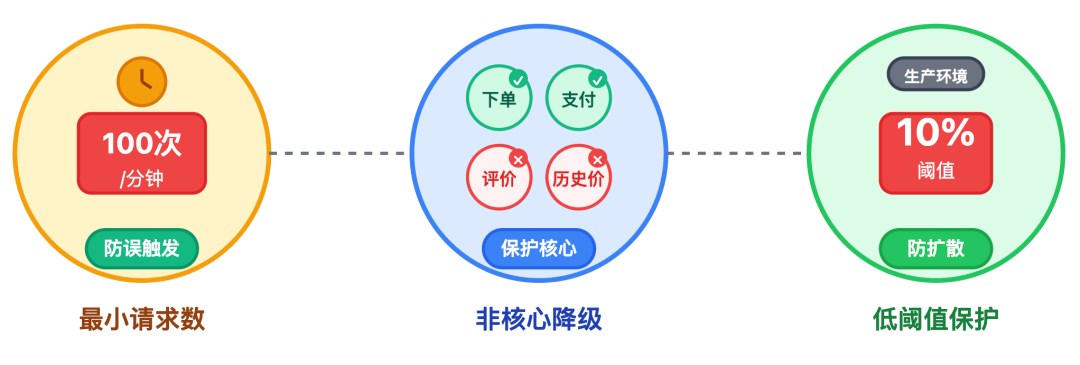
我:核心原则是 "舍小保大",先把非核心功能砍了,保障核心链路能用。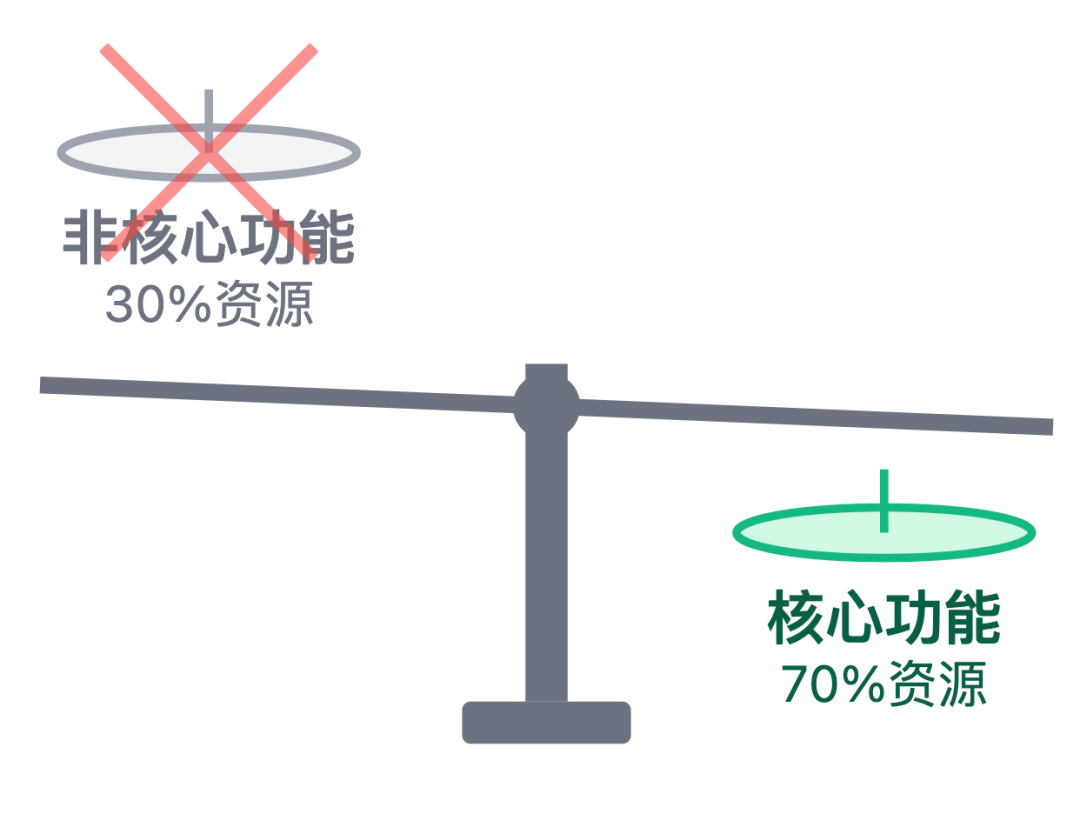
比如商品详情页里:

这样一来,大多数用户能正常下单,不会因为资源不够全链路卡顿。
面试官:清楚了,那实际业务中,会不会遇到熔断和降级需要一起用的情况?
我:太常见了!
比如大促高峰期,很可能同时遇到「依赖故障」和 「流量超峰」:假设库存服务突然报错率超 30%,这时候先触发熔断,商品服务暂时不调用库存;等大促流量真的到了 6 万,CPU 快满时,再触发降级,关掉评价列表和历史价格。
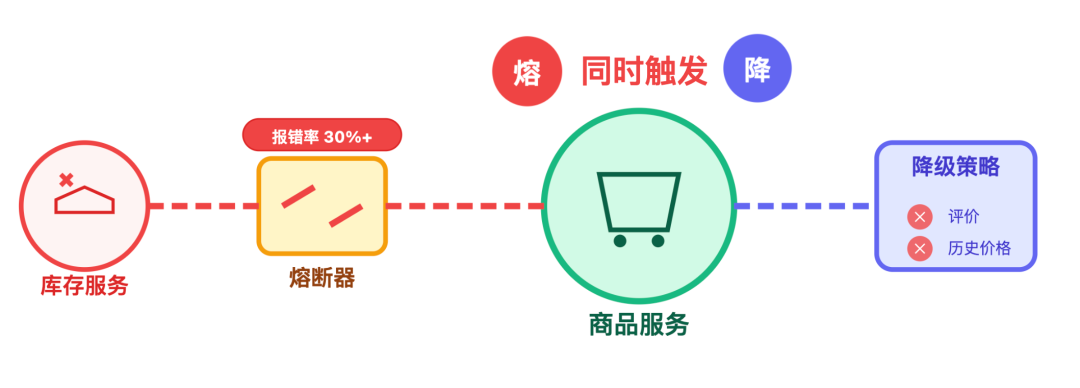
面试官:现在聊清楚了两者的区别,那熔断和降级的策略具体怎么落地呢?
我:第一步肯定是明确场景,这是最容易出错的地方。
首先先问自己两个问题:
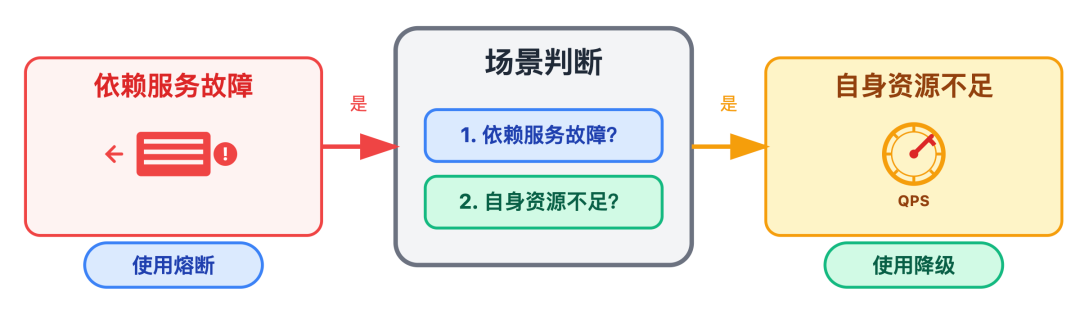
如果是错误率高、响应慢,就用熔断;如果是 CPU 满、QPS 超峰,就用降级。场景判断对了,后面选工具、配规则才不会走偏。
面试官:有道理,那电商场景里,常用的熔断降级工具有哪些?你是怎么选择合适的工具的?
我:国内电商项目里,用得最多的是 Sentinel 和 Resilience4j,我选择时主要看项目需求: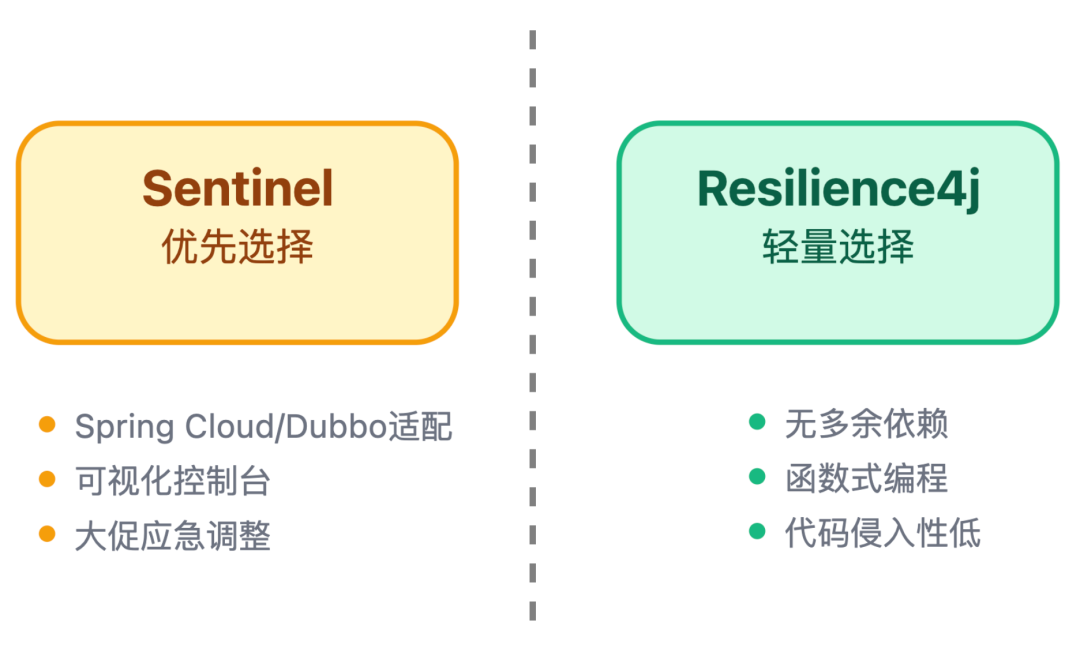
Sentinel 适用场景
如果项目用的是 Spring Cloud、Dubbo 这些主流框架,那 Sentinel 的适配性就特别好。
如果项目追求轻量,不想引入太多依赖,比如一些小型电商的订单服务,Resilience4j 更合适。
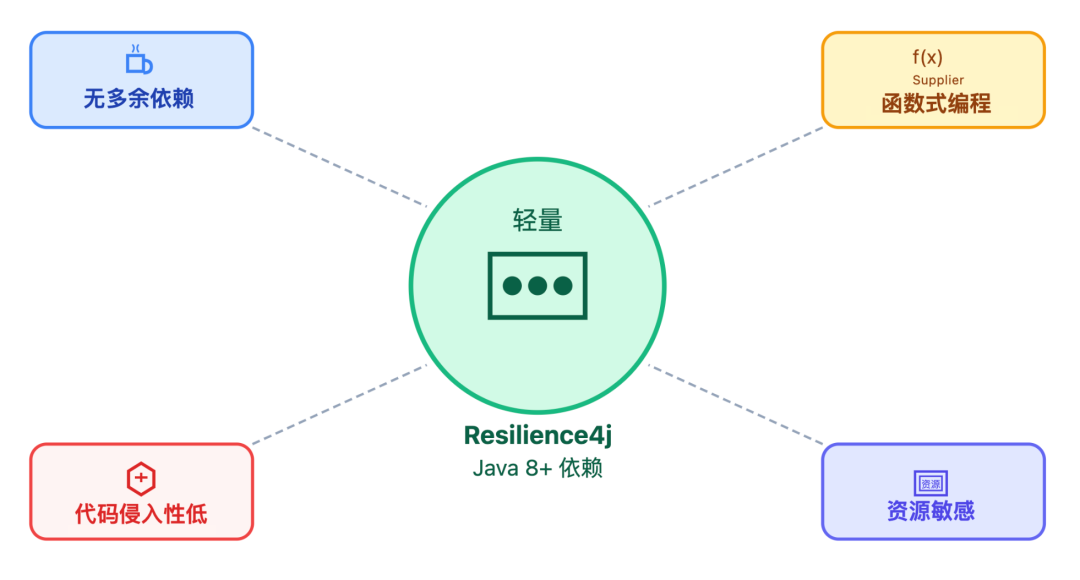
面试官:明白,能说说Sentinel这个工具是怎么用的吗?配置上有什么要注意的?
我:可以的,用 Sentinel 分为三步。

配置注意事项
面试官:配置细节很关键。那熔断降级后,如何验证策略是否生效呢?总不能等线上出问题才发现吧?
我:主要有两种验证方式,我们先提前在测试环境做好,避免线上踩坑:
第一种:功能验证
用工具模拟故障或超峰场景:
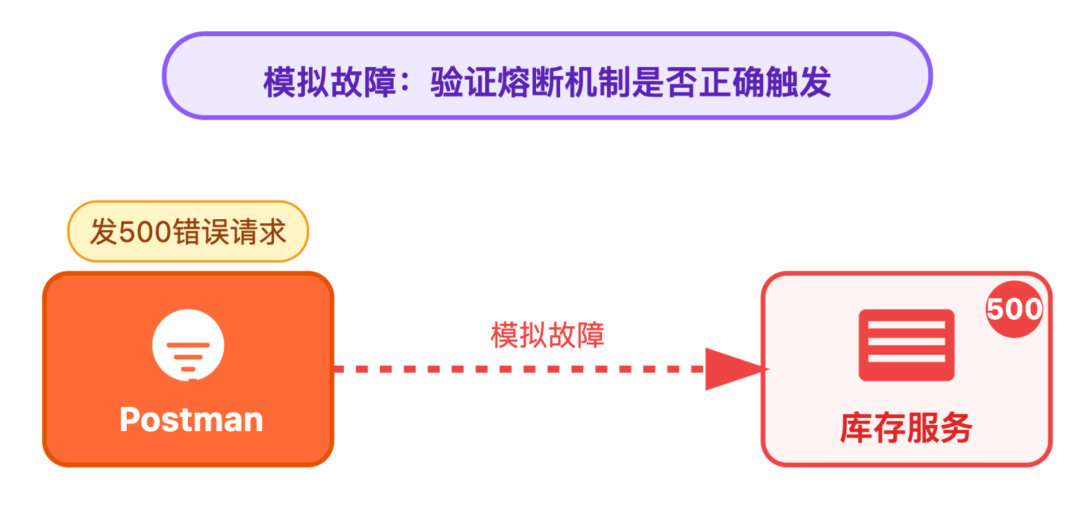
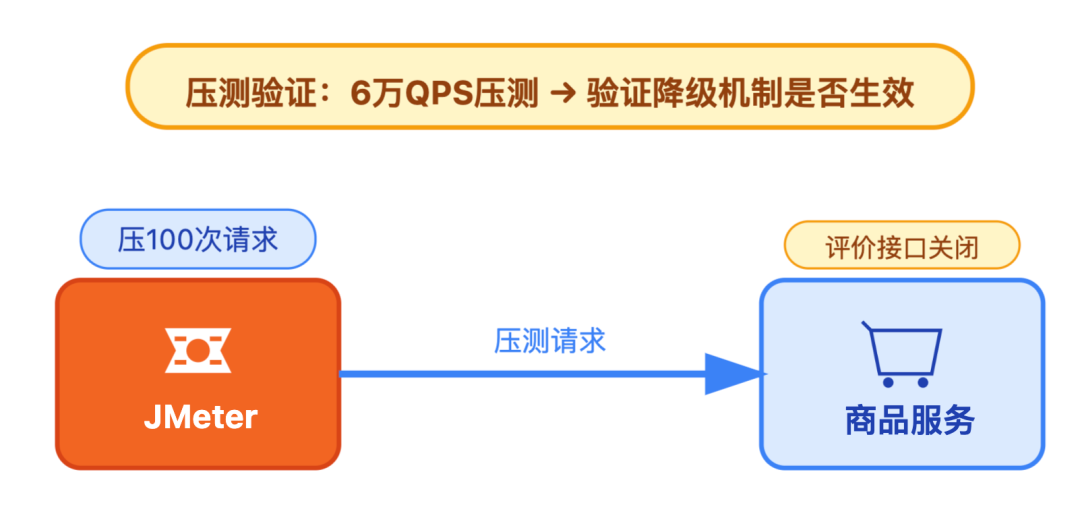
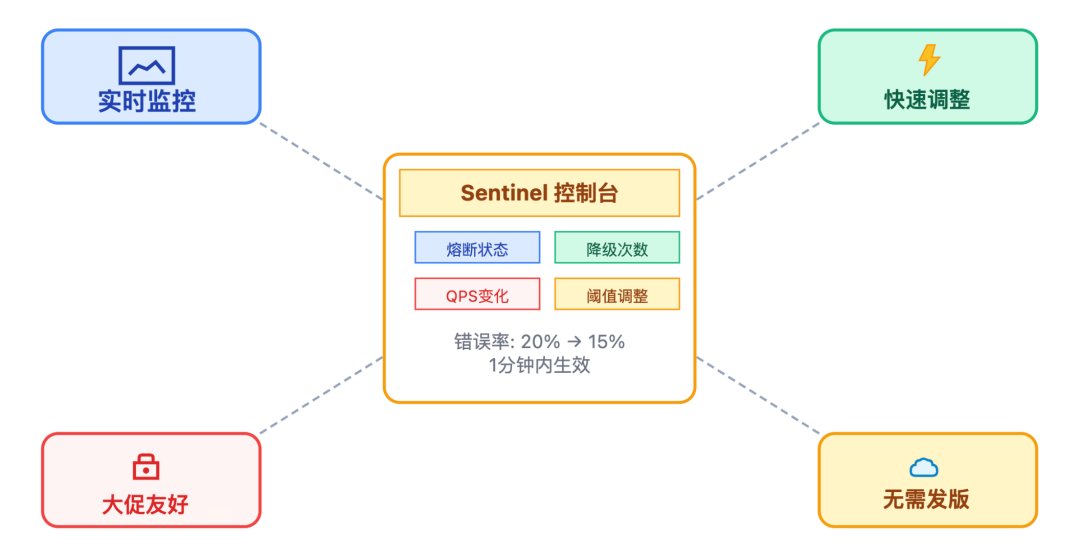
第二种:监控验证
看 Sentinel 控制台的实时数据:
面试官:考虑很全面。那后续如何评估「熔断降级对业务的影响」?比如会不会因为降级导致用户流失?
我:主要看两个核心维度,既要保系统稳定,也要尽量减少业务损失:
第一个维度:核心业务指标

第二个维度:用户体验指标

面试官:聊到这里,已经比较透彻了,最后你能总结下对熔断和降级的理解吗?
我:其实熔断和降级的核心,是分布式系统应对风险的生存智慧 — 不是追求永不故障,而是在故障或压力来临时,能优雅地妥协。
对电商系统来说,这两者不是孤立的工具,而是配合使用的「双保险」 — 大促时靠它们扛流量,故障时靠它们防雪崩。
最终达到「系统稳定」 和 「业务可用」 的平衡。

