关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
大家好,我是牛哥。
今天来跟大家好好聊聊 — 怎么搭一个能扛住百万级用户实时互动的高可用评论系统。
做技术方案前,牛哥先讲句大实话:
高可用评论系统不存在"完美架构",
咱们做技术拆解的核心不是找最优解,而是找适配业务的解。
要做高可用评论系统,得先把它的「灵魂三问」想明白:

评论这东西,对不同角色来说完全是两码事 — 这些差异直接决定了技术方案的「优先级排序」。
对用户来说,这是「情绪出口」+「决策工具」
刷剧到哭点想发"太刀了!编剧出来挨打",买手机前想翻"续航到底崩不崩",所以「能顺畅发、能痛快看」是底线。
对产品来说,这是「用户真心话收集器」+「内容护城河」
比问卷真实10倍的用户反馈都藏在评论里,千万级的UGC评论堆起来,就是用户舍不得走的「内容堡垒」。
对技术来说,这是「流量放大器」
评论就像演唱会散场时的地铁站,平时空荡荡,一到点瞬间挤爆。
这里很多人看到"百万级互动"就慌了,其实把流量拆成小零件,技术目标会清晰很多。
如果有10万用户发评论,那就有200万用户在刷评论。读写比大概是 20:1,所以读性能是体验的关键。

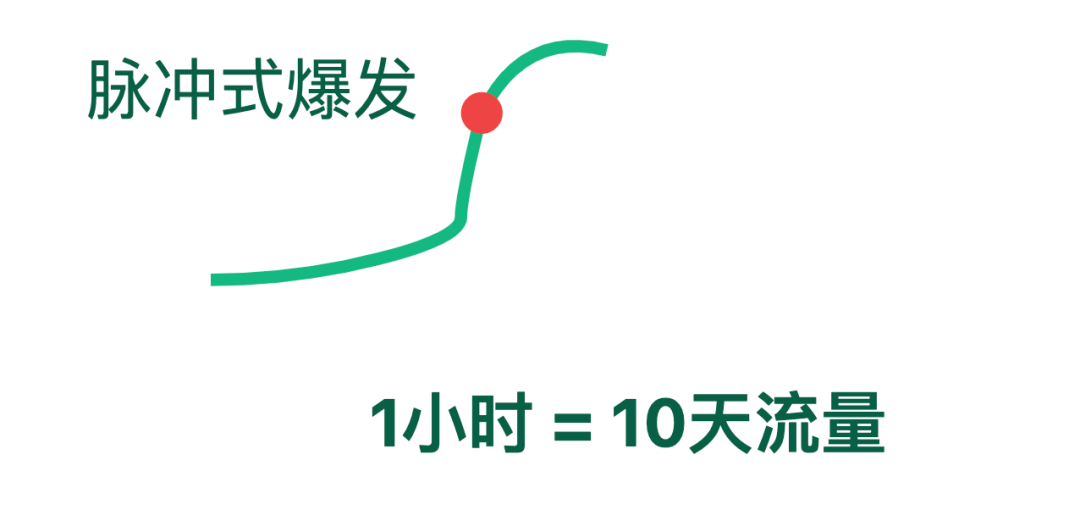
某明星官宣恋情时1小时的流量,就顶平时10天的量,因此设计时得按「峰值流量」配资源,按「低谷流量」用资源。
点赞数从1000变成1001慢3秒?无人在意。评论区转圈圈加载3次?80%用户直接划走。

所以技术方案得拎得清:先保能用,再优化实时
聊完了评论系统的特性,接下来就得明确:这些评论数据该怎么存。存储是评论系统的地基,方案选得不对,后面不管优化多少性能,都容易出问题。
首先通过一个表格来看三种存储方案:
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 纯MySQL(关系型) | 需要保证事务、评论嵌套层级≤3 级 | 支持ACID、数据可靠;索引成熟、运维熟悉 | 单表超千万后分页慢;分库分表逻辑复杂 |
| 纯MongoDB(文档型) | 非结构化内容多、评论嵌套深 | 原生存JSON嵌套、不用拆表;写入比MySQL快30% | 深嵌套查询慢;事务支持弱 |
| MySQL+Redis(混合) | 多数评论业务 | MySQL存全量保可靠;Redis存热点扛读压 | 双写易不一致(MySQL更了Redis没更);系统复杂度高 |
为什么大部分业务场景下,我更推荐第三种方案:MySQL+Redis 混合存储
不是 MongoDB 不好,而是它撑不起大多数业务的刚需 —「数据不丢」、「查得别慢」。反观 "MySQL+Redis" 混合存储,刚好解决了大多数业务的痛点:
这里还有个问题,
双写一致性怎么破?
核心方案是先写 MySQL,确认写入成功后再删 Redis 缓存。后续用户查询时,若 Redis 中没有对应数据,会自动从 MySQL 加载最新数据并回写到 Redis。
解决了存得稳的问题,接下来就得追求查得快了。缓存这东西,就像冰箱,不是塞得越满越好,而是得按需存放。
大部分高并发场景都得靠「本地缓存 Caffeine + Redis 集群」的组合拳,层层减压:
本地缓存 Caffeine:扛"超热点"的第一道防线
本地缓存适合存 5 分钟内被查 ≥ 1000 次的评论,比如爆款文章前 100 条评论,它的响应速度能到微秒级,比 Redis 快 100 倍。通常配置最大 10 万条缓存,过期时间 1 小时。

Redis集群:扛"次热点"的主力军
除了那些极致火爆的评论,剩下的高频访问数据由 Redis 集群承载。这里按内容 ID 进行哈希分片,通常分为 16 个分片,避免热点Key扎堆。

这里你可能会问,本地缓存和 Redis、Redis 和 MySQL 之间,数据不一致怎么办?
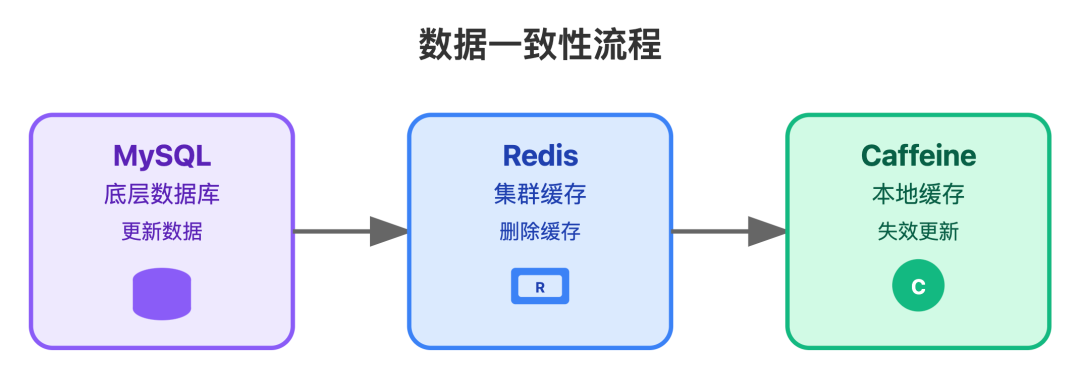
其实核心思路是抓大放小:优先保证最终一致,不用追求实时同步。比如更新评论内容或点赞数时:
先更新 MySQL 底库,确认成功后删除 Redis 缓存;本地缓存则靠「定时校验 + 主动失效」 双保险 — 每 10 分钟拉取 Redis 的最新数据对比,不一致就更新,同时如果评论有修改,也会主动删除对应的本地缓存。
这样一来,就算有极短时间的旧数据,用户刷新一下就能看到最新的,既不会影响体验,也避免了复杂的同步逻辑把系统搞复杂。
当MySQL单表数据超千万,查询就像大海捞针 — 全表扫描慢到崩溃。这时候就得分库分表。
通常有三种分表策略:
适用于热点分散场景,比如普通内容评论。路由公式是:tableIndex = contentId % 32,分32张表
但这招有个致命伤:爆款内容会集中在一张表,比如某热点新闻的评论占全站的80%,全挤在一张表上。
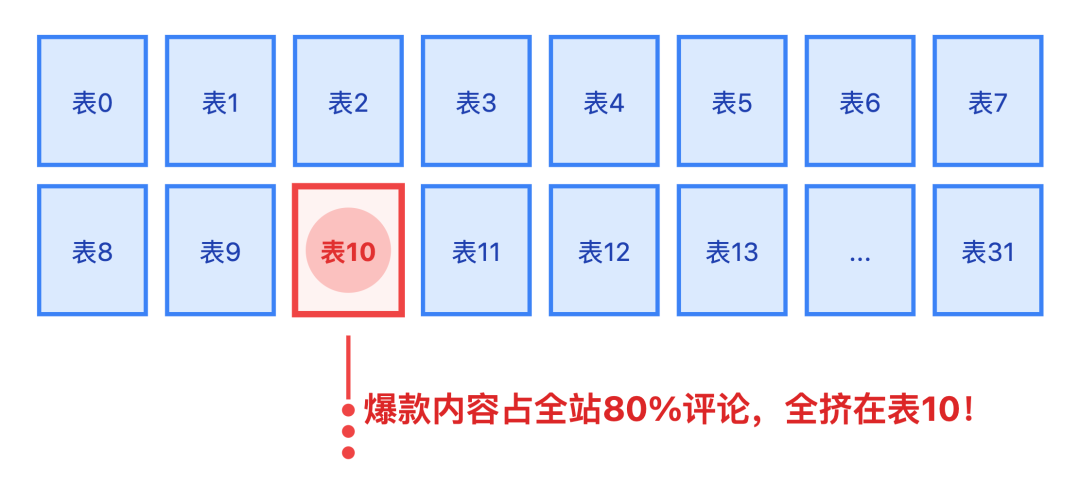
查询时就像「火车站窗口买春运火车票」,排到天荒地老。
适用于时间衰减型内容比如新闻、短视频评论,刚出来时火爆,旧的内容就没人看了。路由公式是:tableIndex = (contentId%8) + (month%4),共32张表
比如3月的数据在 (0-7)+0=0-7 表,4月在 (0-7)+1=8-15 表,查去年的评论直接查对应月份的表,不用扫全量。

但跨月数据查询要多表聚合,需要业务层处理。
对于热点数据,我们预设10张热点表,通过监控触发数据迁移。适用于有极端热点风险,比如明星账号、重大事件评论。实现逻辑分为三步:

这三种策略各有侧重,至于分库分表该用哪种策略,后续在数据层我具体介绍。
不过分表的核心难题不是选策略,而是无感知迁移 — 用户正在发评论,你突然说"系统维护中",体验直接崩。正确姿势是"双写+校验",分为四个阶段:
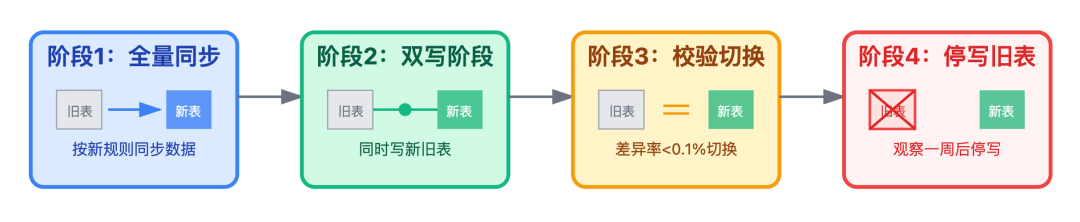
阶段1:全量同步
先把旧表数据按新规则同步到分表;
阶段2:双写阶段
然后应用层同时写旧表和新表;
阶段3:校验切换
写个脚本对比新旧表数据 — 当差异率低于 0.1%,说明双写逻辑没问题。这时候把读流量切到新分表
阶段4:停写旧表
观察一周稳定后,停写旧表,完成迁移。
四个阶段下来,全程零停机,用户完全没感知。
搞定了存储、缓存和分库分表这些积木块,接下来就得看看怎么把它们搭成高楼大厦了。架构不是一次设计管三年,而是跟着业务迭代,这里我总结了三个演进阶段:
由「单应用服务 + 单MySQL + 本地缓存 Caffeine」的架构组成,这个架构特别适合业务初期,比如产品刚上线、日活在 10 万以内,评论功能只需要基础的「发、查、点赞」的场景。
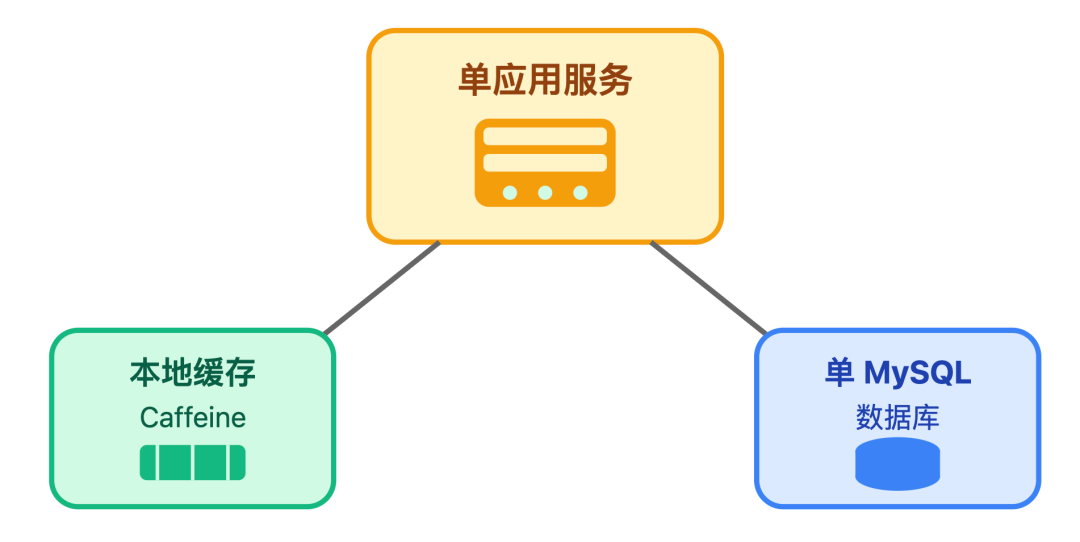
它的优点很明确:开发快、运维简单、成本低。但一旦用户量往上涨,问题就来了:

当单应用撑不住时,第一步往往是分家。
核心思路是把「发评论」和「点赞互动」拆成两个独立服务,避免互相拖累。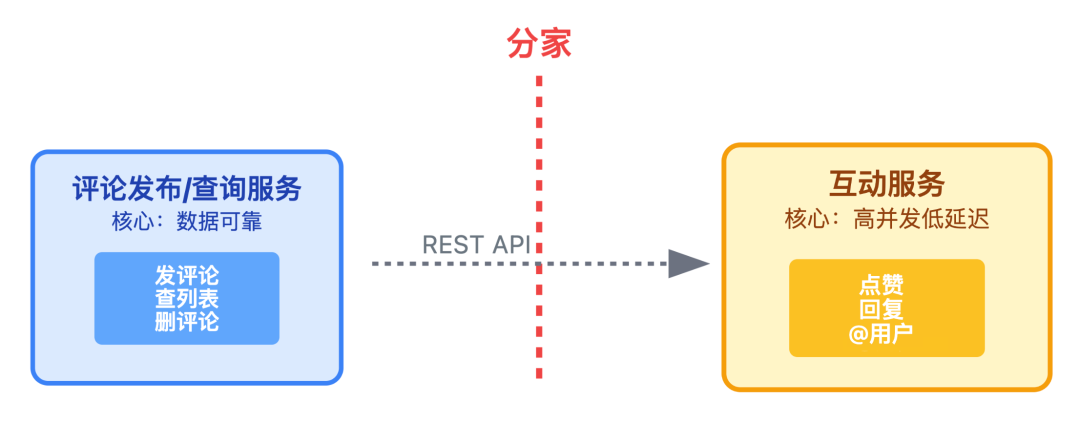
服务之间怎么配合?用 REST API 对接就行。比如用户点赞后,互动服务会调用评论服务的接口,同步更新评论的总点赞数。
数据层也要跟着优化:
这个架构解决了查询性能和出故障 "一锅端" 的问题,支撑起了10-80万的日活场景,但随着业务规模扩大,新的问题又来了:跨服务调用延迟、数据一致性、代码冗余....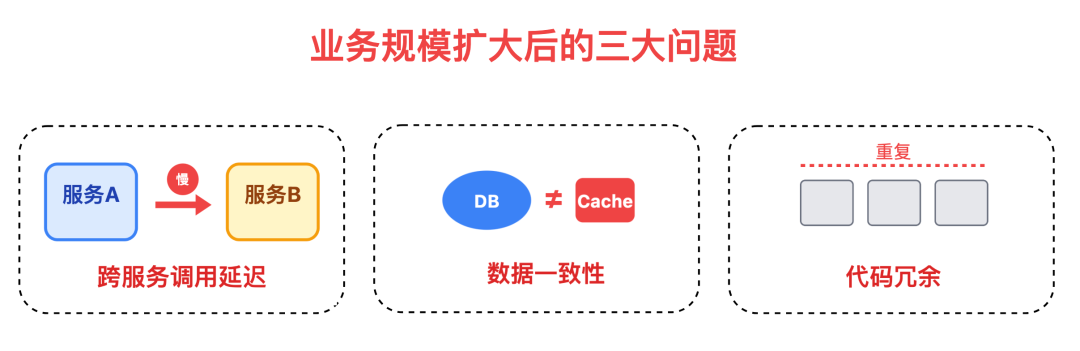
尤其是单库写入 QPS 超 5000 后,就得拆单库、往分布式架构走了。
分布式架构是支撑「百万级用户实时互动」的最终形态,它的思路很简单:把系统拆成几个独立又能配合的层级,形成「分层防御」的架构体系。
作为用户请求进入系统的第一关,接入层的核心作用是「过滤无效流量、精准分发请求」。
首先是 LVS+Nginx 负载集群
2 台 LVS 物理机负责 4 层 TCP 流量分发,把请求均匀转发到 4 台 Nginx 服务器;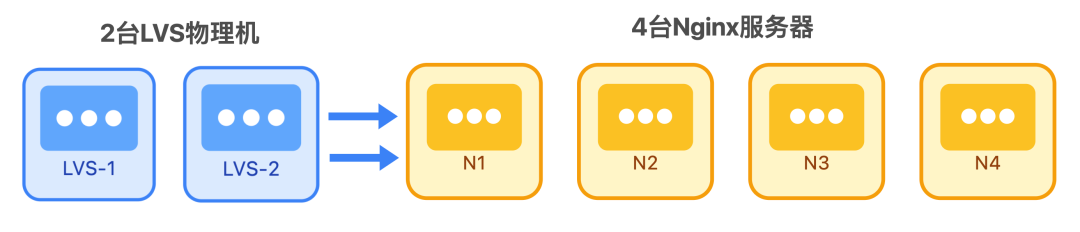
Nginx 再基于 7 层 HTTP 协议做精细化路由 — 根据内容 ID 识别热点内容,直接将这类请求导向专用集群,防止单集群因流量集中而过载。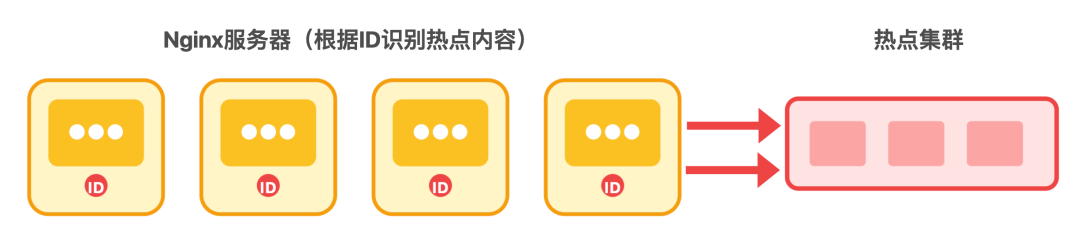
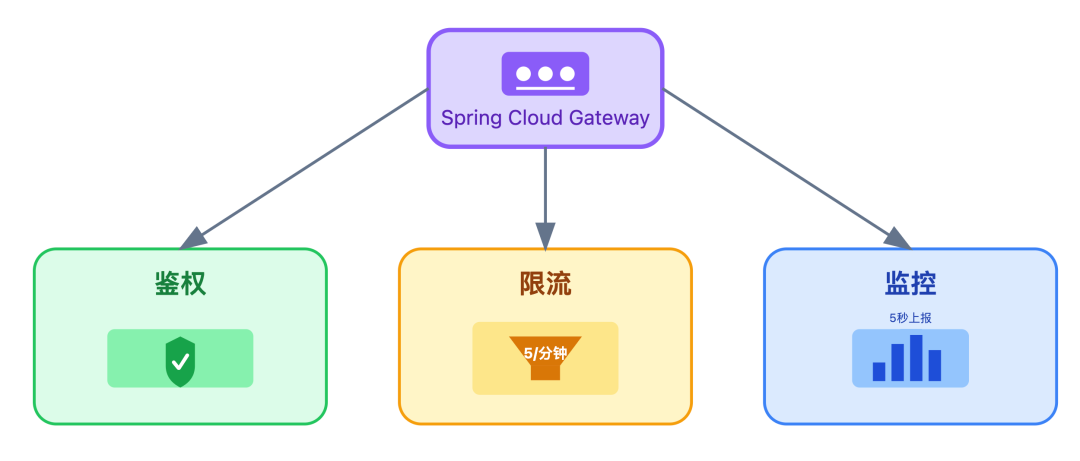
其次是自研网关
基于 Spring Cloud Gateway 开发,集成了三大核心能力:
这一层是业务能力的核心载体,按「谁擅长谁来干」的原则,拆成了 4 个微服务:
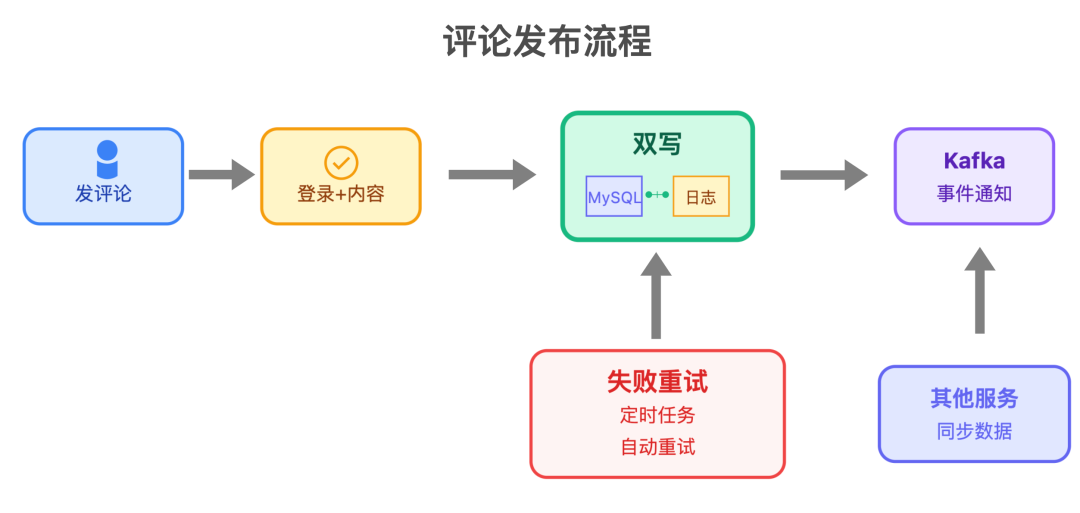
1. 评论发布服务
专门管发评论、删评论,设计上最在意「数据不丢」,比如用「双写 + 日志」的方式:
2. 评论查询服务
负责加载评论列表、查评论详情,重点抓「查询快」,搞了多级缓存:
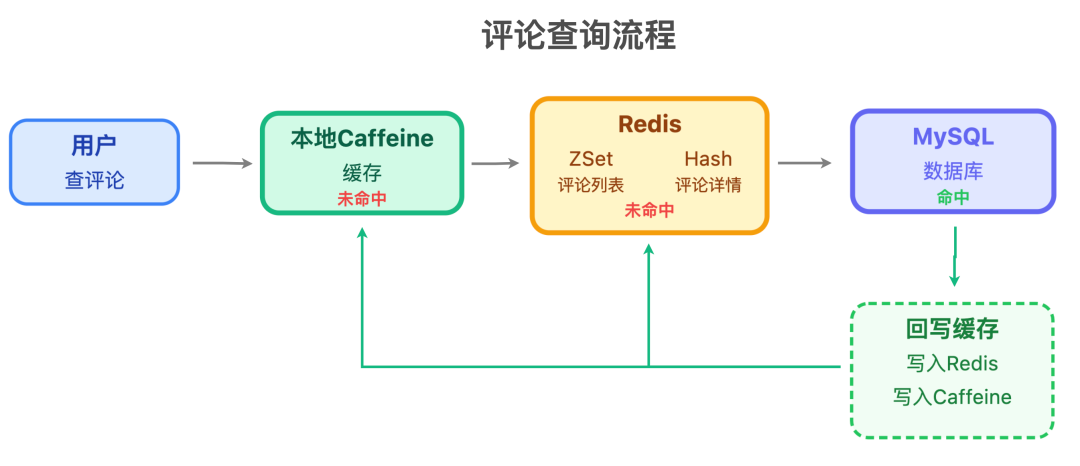
还加了缓存预热和自动降级机制,比如 Redis 故障了,就直接查 MySQL,保证用户能看到评论。
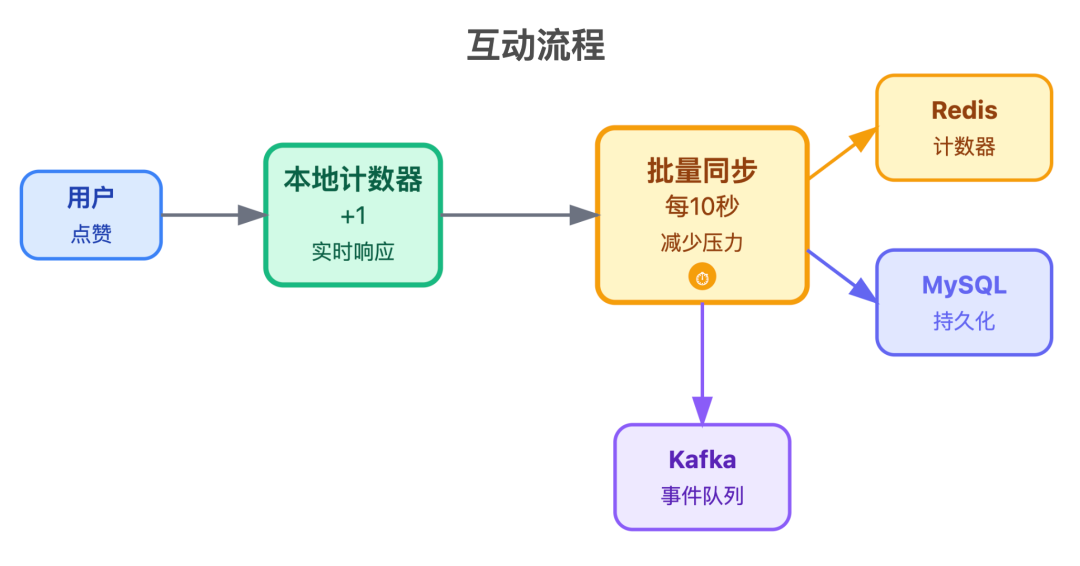
3. 互动服务
管点赞、回复、@用户,核心需求是「扛高并发」,所以点赞数用了「本地计数器 + 批量同步」的策略:
4. 内容审核服务
负责过滤敏感词、识别垃圾评论,用了「预审核 + 人工复核」的机制:
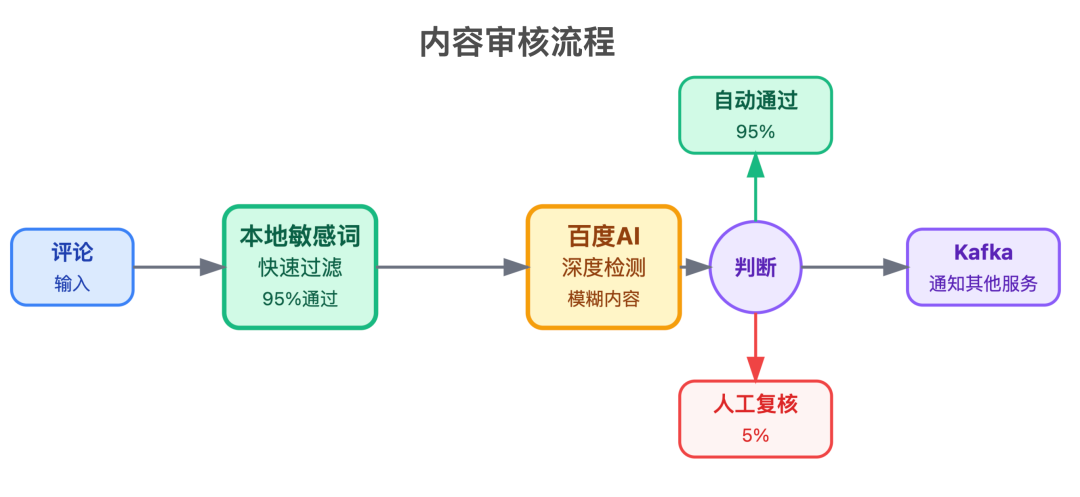
这样既保证了审核效率,又能减少误判。
这一层的核心目标是:实现「热数据快取」、「全量数据可靠」和「冷数据低成本」。因此会根据数据特性匹配存储工具,具体通过以下三类存储方案落地:
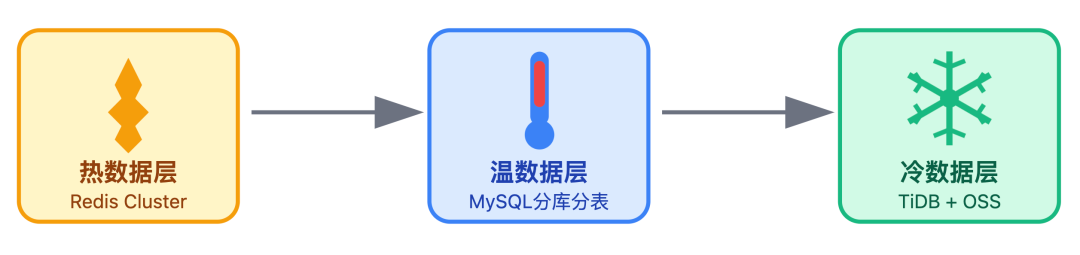
1. Redis Cluster
Redis 集群主要存储三类核心数据以支撑高频读写:
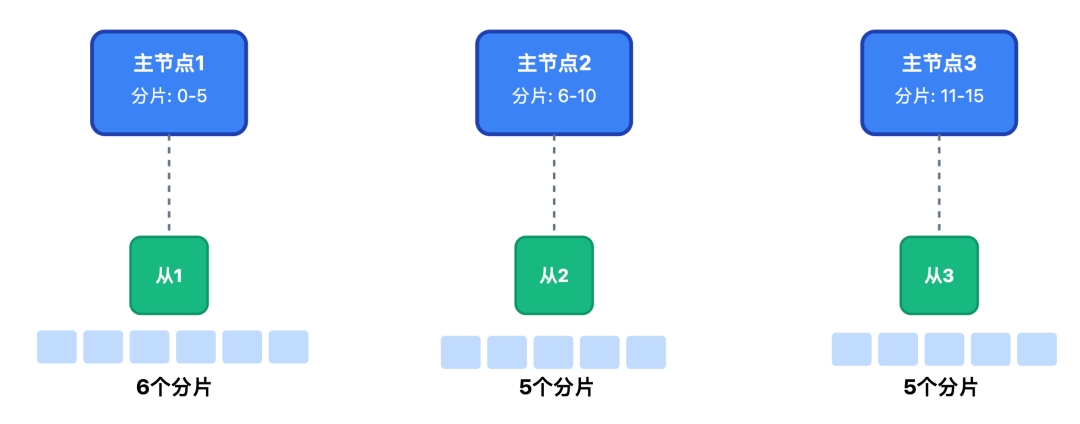
集群配置上,一共设置 16 个分片,采用 3 主 3 从架构,整体包含 48 个节点,每个节点配置 8G 内存。
另外,针对嵌套回复场景,我们摒弃了复杂的树形存储,改用「父 ID + 层级路径」的设计,比如「1001.2003.3005」,能直观看出是某条评论的三级回复。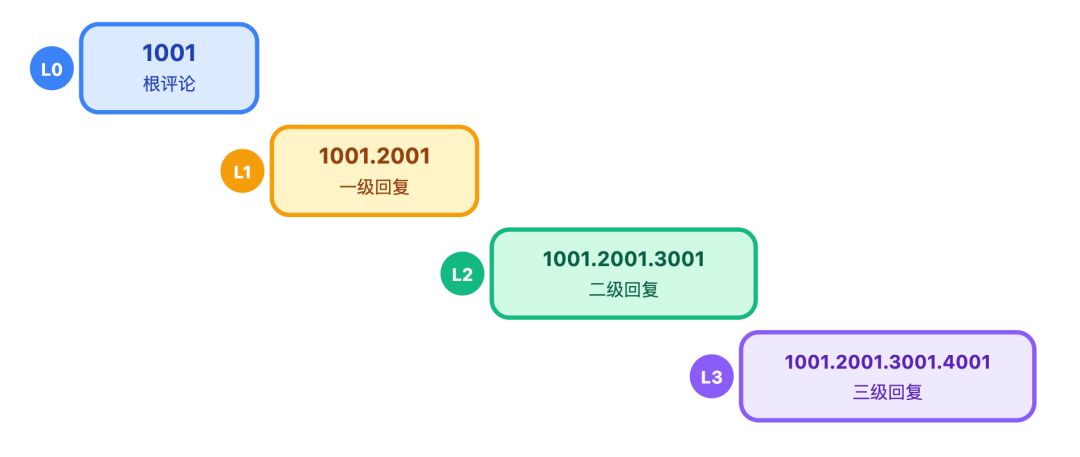
查询时通过 Redis 的 HMGET 命令批量拉取数据,再由前端自行组装层级关系,大幅降低了后端处理复杂度。
2. MySQL分库分表
我们采用「基础分片 + 热点隔离」的分片策略,既应对常规千万级数据查询,也化解爆款内容压力:按 content_id%8 分 8 个库;每个库搭配 1 主 2 从架构;再按 user_id%4 分 4 张表,共 32 张表;
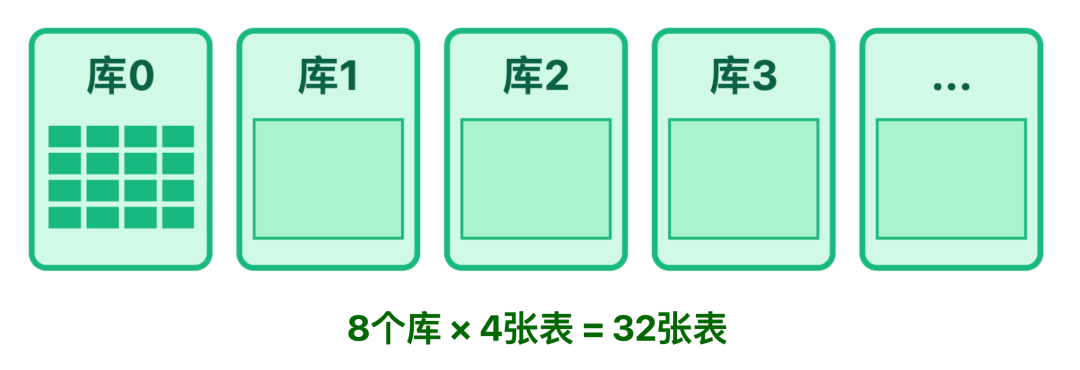
此外,针对爆款内容评论集中的问题,我们预设 20 张热点表:当检测到某 content_id 5 分钟新增评论超 1 万时,通过 Canal 监听 Binlog 同步数据至热点表,避免单表压力过载。
3. 冷数据处理
中间件层的核心作用是解决系统里的共性问题。
**先说 Kafka,它的作用是流量削峰。**比如瞬时10万写QPS,Kafka可将其缓冲为2万/秒的匀速流量,避免MySQL因突发压力过载。

发评论时,先同步写入MySQL确保数据可靠,再将非实时需求封装成「评论发布事件」,异步发送到Kafka队列。
主要存储三类关键消息:
再看 Elasticsearch,它是负责全文检索的工具,专门支撑「搜商品评价」这类场景。
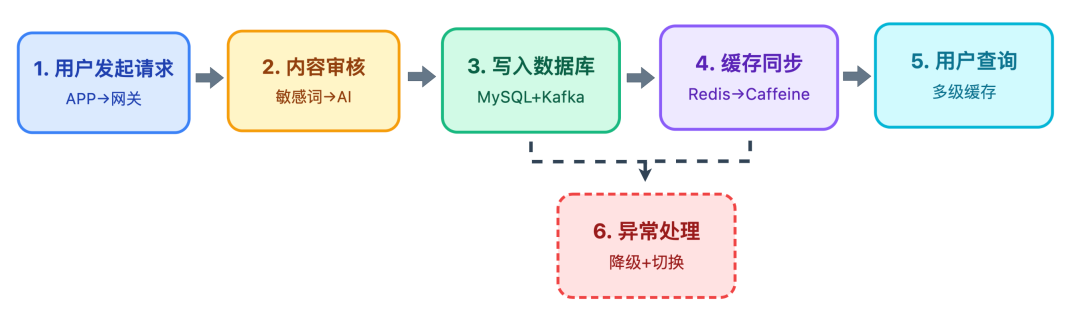
由此,我们可以总结出一条用户发评论的完整链路:
用户发起请求:APP 提交评论内容,请求经 LVS → Nginx → 网关,转发至评论发布服务。
内容审核:发布服务调用审核服务,先过本地敏感词库,未命中则调百度 AI,通过后进入发布流程。
写入数据库:发布服务按分表规则写入 MySQL,记录事务日志,同时发comment-publish 事件至 Kafka。
缓存同步:查询服务消费 Kafka 事件,更新 Redis ZSet(列表)和 Hash(详情),热点内容同步至本地 Caffeine。
用户查询评论:请求经网关至查询服务,依次查 Caffeine → Redis → MySQL,返回结果给用户。
异常处理:主库故障时自动切从库,Redis 故障时降级至 MySQL + 本地缓存,确保核心功能可用。
整个链路从请求发起至数据返回,延迟能控制在 500ms 以内,用户几乎感觉不到等待,支撑百万级用户同时互动完全没问题。
架构搭好了,并不意味着可以高枕无忧。高可用不是不出故障,而是故障时用户无感。以下三个方案可让「系统秒级止血,快速恢复」。

缓存最怕「一崩全崩」,比如 Redis 里大量 Key 同时过期,所有请求都冲去数据库,直接就垮了。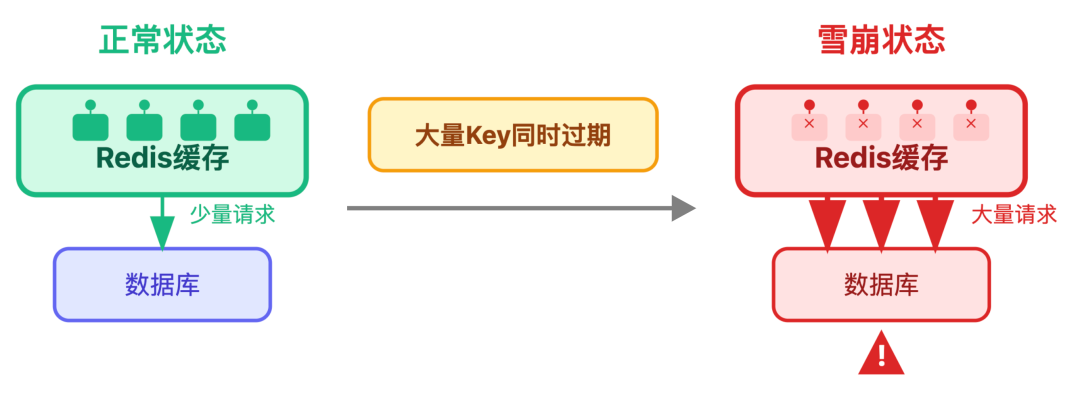
我们前面已经介绍过「本地缓存 + Redis」的组合拳:就算 Redis 挂了,本地缓存能先扛一波;
然后Redis 给每个 Key 的过期时间加 ±10 的随机值,避免集体过期。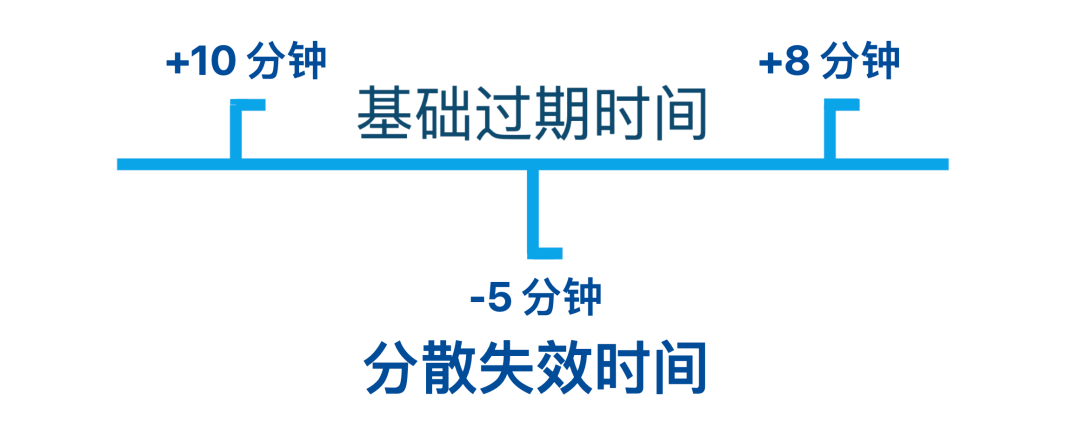
相当于提前筑了个临时堤坝,就算 Redis 出问题,用户也不会直接面对「评论加载失败」,给修复留足时间。
MySQL 和 Redis 要是出问题,整个评论功能都得停,所以要给它们做了多重保障:
有时候故障比较复杂,修复需要时间,这时候不能硬扛,得「舍小保大」。
我们按压力等级预设降级策略,通过按钮实现一键降级:


这套模式就像手机快没电时的低电量模式 — 先关后台保核心功能,总比直接关机强。
故障恢复的核心思路就是不求「零故障」,但求故障发生时,用户没感觉。
看到这里,你可能觉得技术细节了,但核心总结下来就三句话:
先分清是电商评价还是直播弹幕 — 前者丢一条用户会投诉,要重「数据不丢」;后者漏几条用户无感知,要重「并发能扛」。
赞数延迟 3 秒用户无感,但评论加载失败 3 次会直接走人。不用死磕「全量实时同步」,冷评慢一点没关系,多数用户更在意核心体验。
热点隔离预留独立集群、多副本架构提前搭好,这些平时占资源的设计,到流量峰值时就是「救命稻草」。多想想「100 万人点赞怎么办」「MySQL 宕机咋应对」,想透这些,系统才抗揍。
最后牛哥想说技术是工具,业务才是根,偶尔接受一些不完美很正常。

