
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
Go语言采用显式错误处理策略,通过error接口和多返回值处理常规错误。error是Go语言的内置接口,任何实现了Error()方法的类型都可以作为error使用。函数通常将error作为最后一个返回值,调用者必须主动检查并处理。
这种设计理念强调错误是程序正常流程的一部分,需要开发者主动处理。error机制用于处理可预期的错误,如文件不存在、网络超时等,这些错误是程序正常流程的一部分,不应该导致程序崩溃。
// error接口定义和自定义错误类型
type error interface {
Error() string
}
type ValidationError struct {
Field string
Message string
}
func (e ValidationError) Error() string {
return fmt.Sprintf("%s: %s", e.Field, e.Message)
}
// 错误处理示例
func divide(a, b float64) (float64, error) {
if b == 0 {
return 0, fmt.Errorf("除数不能为0")
}
return a / b, nil
}
func processUser(name string) error {
if name == "" {
return fmt.Errorf("处理用户失败: %w", ValidationError{
Field: "name",
Message: "用户名不能为空",
})
}
return nil
}
func handleUserRequest(name string) error {
if err := processUser(name); err != nil {
return fmt.Errorf("用户请求处理失败: %w", err)
}
return nil
}
// 使用示例
func main() {
// 基本错误处理
result, err := divide(10, 0)
if err != nil {
fmt.Printf("除法错误: %v\n", err)
return
}
// 错误传播
if err := handleUserRequest(""); err != nil {
fmt.Printf("用户处理失败: %v\n", err)
return
}
}panic机制用于处理不可恢复的严重错误,如数组越界、空指针解引用等。panic会立即停止当前函数执行,并沿着调用栈向上传播,直到被recover捕获或程序终止。
recover机制用于捕获panic,只能在defer函数中使用。recover()返回panic的值,如果没有panic则返回nil。通过recover可以避免程序因panic而崩溃,实现优雅的错误恢复。
panic通常在以下场景触发,这些场景在面试中经常被问到:
// panic触发示例
func triggerPanic() {
// 数组越界
arr := []int{1, 2, 3}
fmt.Println(arr[10]) // panic: runtime error: index out of range
// 空指针解引用
var ptr *int
fmt.Println(*ptr) // panic: runtime error: invalid memory address
// 不安全的类型断言
var i interface{} = "hello"
num := i.(int) // panic: interface conversion: interface {} is string, not int
// 手动触发
panic("手动触发的panic")
}panic会沿着调用栈向上传播,直到被recover捕获或程序终止。recover用于捕获panic,只能在defer函数中使用。recover()返回panic的值,如果没有panic则返回nil。
// panic传播示例
func level3() {
panic("level3 panic")
}
func level2() {
level3()
}
func level1() {
defer func() {
if r := recover(); r != nil {
fmt.Printf("在level1中恢复panic: %v\n", r)
}
}()
level2()
}
// 带返回值的recover
func safeDivide(a, b int) (result int, err error) {
defer func() {
if r := recover(); r != nil {
err = fmt.Errorf("除法操作panic: %v", r)
}
}()
result = a / b
return
}在Go语言中,错误处理遵循以下原则:
// 良好的错误处理示例
func readConfig(filename string) ([]byte, error) {
data, err := os.ReadFile(filename)
if err != nil {
return nil, fmt.Errorf("读取配置文件失败: %w", err)
}
if len(data) == 0 {
return nil, fmt.Errorf("配置文件为空")
}
return data, nil
}
// 使用示例
func main() {
config, err := readConfig("config.json")
if err != nil {
log.Printf("配置读取失败: %v", err)
return
}
// 处理配置...
}panic的使用需要遵循特定原则,这些原则在面试中经常被考察:
// 包内部使用panic,公共API提供安全接口
func internalProcess(data []int) {
if len(data) == 0 {
panic("数据不能为空")
}
// 处理数据...
}
// 公共API提供安全接口
func ProcessData(data []int) error {
defer func() {
if r := recover(); r != nil {
return fmt.Errorf("数据处理失败: %v", r)
}
}()
internalProcess(data)
return nil
}Go语言的defer机制是一种延迟执行机制,用于确保函数调用在当前函数返回前执行。defer语句按照后进先出(LIFO)的顺序执行,参数在defer语句执行时立即求值,但函数调用延迟到函数返回前执行。defer常用于资源清理、解锁、关闭文件等操作,是Go语言资源管理的重要工具。
func basicDefer() {
defer fmt.Println("最后执行")
defer fmt.Println("倒数第二执行")
fmt.Println("正常执行")
return
}
// 输出顺序:
// 正常执行
// 倒数第二执行
// 最后执行多个defer出现的时候,它会把defer之后的函数压入一个栈中延迟执行,也就是先进后出(LIFO),最后注册的defer最先执行。这种执行顺序确保了资源清理的正确性,后申请的资源先释放。
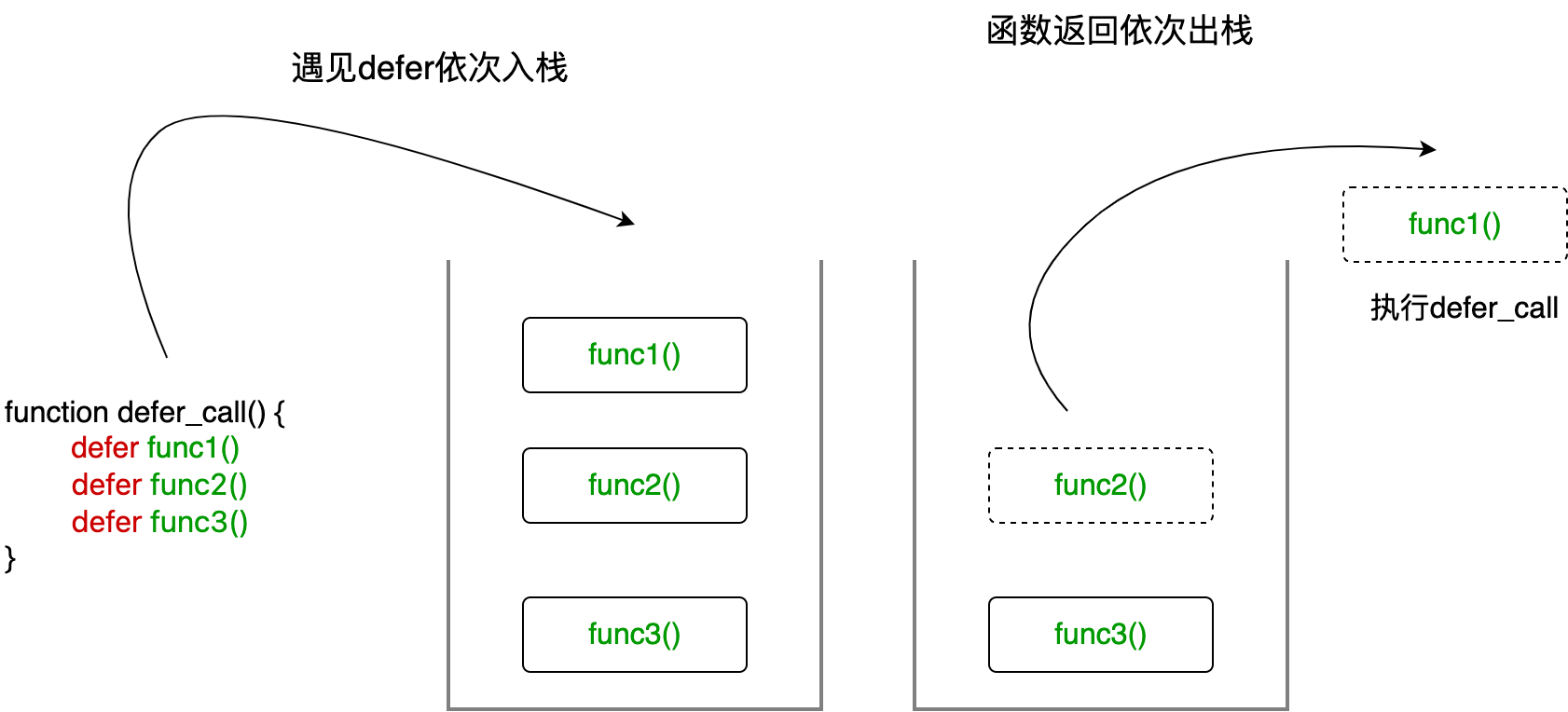
defer的参数在defer语句执行时立即求值,即使函数调用延迟执行。这意味着如果defer的参数是变量,那么参数的值在defer语句执行时就已经确定,而不是在defer函数实际执行时确定。这个特性在闭包和变量捕获中特别重要。
命名返回值的情况:
func returnWithDefer() (a int) {
defer func() {
a = 3 // 修改命名返回值
}()
return 1 // 实际返回3,不是1
}
func main() {
fmt.Println(returnWithDefer()) // 输出:3
}匿名返回值的情况:
func returnWithoutDefer() int {
var a int
defer func(a int) {
a = 10 // 无法修改匿名返回值
}(a)
return 2 // 返回2
}
func main() {
fmt.Println(returnWithoutDefer()) // 输出:2
}值传递vs引用传递的情况:
// 值传递:defer无法修改
func valuePass() int {
a := 1
defer func(a int) {
a = 10 // 修改的是副本,不影响原值
}(a)
return a // 返回1
}
// 引用传递:defer可以修改
func referencePass() int {
a := 1
defer func(a *int) {
*a = 10 // 通过指针修改原值
}(&a)
return a // 返回10
}
// 闭包捕获:defer可以修改
func closureCapture() int {
a := 1
defer func() {
a = 10 // 闭包直接捕获变量,可以修改
}()
return a // 返回10
}
func main() {
fmt.Println("值传递:", valuePass()) // 输出:1
fmt.Println("引用传递:", referencePass()) // 输出:10
fmt.Println("闭包捕获:", closureCapture()) // 输出:10
}执行过程分析:
defer和return的执行顺序是Go语言中的一个重要概念。return语句的执行是非原子性的,它包含两个步骤:
return的操作步骤:
defer的操作步骤:
func deferAndReturn() int {
defer func() {
fmt.Println("defer执行")
}()
fmt.Println("函数开始")
return func() int {
fmt.Println("return中的函数执行")
return 100
}()
}
func main() {
result := deferAndReturn()
fmt.Printf("最终返回值: %d\n", result)
}
// 输出:
// 函数开始
// return中的函数执行
// defer执行
// 最终返回值: 100执行过程分析:
这个执行顺序解释了为什么defer可以修改命名返回值,因为defer在返回值赋值之后、RET指令之前执行。
defer在panic发生时仍然会执行,这为错误恢复提供了机制。
defer遇见panic:
func deferWithPanic() {
defer fmt.Println("defer执行,即使有panic")
panic("发生panic")
fmt.Println("这行不会执行")
}
// 输出:
// defer执行,即使有panic
// panic: 发生panicdefer包含panic:
func deferContainsPanic() {
defer func() {
panic("defer中的panic")
}()
fmt.Println("正常执行")
}
// 输出:
// 正常执行
// panic: defer中的panicdefer与recover结合:
func deferWithRecover() {
defer func() {
if r := recover(); r != nil {
fmt.Printf("恢复panic: %v\n", r)
}
}()
panic("测试panic")
}
// 输出:
// 恢复panic: 测试panic
