
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
多个goroutine对同一个map进行写操作会触发panic,这种panic属于fatal error,无法被defer recover捕获。这是因为Go语言在map的并发写操作检测到时会直接触发系统级的fatal error,这种错误是程序无法恢复的严重错误。
在Go语言中,错误处理分为三个层次:普通错误(Error)、异常(Panic)和致命错误(Fatal Error)。map的并发写操作触发的就是第三种错误。
| 错误类型 | 特点 | 处理方式 | 程序行为 | 示例 |
|---|---|---|---|---|
| 普通错误(Error) | 可预期、可处理 | if err != nil | 程序继续运行 | 文件不存在、网络连接失败 |
| 异常(Panic) | 可恢复、可捕获 | defer recover | 程序可恢复 | 数组越界、空指针解引用 |
| 致命错误(Fatal Error) | 不可恢复、不可捕获 | 无法处理 | 程序直接退出 | map并发写、内存访问违规 |
处理map并发访问的正确方式应该是使用互斥锁、sync.Map或channel。通过互斥锁可以保护map的访问,使用sync.Map可以获得并发安全的map实现,而使用channel则可以将map的访问封装在单独的goroutine中。
不要试图通过defer recover来捕获map并发写的panic。这种做法不仅无法解决问题,反而会掩盖潜在的问题,导致程序在错误的状态下继续运行。在开发阶段就做好并发控制,避免map的并发写操作,使用go vet等工具检查代码中的并发问题,在测试阶段进行并发测试,及早发现问题。
在Go语言中,除了使用mutex,还有以下几种方式可以实现共享变量的安全访问:使用channel将共享变量的访问封装在单独的goroutine中,使用原子操作(atomic包)进行原子性操作,使用信号量(semaphore)实现互斥访问,使用sync.Map实现并发安全的map。
在实际开发中,我们需要根据具体场景选择最合适的并发控制方式。想象一下这样的场景:你有一个共享的银行账户,多个客户同时要存取钱。如果不用任何保护机制,账户余额就会出错。我们需要不同的"保安"来保护这个账户。
方式一:Channel封装(推荐)
Channel方式就像把银行账户交给一个专门的"账户管理员"。所有客户不能直接操作账户,而是通过管理员来存取钱。管理员一次只处理一个请求,确保账户安全。
这种方式符合Go语言的核心理念:"不要通过共享内存来通信,而要通过通信来共享内存"。适合需要复杂同步逻辑的场景。
方式二:原子操作
原子操作就像银行使用特殊的"原子计数器",每次操作都是不可分割的。比如存款时,读取余额、计算新余额、写入新余额这三个步骤在CPU层面是一个指令完成的。
性能最好但功能有限,只能用于基本类型(int32、int64等),适合简单的计数器场景。
方式三:信号量
信号量就像银行限制同时进入的人数。比如最多允许3个客户同时操作账户,超过的客户需要排队等待。
可以精确控制并发数量,适合需要限制并发数的场景,但实现相对复杂。
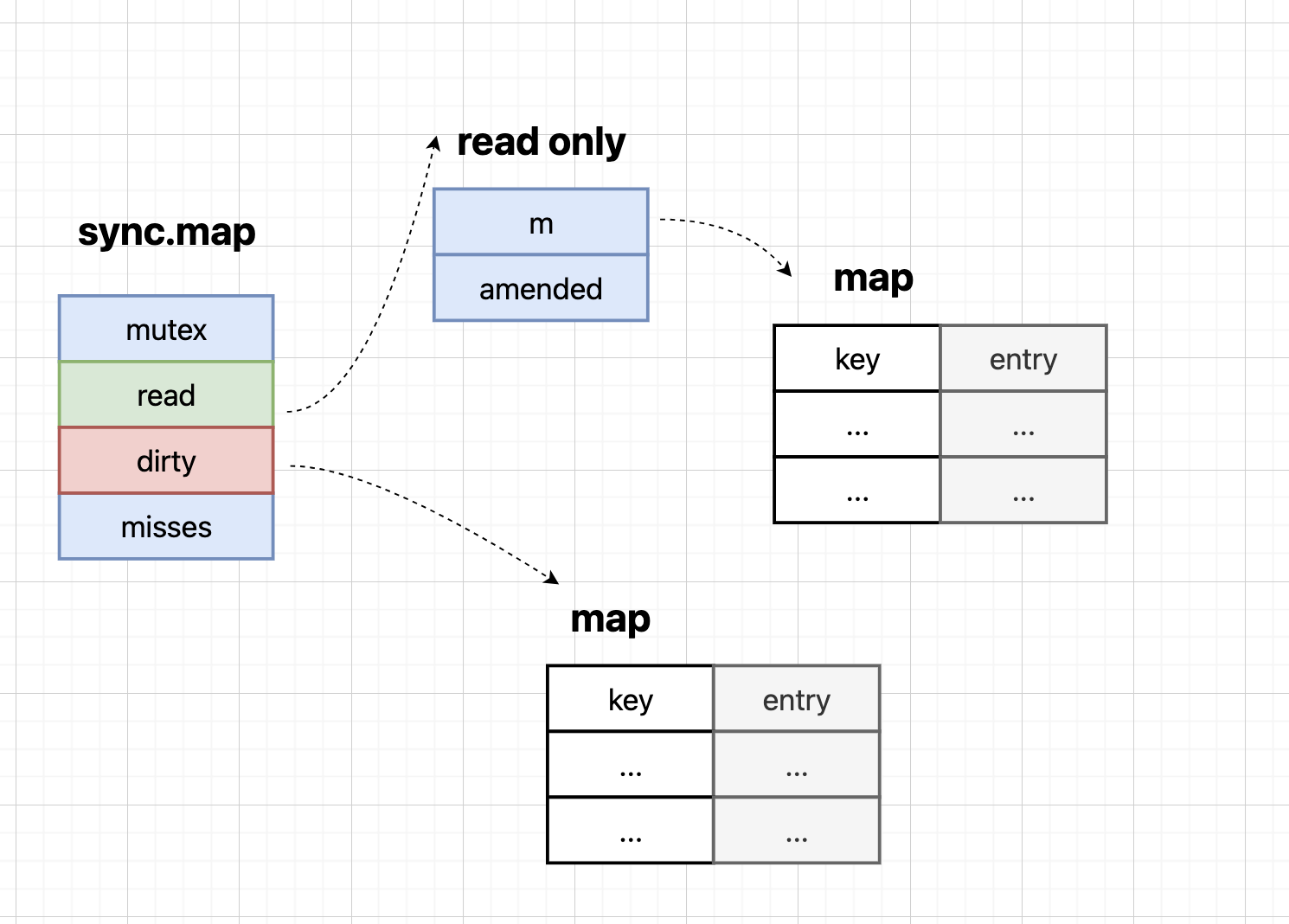
方式四:sync.Map
sync.Map就像银行提供的"并发安全保险箱",专门为并发访问设计。使用简单,但性能一般,适合读多写少的场景。
Channel封装将共享变量封装在单独的goroutine中,通过channel进行读写操作,符合Go语言的"不要通过共享内存来通信,而要通过通信来共享内存"的设计理念,适合需要复杂同步逻辑的场景。原子操作使用sync/atomic包提供的原子操作,性能最好但功能有限,适合简单的计数器等场景,只能用于基本类型的操作。信号量使用semaphore控制并发访问,可以精确控制并发数量,适合需要限制并发数的场景,但实现相对复杂。sync.Map是Go 1.9后提供的并发安全的map实现,使用简单但性能一般,适合读多写少的场景,不需要额外的同步机制。
下面是一些具体的使用示例:
1. Channel封装示例:
// SafeCounter 使用channel封装的线程安全计数器
type SafeCounter struct {
value int
ch chan int
}
// NewSafeCounter 创建新的安全计数器
func NewSafeCounter() *SafeCounter {
counter := &SafeCounter{
ch: make(chan int),
}
go counter.run() // 启动管理协程
return counter
}
// run 管理协程:处理所有读写请求
func (c *SafeCounter) run() {
for {
select {
case c.ch <- c.value: // 响应读取请求
case c.value = <-c.ch: // 响应写入请求
}
}
}
// Get 获取当前值
func (c *SafeCounter) Get() int {
return <-c.ch
}
// Set 设置新值
func (c *SafeCounter) Set(value int) {
c.ch <- value
}2. 原子操作示例:
import "sync/atomic"
// AtomicCounter 使用原子操作的计数器
type AtomicCounter struct {
value int64
}
// Increment 原子递增
func (c *AtomicCounter) Increment() {
atomic.AddInt64(&c.value, 1)
}
// Get 原子读取
func (c *AtomicCounter) Get() int64 {
return atomic.LoadInt64(&c.value)
}
// Set 原子设置
func (c *AtomicCounter) Set(value int64) {
atomic.StoreInt64(&c.value, value)
}3. 信号量示例:
import "golang.org/x/sync/semaphore"
// SemaphoreExample 使用信号量控制并发
func SemaphoreExample() {
// 创建信号量,最多允许3个并发
sem := semaphore.NewWeighted(3)
for i := 0; i < 10; i++ {
go func(id int) {
// 获取信号量
sem.Acquire(context.Background(), 1)
defer sem.Release(1) // 释放信号量
// 执行任务
fmt.Printf("Task %d executing\n", id)
time.Sleep(time.Second)
}(i)
}
}4. sync.Map示例:
import "sync"
// SyncMapExample 使用sync.Map
func SyncMapExample() {
var m sync.Map
// 存储数据
m.Store("key1", "value1")
m.Store("key2", "value2")
// 读取数据
if value, ok := m.Load("key1"); ok {
fmt.Println("key1:", value)
}
// 删除数据
m.Delete("key2")
// 遍历数据
m.Range(func(key, value interface{}) bool {
fmt.Printf("key: %v, value: %v\n", key, value)
return true
})
}实际开发建议:
原子操作是一组不可中断的指令序列,由底层硬件直接支持。在Go语言中,原子操作通过sync/atomic包提供实现。该包主要提供了AddT、StoreT、LoadT、SwapT和CompareAndSwapT等原子操作方法,其中T可以是int32、int64、uint32、uint64和uintptr这些基本类型。这些方法能够保证在并发环境下对共享变量的操作是原子的,不会出现数据竞争问题。
原子操作在Go语言中的应用主要体现在三个方面。
下面是一个使用原子操作实现计数器的示例:
type AtomicCounter struct {
value int64
}
func (c *AtomicCounter) Increment() {
atomic.AddInt64(&c.value, 1)
}
func (c *AtomicCounter) Get() int64 {
return atomic.LoadInt64(&c.value)
}在实际开发中,当需要实现简单的计数器或标志位时,我们应该优先考虑使用原子操作而不是互斥锁。原子操作的性能优势在简单场景下非常明显,而且代码更简洁。在实现无锁数据结构时,原子操作是必不可少的工具。虽然实现难度较大,但性能提升显著,特别是在高并发场景下。需要注意的是,原子操作虽然性能好,但功能有限。对于复杂的同步需求,还是应该使用互斥锁或channel等更高级的同步机制。
原子操作和锁虽然都可以用来保证并发安全,但它们在实现原理和使用方式上存在显著差异。原子操作直接由底层硬件支持,通过CPU的原子指令实现,而锁则是基于原子操作和信号量构建的更高层抽象。在实现相同功能时,原子操作通常具有更好的性能表现。原子操作是单个指令的互斥操作,而锁可以保护多个指令组成的临界区。从锁的类型来看,原子操作属于乐观锁,而常见的互斥锁和读写锁则属于悲观锁。
| 特性 | 原子操作 | 锁机制 |
|---|---|---|
| 实现层面 | 硬件直接支持 | 软件实现 |
| 性能表现 | 最优,无锁开销 | 相对较低,有锁竞争 |
| 功能范围 | 单个操作原子性 | 保护代码段 |
| 适用场景 | 简单计数器、标志位 | 复杂同步逻辑 |
| 锁类型 | 乐观锁 | 悲观锁 |
| 内存开销 | 最小 | 较 |
选择建议:
原子操作和锁不是互斥的关系,而是互补的。在实际项目中,我们经常需要同时使用这两种机制。理解它们的区别和适用场景,对于写出高性能的并发程序非常重要。
悲观锁:总是假设会发生冲突,在访问共享资源前先获取锁,确保独占访问。就像银行柜员在办理业务前先把窗口锁起来,防止其他人干扰。
悲观锁的特点:
乐观锁:假设冲突很少发生,直接操作资源,在提交时检查是否发生冲突。就像网上购物,先加入购物车,结算时才检查库存。
乐观锁的特点:
实际应用对比:
| 特性 | 悲观锁 | 乐观锁 |
|---|---|---|
| 加锁时机 | 访问前加锁 | 提交时检查 |
| 冲突处理 | 阻塞等待 | 重试或回滚 |
| 性能开销 | 锁竞争开销 | 冲突检测开销 |
| 适用场景 | 冲突频繁 | 冲突较少 |
| 实现复杂度 | 相对简单 | 需要版本控制 |
在实际开发中,选择使用哪种锁,关键是要理解你的应用场景。如果你的应用确实存在大量的并发冲突,那么使用Mutex这样的悲观锁是合适的。但如果你的应用主要是读操作,或者冲突确实很少发生,那么考虑使用乐观锁可能会带来更好的性能。
Mutex是典型的悲观锁实现。在Go语言中,sync包提供的互斥锁sync.Mutex和读写互斥锁sync.RWMutex都属于悲观锁。
判断依据:
代码示例:
var mutex sync.Mutex
var sharedResource int
func safeAccess() {
mutex.Lock() // 先获取锁
defer mutex.Unlock()
// 临界区:只有当前goroutine能访问
sharedResource++
}与其他锁的对比:
Mutex选择悲观锁的设计是有其道理的。在并发编程中,冲突是常态而不是例外,特别是在多核环境下。悲观锁虽然可能会带来一些性能开销,但它能提供更强的保证,让程序的行为更可预测。不过,这并不意味着乐观锁就没有用武之地。在一些特定的场景下,比如读多写少的场景,或者冲突确实很少发生的场景,乐观锁可能会带来更好的性能。Go语言中的atomic包提供的原子操作就是乐观锁的一种实现。
Go语言的互斥锁Mutex底层实现非常精巧,它通过一个32位的state字段来记录锁的状态,这个字段被分成了四个部分:Waiter(等待的goroutine数量)、Starving(是否处于饥饿状态)、Woken(是否有goroutine被唤醒)和Locked(是否已锁定)。同时,Mutex还使用了一个信号量sema来实现goroutine的阻塞和唤醒机制。
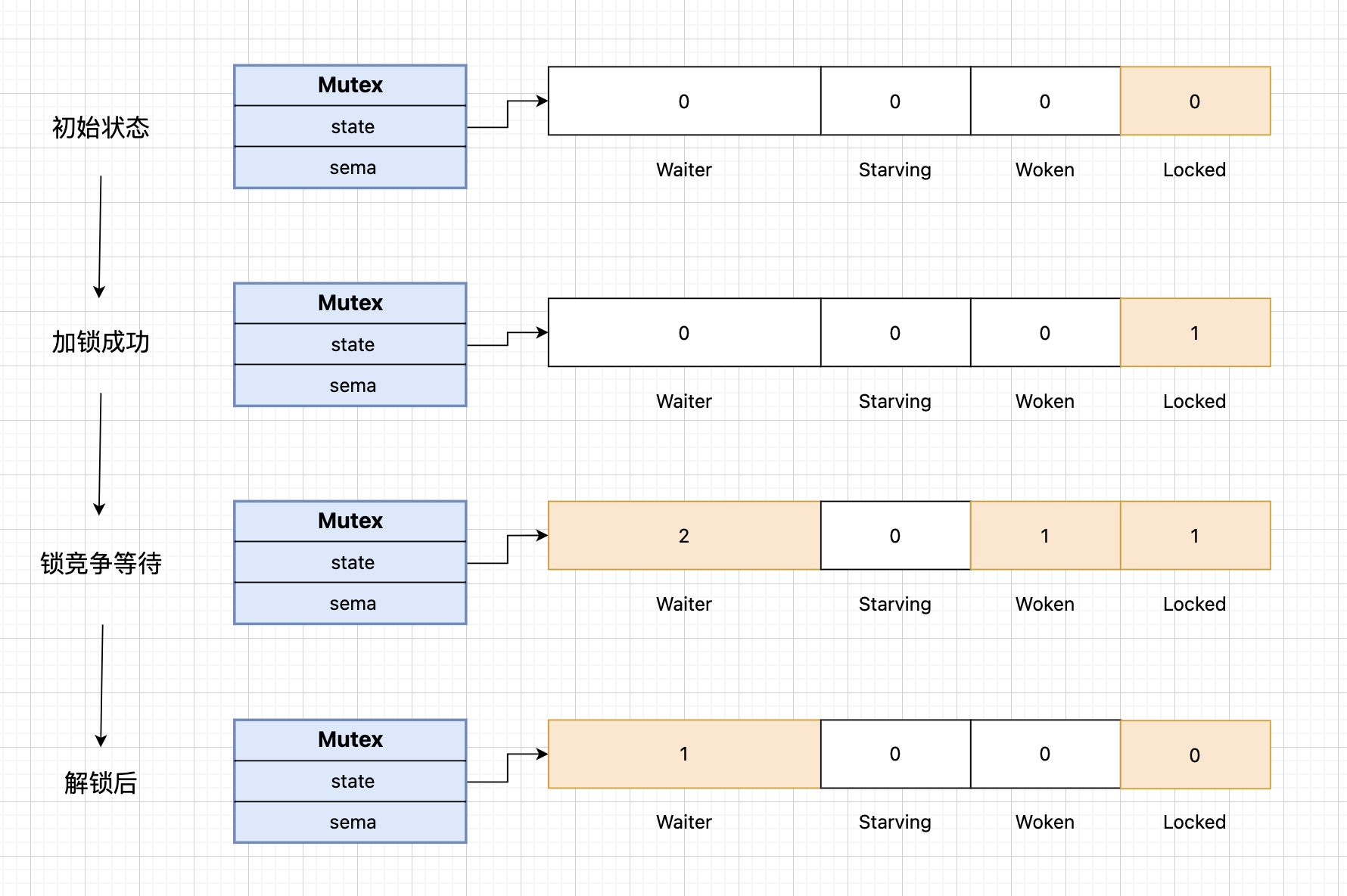
在实际使用中,Mutex的工作流程是这样的:当一个goroutine尝试获取锁时,它会先检查state字段的Locked位。如果锁未被占用,就直接获取锁;如果锁已被占用,这个goroutine就会被加入到等待队列中,等待被唤醒。
这里有个有趣的设计细节:Mutex支持两种模式,正常模式和饥饿模式。在正常模式下,新来的goroutine有机会直接获取锁,这可能会导致等待时间较长的goroutine一直获取不到锁。为了避免这种情况,Mutex引入了饥饿模式,当等待时间超过1ms时,锁会进入饥饿模式,此时新来的goroutine会被直接加入到等待队列的末尾。
说到信号量sema,它是实现goroutine阻塞和唤醒的关键。当goroutine需要等待锁时,它会通过sema进入阻塞状态;当持有锁的goroutine释放锁时,它会通过sema唤醒等待队列中的goroutine。
在实际开发中,我经常看到一些开发者对Mutex的使用存在误解。比如,有些人认为Mutex会影响性能,所以尽量避免使用它。但事实上,Mutex的设计已经考虑到了性能问题,它通过自旋等待和饥饿模式等机制来优化性能。
另一个常见的误解是关于锁的粒度。有些开发者倾向于使用一个大锁来保护所有共享资源,这可能会导致性能问题。正确的做法是根据实际需求,使用多个小锁来保护不同的资源,这样可以提高并发性能。
注意在使用Mutex时,要注意避免死锁。一个常见的死锁场景是多个goroutine以不同的顺序获取多个锁。为了避免这种情况,我们应该始终以相同的顺序获取锁。
理解Mutex的底层实现不仅有助于我们更好地使用它,也能帮助我们在遇到并发问题时进行调试。比如,当程序出现死锁时,我们可以通过查看goroutine的堆栈信息来定位问题。
Mutex有两种工作模式,就像银行有两种排队方式:
正常模式(效率优先):新来的客户可以插队,就像VIP客户优先办理。当等待时间少于1毫秒时,新请求的goroutine有机会直接获取锁,提高响应速度。
饥饿模式(公平优先):所有客户必须按顺序排队,新来的也要排在最后。当等待时间超过1毫秒时,系统自动切换到饥饿模式,确保公平性,防止某些goroutine长时间等待。
这种设计巧妙地平衡了效率和公平性:平时追求快速响应,遇到长时间等待时自动切换到公平模式,既保证了系统整体效率,又避免了"饥饿"问题。
不会。Mutex的自旋机制设计得非常精巧,它只在满足特定条件时才会允许goroutine自旋:自旋次数不超过4次、锁不处于饥饿模式、多核处理器、GOMAXPROCS大于1,且本地goroutine队列为空。这些限制确保了自旋不会过度消耗系统资源。
自旋等待是Mutex实现中的一个重要优化机制。自旋等待的本质是在CPU上执行空循环,等待锁的释放。这听起来似乎会浪费CPU资源,但Mutex通过多重限制来避免这个问题。
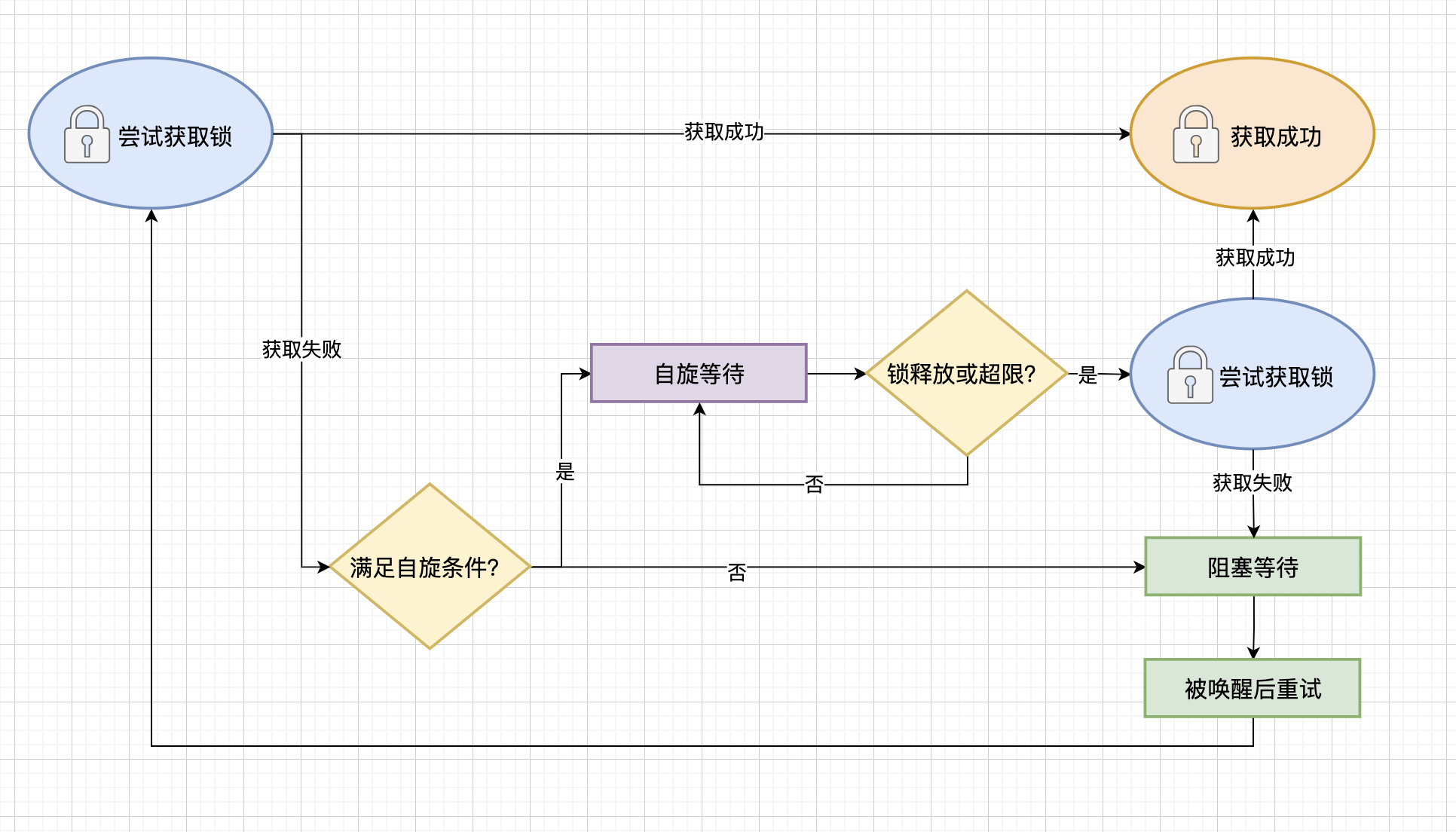
首先,自旋次数被限制在4次以内,这确保了即使自旋失败,goroutine也会很快转入等待状态。
其次,自旋只在多核环境下进行。在单核环境下,自旋是没有意义的,因为当前持有锁的goroutine无法释放锁。这个设计体现了Mutex对系统资源的尊重。
第三,自旋只在锁不处于饥饿模式时进行。在饥饿模式下,所有goroutine都必须排队等待,这避免了不必要的CPU消耗。
最后,自旋还要求本地goroutine队列为空。这个条件确保了自旋不会影响其他goroutine的执行,体现了Mutex对系统整体效率的考虑。
当自旋条件不满足时,goroutine会通过信号量进入等待状态,等待被唤醒。这种设计既保证了在合适的情况下能够快速获取锁,又避免了过度消耗系统资源。
读写锁(RWMutex)的底层实现基于互斥锁(Mutex),通过readerCount和readerWait两个计数器来协调读写操作。当readerCount为负时表示有写锁,当readerWait大于0时会阻塞写锁的获取。这种设计使得读操作可以并发进行,而写操作则需要独占锁。
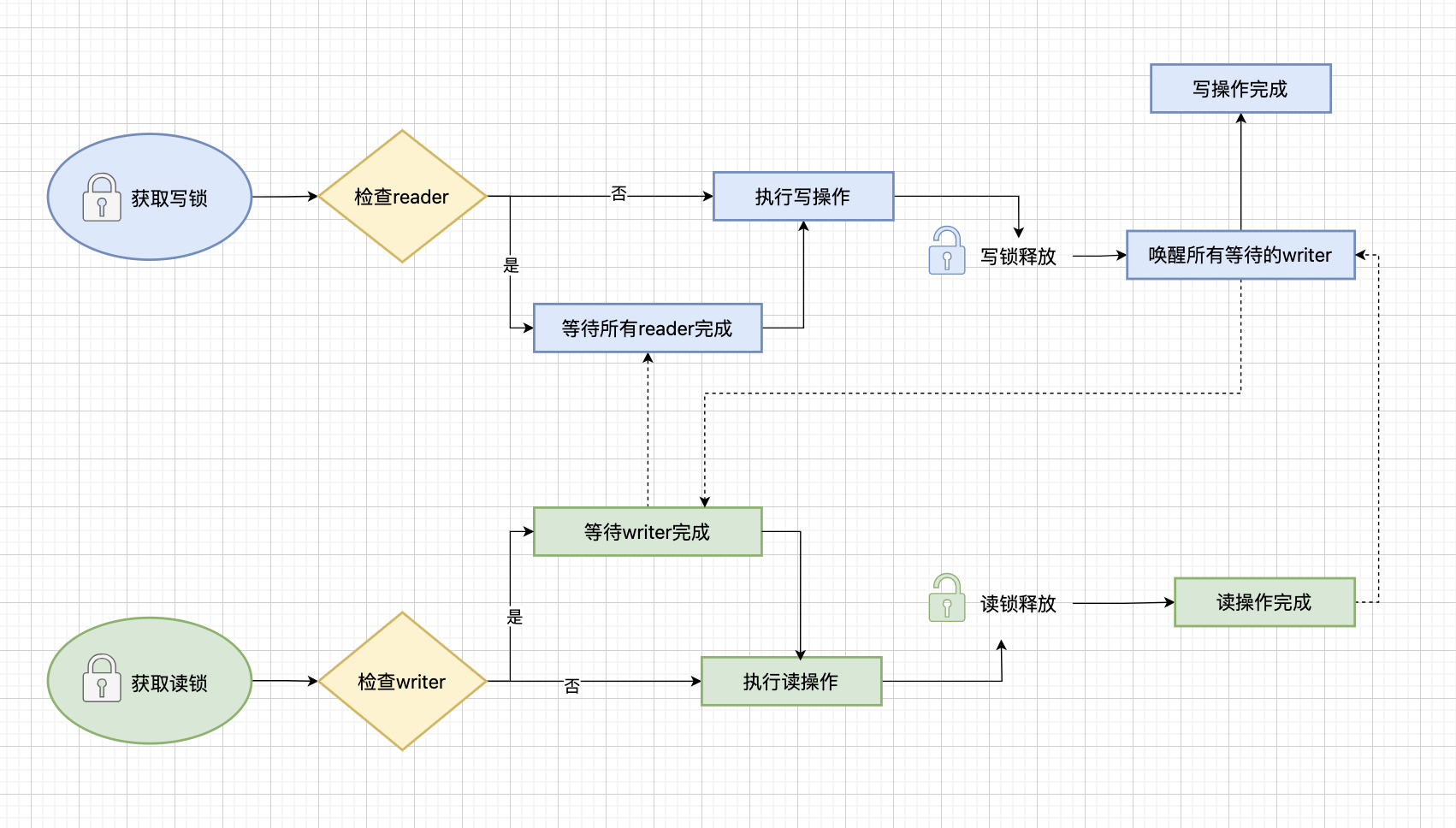
读写锁的设计体现了并发控制中的一个重要原则:读操作可以并发,写操作需要互斥。
读写锁的实现非常精巧。它复用了互斥锁作为基础,但通过额外的计数器实现了更细粒度的控制。readerCount字段不仅记录了当前读锁的数量,还通过正负值来区分是否有写锁。当readerCount为负时,表示有写锁被占用;当为正时,表示当前有多少个读锁。
readerWait字段则用于写锁的等待机制。当一个goroutine尝试获取写锁时,如果当前有读锁在运行,它会记录需要等待的读操作数量。只有当所有读操作都完成时,写锁才能被获取。
这种设计使得读写锁能够同时满足两个看似矛盾的需求:读操作的并发性和写操作的互斥性。多个goroutine可以同时持有读锁,提高了系统的并发性能;而写操作则需要等待所有读操作完成,确保了数据的一致性。
这个问题的答案取决于Mutex当前的工作模式。在正常模式下,Mutex优先考虑效率,新请求锁的goroutine具有优势,因为它正在CPU上执行,而等待中的goroutine需要被唤醒。但在饥饿模式下,Mutex则优先考虑公平性,锁会严格按照等待队列的顺序分配,新请求的goroutine会被直接加入到队列末尾。
这种自适应机制体现了Go语言在并发控制设计上的智慧:在保证系统效率的同时,也要避免某些goroutine长时间等待的问题。
在实际开发中,我们应该根据实际需求选择合适的模式。如果需要快速响应,可以选择正常模式;如果需要避免长时间等待,可以选择饥饿模式。这种自适应机制既保证了系统的整体效率,又避免了某些goroutine长时间等待的问题。
sync.Pool是Go语言提供的对象池复用机制,用于减少频繁创建销毁对象带来的GC压力。其核心特点包括:线程安全(多个goroutine可以安全地获取和归还对象)、自动清理(GC时会清理未使用的对象)、无锁设计(每个P有独立的本地缓存)和生命周期管理(对象在池中复用,减少分配开销)。
sync.Pool采用分层缓存设计,结合了本地缓存和全局缓存的优势。
分层架构:sync.Pool采用两级缓存架构,每个P(处理器)拥有独立的本地缓存,全局共享一个全局缓存。这种设计减少了锁竞争,提高了并发性能。
无锁本地缓存:每个P的本地缓存无需加锁,goroutine可以快速获取和归还对象,避免了全局锁竞争,提高了性能。
全局缓存共享:当本地缓存为空时,从全局缓存获取对象;当本地缓存满时,将对象归还到全局缓存,实现对象在不同P之间的均衡分布。
使用sync.Pool的基本步骤:定义New函数(创建新对象的工厂函数)、获取对象(调用Get()方法从池中获取对象)、使用对象(正常使用对象进行业务处理)、归还对象(调用Put()方法将对象归还到池中)和重置对象(归还前重置对象状态,避免数据污染)。
对象创建:当池中没有可用对象时,sync.Pool会调用New函数创建新对象。New函数应该返回一个零值的对象,避免数据污染。
对象复用:对象在使用完毕后归还到池中,可以被其他goroutine复用,减少频繁的内存分配和GC压力。
自动清理:GC时会自动清理池中未使用的对象,避免内存泄漏。这意味着对象池中的对象不是永久存在的,开发者不应该依赖对象的持久性。
生命周期示例:
// 定义对象池
var bufferPool = sync.Pool{
New: func() interface{} {
// 返回零值对象
return make([]byte, 0, 1024)
},
}
// 使用对象池
func processData(data []byte) []byte {
// 获取对象
buffer := bufferPool.Get().([]byte)
defer bufferPool.Put(buffer) // 确保归还
// 重置对象状态
buffer = buffer[:0]
// 使用对象
buffer = append(buffer, data...)
buffer = append(buffer, "processed"...)
return buffer
}使用sync.Pool时需要注意一些优化技巧,以充分发挥其性能优势。
对象重置:归还对象前应该重置对象状态,避免数据污染。对于切片,应该重置长度但保留容量;对于结构体,应该清零所有字段。
避免大对象:sync.Pool适合复用小对象,大对象会增加内存占用,影响性能。建议对象大小控制在几KB以内。
合理使用:不是所有对象都适合使用sync.Pool,只有频繁创建销毁的对象才值得使用。对于生命周期长的对象,直接分配更合适。
性能对比示例:
// 使用sync.Pool的性能测试
func benchmarkPool() {
var bufferPool = sync.Pool{
New: func() interface{} {
return make([]byte, 0, 1024)
},
}
// 测试使用对象池的性能
b.Run("WithPool", func(b *testing.B) {
for i := 0; i < b.N; i++ {
buffer := bufferPool.Get().([]byte)
buffer = buffer[:0]
buffer = append(buffer, "test"...)
bufferPool.Put(buffer)
}
})
// 测试直接分配的性能
b.Run("WithoutPool", func(b *testing.B) {
for i := 0; i < b.N; i++ {
buffer := make([]byte, 0, 1024)
buffer = append(buffer, "test"...)
}
})
}sync.Pool适用于多种场景,但需要根据具体需求选择合适的策略。
临时缓冲区:网络编程中的读写缓冲区、JSON解析中的临时缓冲区等,这些对象频繁创建销毁,非常适合使用sync.Pool。
解析器对象:XML解析器、JSON解析器等,这些对象创建成本高,复用价值大。
连接池:数据库连接、HTTP客户端等,虽然sync.Pool不是专门的连接池,但可以用于管理连接对象。
最佳实践:
// 网络缓冲区池
var netBufferPool = sync.Pool{
New: func() interface{} {
return make([]byte, 4096)
},
}
// HTTP处理器中的使用
func handleHTTP(w http.ResponseWriter, r *http.Request) {
buffer := netBufferPool.Get().([]byte)
defer netBufferPool.Put(buffer)
// 使用buffer处理请求
n, err := r.Body.Read(buffer)
if err != nil {
return
}
// 处理数据
processData(buffer[:n])
}
// JSON解析器池
var jsonDecoderPool = sync.Pool{
New: func() interface{} {
return json.NewDecoder(nil)
},
}
func parseJSON(data []byte, v interface{}) error {
decoder := jsonDecoderPool.Get().(*json.Decoder)
defer jsonDecoderPool.Put(decoder)
// 重置decoder
decoder.SetReader(bytes.NewReader(data))
return decoder.Decode(v)
}
