
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
Go语言在内存管理方面的设计堪称经典,它巧妙地借鉴了TCMalloc的精华,又融入了自己的创新理念。这种设计不仅解决了传统内存分配器的性能瓶颈,还为高并发场景提供了强有力的支撑。让我们从几个关键维度来剖析这套内存管理体系。
Go的内存管理架构采用分层设计,每一层都有明确的职责和优化目标。用户层负责用户程序请求内存分配,分配层通过多个P的mcache并行处理,缓存层由mcentral统一管理span资源,堆管理层由mheap管理大块内存,内存层以arena作为基本分配单位。
内存管理架构图:
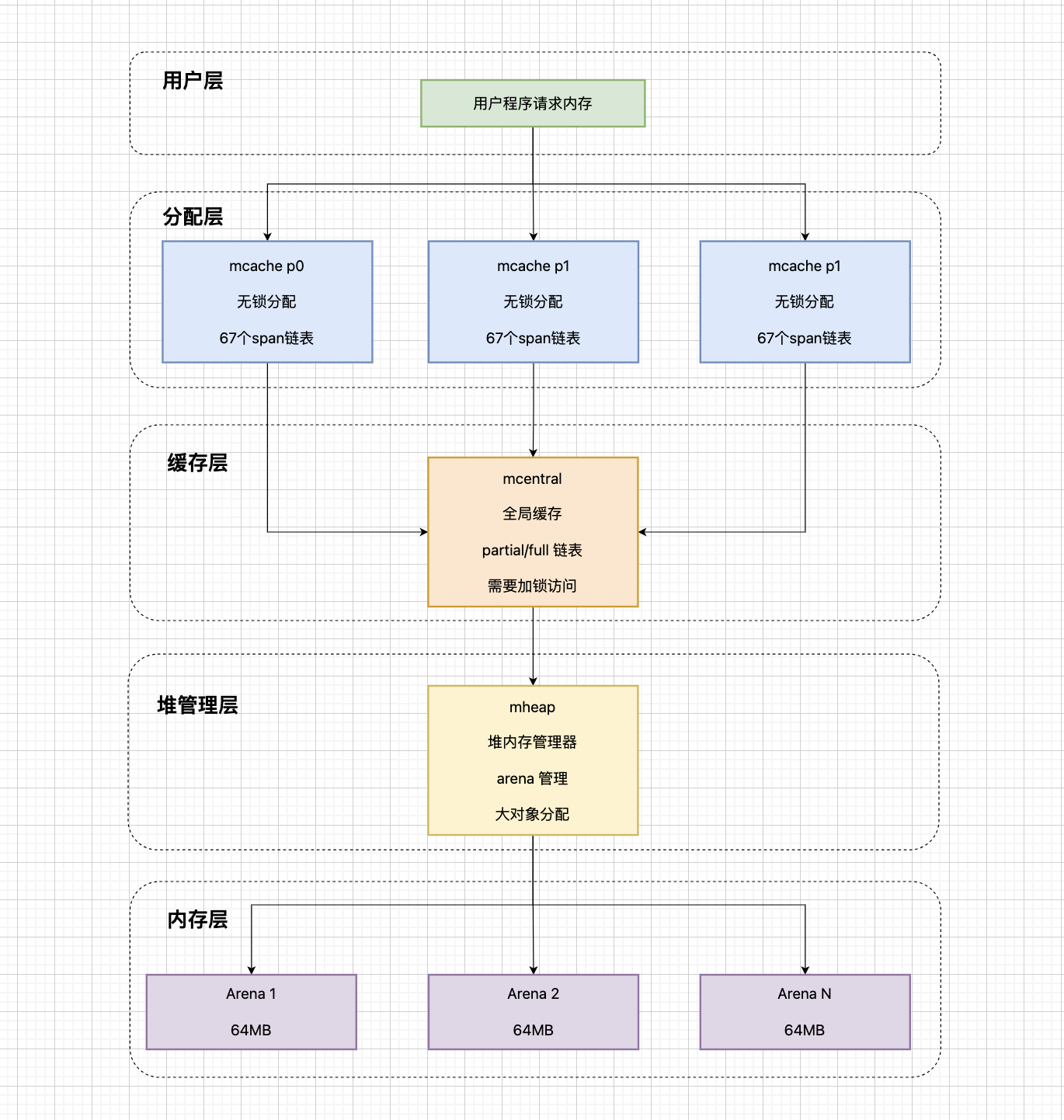
Go语言的内存管理采用分层设计,通过三个核心组件实现高效的内存分配和管理。
mcache(本地缓存):每个P(处理器)拥有独立的mcache,包含67个不同大小的span链表(8B到32KB),无锁分配,性能极高。当span用完时,从mcentral获取新的span。
mcentral(全局缓存):管理所有mcache共享的span,分为partial和full两个链表。partial链表包含还有空闲对象的span,full链表包含已无空闲对象的span。需要加锁访问,但频率较低。
mheap(堆管理器):管理整个堆内存,以arena(64MB)为单位分配内存,管理大对象分配(>32KB),负责内存回收和整理。
Go借鉴了Google的TCMalloc设计,采用多级缓存架构来减少锁竞争,提高并发性能。
用户请求 → mcache(无锁) → mcentral(加锁) → mheap(加锁)缓存层次:L1缓存是mcache,每个P独享,无锁访问;L2缓存是mcentral,全局共享,需要加锁;L3缓存是mheap,最终内存来源。
优势:大部分分配在mcache完成,无锁操作。只有缓存miss时才访问全局资源,显著减少锁竞争,提高并发性能。
Go根据对象大小采用不同的分配策略,这种分层设计既保证了分配效率,又减少了内存碎片。
微对象分配(<16B):使用tiny allocator进行打包分配,多个小对象共享同一个内存块,减少内存碎片,提高空间利用率,分配速度极快,无锁操作。
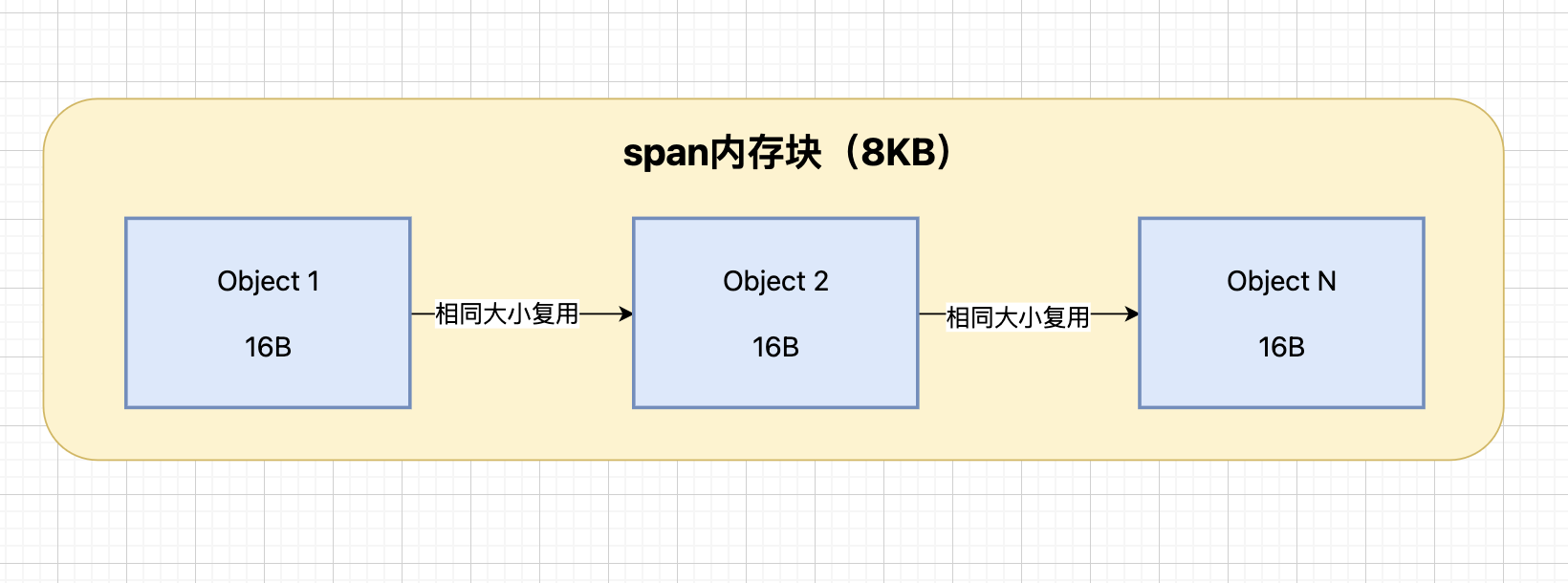
小对象分配(16B-32KB):67个固定大小的span,从mcache获取对应大小的span,无锁分配,性能极高,相同大小的对象复用同一个span。
大对象分配(>32KB):直接从mheap分配,需要加锁,性能相对较低,分配的内存块大小不固定,可能导致内存碎片。
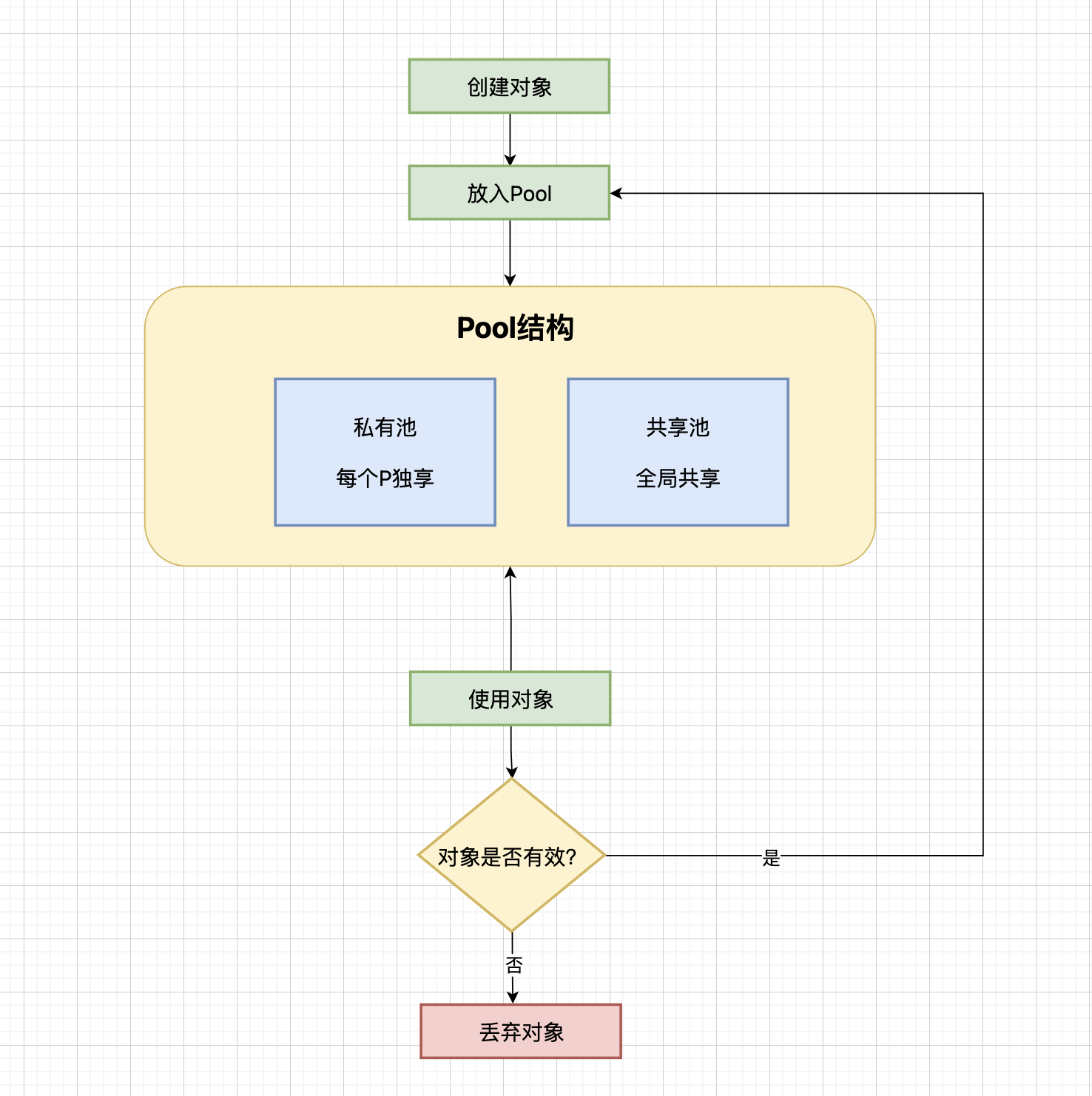
内存池复用是Go内存管理的重要优化策略,通过预分配和复用减少频繁的内存分配,利用对象生命周期特征进行优化,平衡内存使用效率和分配性能,减少GC压力,提高整体性能。
span复用原理:span是内存分配的基本单位,相同大小的对象复用同一个span,减少内存碎片,提高缓存局部性,实现内存的高效利用。
对象池机制:使用sync.Pool进行对象复用,减少GC压力,提高性能,适用于频繁创建销毁的对象,实现对象的生命周期管理。
内存对齐优化:按8字节对齐,提高访问效率,结构体字段重排减少内存占用,缓存行对齐避免伪共享,优化内存访问模式。
Go语言在内存分配方面做了多项重要优化:多级缓存机制(mcache无锁分配、mcentral全局缓存、mheap堆管理)减少锁竞争;对象大小分类(微对象打包、小对象span复用、大对象直接分配)提高分配效率;内存对齐优化(8字节对齐、结构体字段重排、缓存行对齐)提升访问性能;预分配策略(mcache预分配span、批量处理请求)减少频繁分配。
Go借鉴TCMalloc设计,采用多级缓存架构来减少锁竞争,提高并发性能。
缓存层次设计:Go的内存分配采用三级缓存机制,每一级都有特定的优化目标。L1缓存是mcache,每个P独享,实现无锁分配;L2缓存是mcentral,全局共享,管理span资源;L3缓存是mheap,最终内存来源,管理大块内存。这种分层设计使得大部分分配在mcache完成,只有缓存miss时才访问全局资源,显著减少锁竞争,提高并发性能。
无锁分配优化:大部分分配在mcache完成,无锁操作。每个P拥有独立的mcache,避免竞争。只有缓存miss时才访问全局资源。显著减少锁竞争,提高并发性能。
预分配策略:mcache预分配多个span,减少频繁的内存分配请求。批量处理分配请求,提高整体分配效率。
Go根据对象大小采用不同的分配策略,这种分类设计既保证了分配效率,又优化了内存使用。
微对象优化(<16B):使用tiny allocator进行打包分配,多个小对象共享同一个内存块。减少内存碎片,提高空间利用率。分配速度极快,无锁操作。
小对象优化(16B-32KB):67个固定大小的span,从mcache获取对应大小的span。无锁分配,性能极高。相同大小的对象复用同一个span。
大对象优化(>32KB):直接从mheap分配,需要加锁,性能相对较低。分配的内存块大小不固定,可能导致内存碎片。
Go通过多种内存对齐技术优化访问性能和内存使用效率。
8字节对齐:按8字节对齐,提高访问效率。结构体字段重排减少内存占用。缓存行对齐避免伪共享。优化内存访问模式。
缓存局部性优化:相同大小的对象复用同一个span,减少内存碎片,提高缓存命中率。对象在内存中连续分布,提高CPU缓存效率。
结构体优化:结构体字段重排减少内存占用,缓存行对齐避免伪共享,优化内存访问模式。
频繁的内存分配和释放导致碎片,不同大小的对象混合分配,内存块无法有效合并,影响内存使用效率和分配性能。Go通过多种机制减少内存碎片,提高内存使用效率。
span复用机制:span是内存分配的基本单位,相同大小的对象复用同一个span,减少内存碎片,提高缓存局部性,实现内存的高效利用。
内存整理策略:定期整理内存碎片,合并相邻的空闲内存块,移动对象减少碎片,提高内存使用效率。
分代回收配合:GC与内存分配协调工作,及时回收不再使用的内存,减少内存碎片积累,保持内存使用效率。
对象池复用:使用sync.Pool进行对象复用,减少频繁的内存分配,降低GC压力,提高整体性能。
Go语言的内存逃逸是指编译器将原本应该在栈上分配的对象转移到堆上分配的现象。逃逸分析是Go编译器在编译时进行的静态分析,用于确定对象应该分配在栈上还是堆上。当对象无法在编译时确定生命周期或需要在函数返回后继续使用时,就会发生内存逃逸。
逃逸分析目标:栈分配优先(优先在栈上分配对象,提高分配和释放效率)、生命周期分析(分析对象的生命周期,确定是否需要在堆上分配)和性能优化(减少GC压力,提高程序性能)。
逃逸分析示例:
// 不会逃逸:对象在函数内使用
func noEscape() {
x := 100
fmt.Println(x)
}
// 会逃逸:返回指针,对象需要在函数外使用
func escape() *int {
x := 100
return &x // 逃逸到堆
}Go语言中导致内存逃逸的常见原因包括以下几种情况。
函数返回指针:当函数返回局部变量的指针时,编译器无法确定该对象在函数返回后的生命周期,因此将其分配到堆上。
// 逃逸示例:返回指针
func createInt() *int {
x := 42
return &x // x逃逸到堆
}
// 避免逃逸:返回值
func createIntValue() int {
x := 42
return x // 不会逃逸
}对象大小不确定:当对象大小在编译时无法确定时,编译器会保守地将其分配到堆上。
// 逃逸示例:大小不确定
func createSlice(size int) []int {
return make([]int, size) // 可能逃逸
}
// 避免逃逸:固定大小
func createFixedSlice() [10]int {
return [10]int{} // 不会逃逸
}接口类型:接口类型在运行时才能确定具体类型,编译器无法进行精确分析。
// 逃逸示例:接口类型
func processInterface() interface{} {
x := 100
return x // 逃逸到堆
}
// 避免逃逸:具体类型
func processConcrete() int {
x := 100
return x // 不会逃逸
}闭包捕获变量:当闭包捕获局部变量时,这些变量需要在闭包的生命周期内保持有效。
// 逃逸示例:闭包捕获
func createClosure() func() int {
x := 100
return func() int {
return x // x逃逸到堆
}
}对象过大:当对象大小超过栈的限制时,会被分配到堆上。
// 逃逸示例:大对象
func createLargeObject() [10000]int {
return [10000]int{} // 可能逃逸
}避免内存逃逸的方法包括:避免返回局部变量指针(使用值传递)、控制对象大小(避免过大的栈对象)、减少接口使用(使用具体类型)、优化闭包使用(避免不必要的变量捕获)以及使用对象池(sync.Pool减少堆分配)。
避免返回局部变量指针:尽量使用值传递而不是指针传递,特别是对于小对象。
// 推荐:值传递
func processValue(data int) int {
return data * 2
}
// 避免:返回指针
func processPointer(data int) *int {
result := data * 2
return &result // 逃逸
}控制对象大小:避免在栈上分配过大的对象,合理控制对象大小。
// 推荐:合理大小
func createSmallArray() [100]int {
return [100]int{}
}
// 避免:过大对象
func createLargeArray() [10000]int {
return [10000]int{} // 可能逃逸
}减少接口使用:在性能敏感的场景下,使用具体类型而不是接口类型。
// 推荐:具体类型
func processString(s string) string {
return s + "processed"
}
// 避免:接口类型
func processInterface(i interface{}) interface{} {
return i // 可能逃逸
}优化闭包使用:避免在闭包中捕获不必要的变量。
// 推荐:减少捕获
func createOptimizedClosure() func() int {
return func() int {
return 100 // 不捕获变量
}
}
// 避免:不必要的捕获
func createUnoptimizedClosure() func() int {
x := 100
return func() int {
return x // 捕获变量,逃逸
}
}使用对象池:对于频繁创建销毁的对象,使用sync.Pool进行复用。
// 推荐:使用对象池
var bufferPool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024)
},
}
func getBuffer() []byte {
return bufferPool.Get().([]byte)
}
func putBuffer(buf []byte) {
bufferPool.Put(buf)
}Go提供了多种工具来分析内存逃逸情况,帮助开发者优化程序性能。
使用go build -gcflags:通过编译器标志查看逃逸分析结果。
# 查看逃逸分析详情
go build -gcflags="-m -m" main.go
# 只查看逃逸信息
go build -gcflags="-m" main.go逃逸分析输出解读:
./main.go:10:6: can inline createInt
./main.go:10:6: inlining call to createInt
./main.go:11:2: moved to heap: x # 表示x逃逸到堆
./main.go:15:6: can inline createIntValue
./main.go:15:6: inlining call to createIntValue
./main.go:16:2: moved to heap: x # 表示x逃逸到堆使用pprof分析:通过内存分析工具查看实际的内存分配情况。
import (
"runtime/pprof"
"os"
)
func main() {
f, _ := os.Create("heap.prof")
defer f.Close()
pprof.WriteHeapProfile(f)
}性能对比测试:通过基准测试比较不同实现方式的性能差异。
func BenchmarkStackAllocation(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = createIntValue() // 栈分配
}
}
func BenchmarkHeapAllocation(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = createInt() // 堆分配
}
}Go语言的内存对齐是指数据在内存中的存储位置必须满足特定边界要求的现象。内存对齐要求数据按照其大小的整数倍地址进行存储,例如8字节的数据必须存储在8的倍数地址上。Go语言默认按8字节对齐,结构体字段按照最大字段大小对齐。
对齐规则:Go语言中,基本数据类型的对齐要求如下:bool类型(1字节对齐)、int8/uint8(1字节对齐)、int16/uint16(2字节对齐)、int32/uint32(4字节对齐)、int64/uint64(8字节对齐)、指针类型(8字节对齐)和接口类型(16字节对齐)。
结构体对齐:结构体的对齐要求等于其最大字段的对齐要求。结构体的大小必须是其对齐要求的整数倍,编译器会在字段之间插入填充字节以满足对齐要求。
内存对齐示例:
// 结构体对齐示例
type Example struct {
a bool // 1字节,偏移0
b int32 // 4字节,偏移4(需要3字节填充)
c int64 // 8字节,偏移8
d int16 // 2字节,偏移16(需要6字节填充)
}
// 总大小:24字节(8字节对齐)
// 优化后的结构体
type OptimizedExample struct {
c int64 // 8字节,偏移0
b int32 // 4字节,偏移8
d int16 // 2字节,偏移12
a bool // 1字节,偏移14
}
// 总大小:16字节(节省8字节)内存对齐的原因包括:CPU访问优化(CPU一次读取对齐的数据,减少内存访问次数)、缓存行对齐(避免伪共享,提高缓存效率)、原子操作要求(某些CPU指令要求数据对齐)、性能优化(减少内存访问延迟,提高程序性能)和硬件兼容性(不同架构对内存对齐有不同要求)。
CPU访问内存时,对齐的数据可以显著提高访问效率。
CPU访问模式:现代CPU通常以缓存行为单位访问内存,一个缓存行通常是64字节。当数据对齐时,CPU可以一次性读取整个数据,避免多次内存访问。
未对齐访问问题:当数据未对齐时,CPU可能需要多次内存访问才能读取完整数据,这会导致性能下降。在某些架构上,未对齐访问甚至会导致程序崩溃。
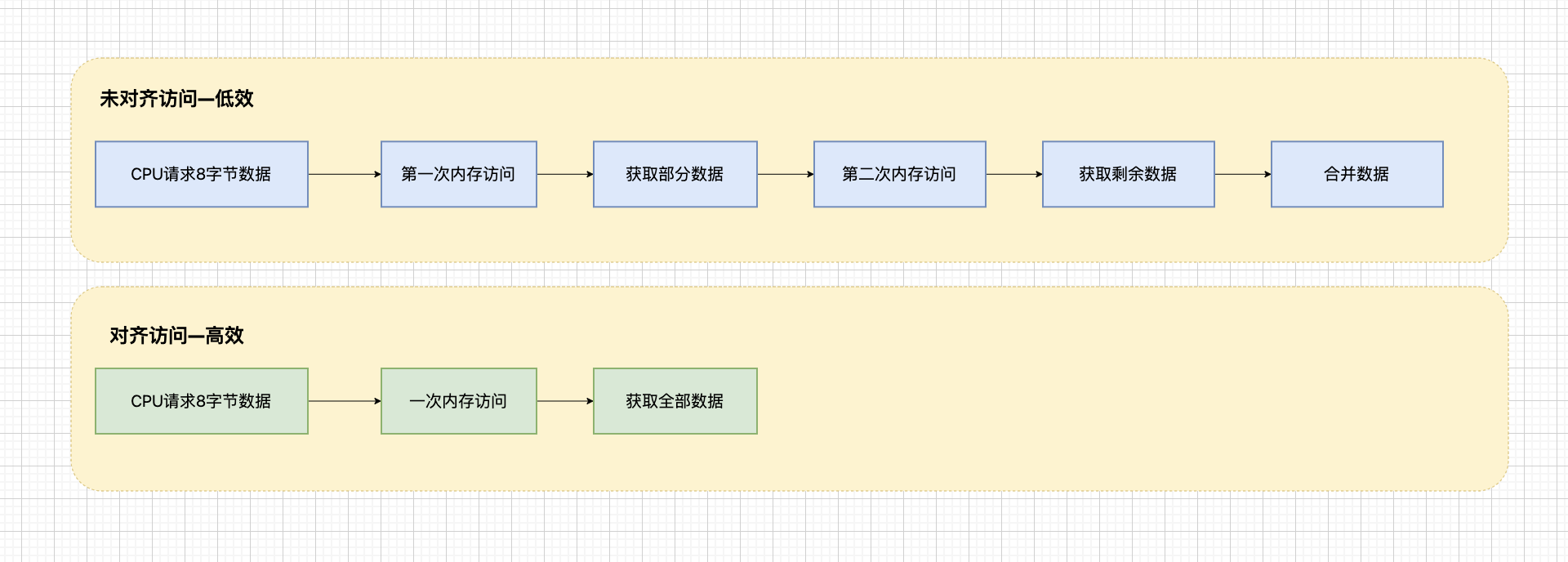
性能影响示例:
// 测试对齐对性能的影响
func benchmarkAlignment() {
// 对齐的结构体
type Aligned struct {
a int64
b int64
c int64
}
// 未对齐的结构体
type Unaligned struct {
a int8
b int64
c int64
}
// 性能测试
aligned := make([]Aligned, 1000)
unaligned := make([]Unaligned, 1000)
// 测试访问性能
// ...
}缓存行对齐是内存对齐的一个重要应用,用于避免伪共享问题。
伪共享问题:当多个CPU核心访问同一缓存行的不同数据时,会导致缓存行在核心之间频繁传输,造成性能下降。这种现象称为伪共享。
缓存行对齐解决方案:通过填充字节确保不同核心访问的数据位于不同的缓存行中,避免伪共享。
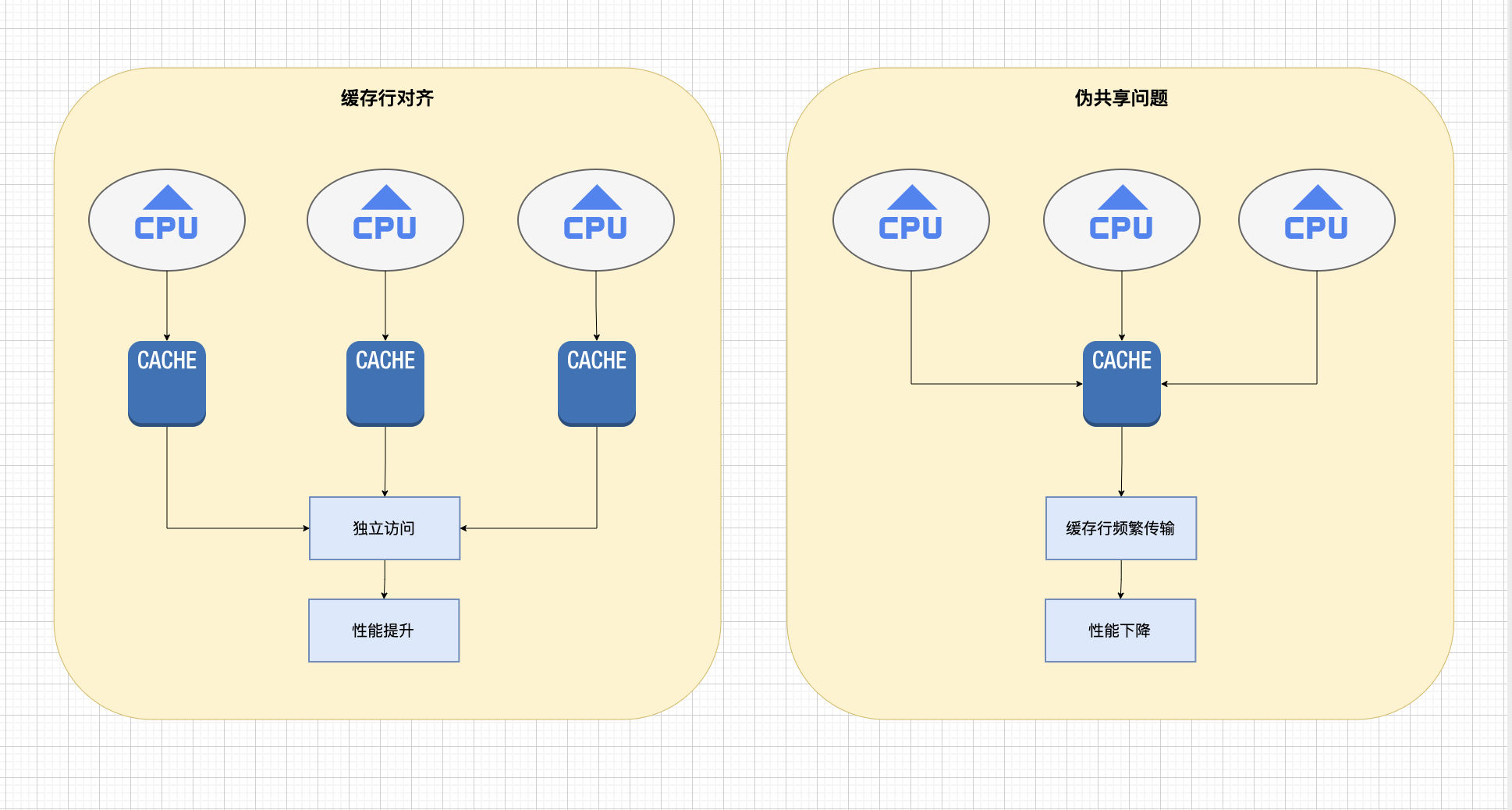
缓存行对齐示例:
// 避免伪共享的结构体设计
type CacheLineAligned struct {
data [64]byte // 一个缓存行的大小
}
type SharedData struct {
data1 CacheLineAligned
data2 CacheLineAligned
data3 CacheLineAligned
}
// 使用示例
func processSharedData(shared *SharedData) {
// 每个核心访问不同的缓存行
go func() {
// 处理data1
}()
go func() {
// 处理data2
}()
go func() {
// 处理data3
}()
}某些CPU指令和原子操作对内存对齐有严格要求。
原子操作对齐要求:某些架构上的原子操作要求数据必须对齐。例如,在x86-64架构上,64位原子操作要求数据8字节对齐。
原子操作示例:
import "sync/atomic"
// 正确的原子操作(对齐)
type AtomicCounter struct {
value int64 // 8字节对齐
}
func (c *AtomicCounter) Increment() {
atomic.AddInt64(&c.value, 1)
}
// 错误的原子操作(未对齐)
type BadAtomicCounter struct {
padding byte // 1字节
value int64 // 未对齐
}通过合理排列结构体字段,可以显著减少内存占用和提高访问效率。
字段排列原则:按大小降序排列(大字段在前,小字段在后)、考虑访问模式(频繁访问的字段放在前面)、避免过度优化(过度优化可能影响代码可读性)。
字段排列优化示例:
// 未优化的结构体
type UnoptimizedStruct struct {
a bool // 1字节
b int64 // 8字节
c bool // 1字节
d int32 // 4字节
e bool // 1字节
}
// 大小:24字节(包含填充)
// 优化后的结构体
type OptimizedStruct struct {
b int64 // 8字节
d int32 // 4字节
a bool // 1字节
c bool // 1字节
e bool // 1字节
}
// 大小:16字节(节省8字节)
// 进一步优化(考虑访问模式)
type FurtherOptimizedStruct struct {
b int64 // 8字节,最常访问
d int32 // 4字节
a bool // 1字节
c bool // 1字节
e bool // 1字节
}内存对齐工具使用:
import "unsafe"
// 查看结构体大小和对齐
func analyzeStruct() {
var s OptimizedStruct
fmt.Printf("大小: %d\n", unsafe.Sizeof(s))
fmt.Printf("对齐: %d\n", unsafe.Alignof(s))
}
// 查看字段偏移
func analyzeFields() {
var s OptimizedStruct
fmt.Printf("字段a偏移: %d\n", unsafe.Offsetof(s.a))
fmt.Printf("字段b偏移: %d\n", unsafe.Offsetof(s.b))
}Go语言的内存模型通过happens-before关系和丰富的同步原语,为并发编程提供了坚实的理论基础。
happens-before关系是Go内存模型的核心概念,定义了操作之间的顺序约束。
happens-before定义:如果事件A happens-before事件B,那么A的所有副作用在B开始之前都是可见的。这种关系是传递性的,如果A happens-before B,B happens-before C,那么A happens-before C。
happens-before规则:单goroutine顺序(同一goroutine中的操作按程序顺序执行)、channel通信(发送操作happens-before对应的接收操作)、mutex操作(解锁操作happens-before后续的加锁操作)、once操作(once.Do的调用happens-before其返回)和goroutine创建(goroutine创建happens-before goroutine开始执行)。
happens-before示例:
// channel通信的happens-before关系
func channelExample() {
ch := make(chan int)
go func() {
ch <- 1 // 发送操作
}()
value := <-ch // 接收操作,happens-after发送操作
fmt.Println(value)
}
// mutex的happens-before关系
func mutexExample() {
var mu sync.Mutex
var data int
go func() {
mu.Lock()
data = 42 // 写操作
mu.Unlock() // 解锁操作
}()
mu.Lock() // 加锁操作,happens-after解锁操作
fmt.Println(data) // 能看到data=42
mu.Unlock()
}Go语言提供了丰富的同步原语,用于实现并发安全。
channel通信:channel是Go语言的核心同步机制,实现了CSP(Communicating Sequential Processes)模型。无缓冲channel(发送和接收必须同时准备好)、有缓冲channel(缓冲区满时发送阻塞,空时接收阻塞)和select语句(多路复用channel操作)。
互斥锁:sync.Mutex提供互斥访问机制,保证同一时间只有一个goroutine能访问临界区。
读写锁:sync.RWMutex允许多个goroutine同时读取,但只允许一个goroutine写入。
编译器优化可能导致指令重排序,Go内存模型通过规则确保重排序不会破坏happens-before关系。
重排序规则:单goroutine内(编译器可以重排序不依赖的操作)、跨goroutine(只有通过同步原语建立happens-before关系)、原子操作(原子操作不会被重排序)和内存屏障(编译器插入内存屏障防止重排序)。
重排序示例:
// 可能的重排序
func reorderExample() {
var a, b int
var flag bool
go func() {
a = 1
b = 2
flag = true // 编译器可能重排序这些操作
}()
go func() {
for !flag {
// 等待
}
fmt.Println(a, b) // 可能看到a=0, b=0
}()
}
// 正确的同步
func correctSync() {
var a, b int
ch := make(chan bool)
go func() {
a = 1
b = 2
ch <- true // 建立happens-before关系
}()
<-ch // 等待发送操作
fmt.Println(a, b) // 保证看到a=1, b=2
}从channel通信到mutex互斥,从原子操作到内存屏障,这套完整的并发安全机制确保了多goroutine环境下的程序正确性,同时保持了良好的性能表现,为构建高并发应用提供了可靠的技术保障。
原子操作:sync/atomic包提供原子操作,保证操作的原子性。
// 原子操作示例
type AtomicCounter struct {
value int64
}
func (c *AtomicCounter) Increment() {
atomic.AddInt64(&c.value, 1)
}
func (c *AtomicCounter) GetValue() int64 {
return atomic.LoadInt64(&c.value)
}
func (c *AtomicCounter) CompareAndSwap(old, new int64) bool {
return atomic.CompareAndSwapInt64(&c.value, old, new)
}内存屏障:编译器自动插入内存屏障,确保内存操作的顺序。
顺序一致性:保证单goroutine内的操作按程序顺序执行,跨goroutine的操作通过同步原语建立顺序。
并发安全最佳实践:
// 使用channel进行通信
func channelCommunication() {
ch := make(chan int, 10)
// 生产者
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}()
// 消费者
for value := range ch {
fmt.Println(value)
}
}
// 使用sync.Once保证初始化
var once sync.Once
var instance *Singleton
func getInstance() *Singleton {
once.Do(func() {
instance = &Singleton{}
})
return instance
}
// 使用context控制goroutine生命周期
func contextExample(ctx context.Context) {
go func() {
select {
case <-ctx.Done():
return
case <-time.After(time.Second):
// 执行任务
}
}()
}Go语言的内存泄漏是指程序分配的内存无法被GC回收,导致内存使用量持续增长的现象。虽然Go有GC机制,但某些情况下仍会发生内存泄漏:
goroutine泄漏:goroutine是Go并发的基础,但如果goroutine没有正确退出,会一直占用内存。无限循环(goroutine陷入死循环)、阻塞等待(goroutine等待永远不会到来的信号)、资源竞争(goroutine等待锁但锁永远不会释放)和context未传递(goroutine无法感知取消信号)。
// goroutine泄漏示例
func goroutineLeak() {
for i := 0; i < 1000; i++ {
go func() {
// 无限循环,永不退出
for {
time.Sleep(time.Second)
// 执行一些工作
}
}()
}
}
// 正确的goroutine管理
func correctGoroutine(ctx context.Context) {
for i := 0; i < 1000; i++ {
go func() {
for {
select {
case <-ctx.Done():
return // 正确退出
case <-time.After(time.Second):
// 执行工作
}
}
}()
}
}channel泄漏:channel是Go的通信机制,但如果使用不当会导致泄漏。发送方阻塞(接收方不存在或已关闭)、接收方阻塞(发送方不存在或已关闭)和channel未关闭(goroutine等待channel关闭)。
// channel泄漏示例
func channelLeak() {
ch := make(chan int)
go func() {
ch <- 1 // 发送方阻塞,没有接收方
}()
// 主goroutine退出,发送方永远阻塞
}
// 正确的channel使用
func correctChannel() {
ch := make(chan int)
go func() {
defer close(ch) // 确保关闭channel
ch <- 1
}()
value := <-ch // 有接收方
fmt.Println(value)
}全局变量引用:全局变量持有大对象引用,导致对象无法被GC回收。
// 全局变量泄漏
var globalCache = make(map[string]*LargeObject)
func addToCache(key string, obj *LargeObject) {
globalCache[key] = obj // 全局引用,无法回收
}
// 避免全局变量泄漏
type Cache struct {
mu sync.RWMutex
cache map[string]*LargeObject
}
func (c *Cache) Add(key string, obj *LargeObject) {
c.mu.Lock()
defer c.mu.Unlock()
c.cache[key] = obj
}
func (c *Cache) Remove(key string) {
c.mu.Lock()
defer c.mu.Unlock()
delete(c.cache, key) // 删除引用,允许GC回收
}闭包捕获:闭包捕获大对象,延长对象生命周期。
// 闭包捕获泄漏
func closureLeak() {
largeData := make([]byte, 1024*1024) // 1MB数据
go func() {
// 闭包捕获largeData,延长其生命周期
for {
time.Sleep(time.Second)
fmt.Println(len(largeData)) // 使用largeData
}
}()
}
// 避免闭包捕获
func avoidClosureLeak() {
largeData := make([]byte, 1024*1024)
go func(data []byte) {
// 传递副本,不捕获原对象
for {
time.Sleep(time.Second)
fmt.Println(len(data))
}
}(largeData)
// largeData可以被GC回收
}及时发现内存泄漏是解决问题的关键,需要采用多种检测方法。
使用pprof工具:Go标准库提供的性能分析工具,可以检测内存泄漏。
使用runtime包监控:通过runtime包获取内存统计信息。
import "runtime"
func monitorMemory() {
go func() {
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for range ticker.C {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("Alloc: %d, TotalAlloc: %d, Sys: %d, NumGC: %d\n",
m.Alloc, m.TotalAlloc, m.Sys, m.NumGC)
}
}()
}使用第三方工具:如go-torch、go-trace等工具进行更深入的分析。
通过合理的编程实践和工具使用,可以有效预防内存泄漏。
正确管理goroutine生命周期:使用context控制goroutine的取消,设置超时机制。
// 使用context管理goroutine
func managedGoroutine(ctx context.Context) {
go func() {
for {
select {
case <-ctx.Done():
return // 正确退出
case <-time.After(time.Second):
// 执行工作
}
}
}()
}
// 设置超时
func timeoutGoroutine() {
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
go func() {
for {
select {
case <-ctx.Done():
return
case <-time.After(time.Second):
// 工作
}
}
}()
}及时关闭资源:使用defer确保资源正确关闭。
// 正确关闭资源
func closeResources() {
file, err := os.Open("file.txt")
if err != nil {
return
}
defer file.Close() // 确保文件关闭
ticker := time.NewTicker(time.Second)
defer ticker.Stop() // 确保定时器停止
ch := make(chan int)
defer close(ch) // 确保channel关闭
}使用对象池:对于频繁创建销毁的对象,使用sync.Pool进行复用。
// 使用对象池
var bufferPool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024)
},
}
func getBuffer() []byte {
return bufferPool.Get().([]byte)
}
func putBuffer(buf []byte) {
bufferPool.Put(buf)
}定期检查:建立内存监控机制,定期检查内存使用情况。
// 内存监控
func memoryMonitor() {
go func() {
ticker := time.NewTicker(time.Minute)
defer ticker.Stop()
for range ticker.C {
var m runtime.MemStats
runtime.ReadMemStats(&m)
// 检查内存使用是否异常
if m.Alloc > 100*1024*1024 { // 100MB
log.Printf("内存使用异常: %d bytes", m.Alloc)
}
}
}()
}内存泄漏检测最佳实践:
// 定期内存检查
func periodicMemoryCheck() {
go func() {
ticker := time.NewTicker(time.Minute)
defer ticker.Stop()
for range ticker.C {
var m runtime.MemStats
runtime.ReadMemStats(&m)
// 检查goroutine数量
numGoroutines := runtime.NumGoroutine()
if numGoroutines > 1000 {
log.Printf("goroutine数量异常: %d", numGoroutines)
}
// 检查内存使用
if m.Alloc > 500*1024*1024 { // 500MB
log.Printf("内存使用异常: %d bytes", m.Alloc)
}
}
}()
}内存分析工具是Go程序性能优化的利器,从标准库到第三方工具,从静态分析到动态监控,这些工具为开发者提供了全方位的内存诊断能力。掌握这些工具的使用方法,能够快速定位内存泄漏、优化内存分配、提升程序性能,为构建高性能Go应用提供强有力的技术支撑。
Go语言的内存分析工具可以分为标准库工具和第三方工具两大类,每种工具都有其特定的使用场景。
标准库工具:pprof(Go标准库提供的性能分析工具,支持多种类型的profile)、runtime包(提供详细的内存统计信息,包括堆内存、栈内存、GC统计等)、go tool trace(分析程序的执行轨迹,包括GC事件、goroutine调度等)和GODEBUG环境变量(通过环境变量控制运行时行为,输出详细的调试信息)。
第三方工具:go-torch(基于pprof生成火焰图,直观显示CPU和内存使用热点)、go-trace(可视化trace文件,分析程序执行过程)、Prometheus + Grafana(建立完整的监控体系,实时监控内存使用)、Jaeger(分布式追踪系统,分析微服务架构下的内存使用)和go-memstats(专门的内存统计工具)。
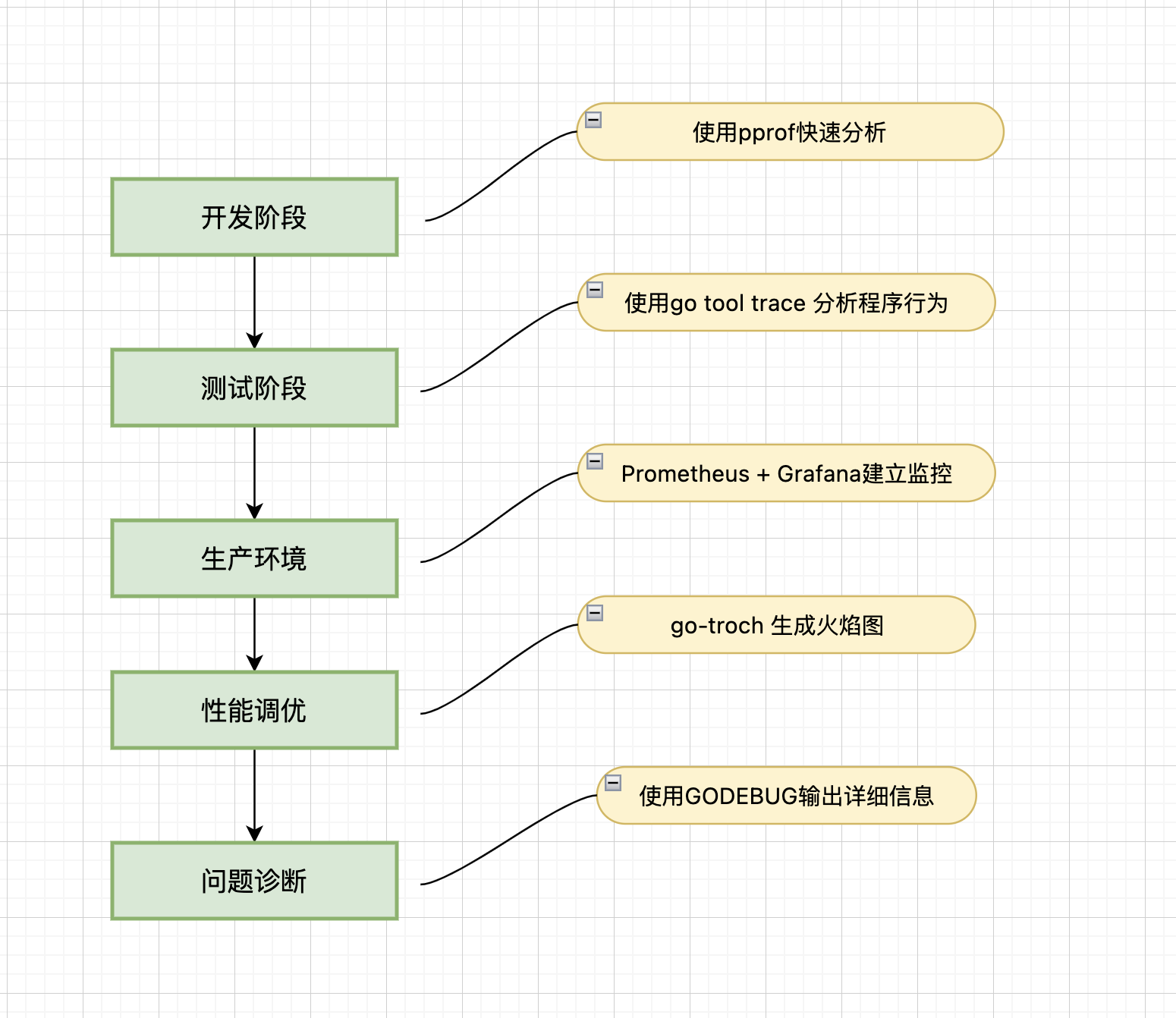
工具选择策略:开发阶段(使用pprof进行快速分析)、测试阶段(使用go tool trace分析程序行为)、生产环境(使用Prometheus + Grafana建立监控)、性能调优(使用go-torch生成火焰图)和问题诊断(使用GODEBUG输出详细信息)。
pprof是Go最常用的性能分析工具,可以生成多种类型的profile文件。
pprof命令使用:Top命令(显示最耗CPU或内存的函数)、List命令(显示特定函数的详细分析)、Web命令(在浏览器中查看可视化结果)、Graph命令(生成调用关系图)和Peek命令(显示特定函数的调用者)。
// 生成CPU profile
import _ "net/http/pprof"
import "net/http"
func main() {
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
// 生成CPU profile
f, _ := os.Create("cpu.prof")
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
// 你的程序逻辑
runYourProgram()
}
// 生成内存 profile
func generateMemProfile() {
f, _ := os.Create("mem.prof")
pprof.WriteHeapProfile(f)
f.Close()
}
// pprof命令使用示例
// 1. Top命令 - 显示最耗CPU的函数
// go tool pprof -top cpu.prof
// 2. List命令 - 显示特定函数的详细分析
// go tool pprof -list=main.runYourProgram cpu.prof
// 3. Web命令 - 在浏览器中查看可视化结果
// go tool pprof -http=:8080 cpu.prof
// 4. Graph命令 - 生成调用关系图
// go tool pprof -graph cpu.prof
// 5. Peek命令 - 显示特定函数的调用者
// go tool pprof -peek=main.runYourProgram cpu.prof
// 6. 内存分析命令
// go tool pprof -top mem.prof
// go tool pprof -list=main.allocateMemory mem.prof
// 7. Goroutine分析
// go tool pprof -top goroutine.prof
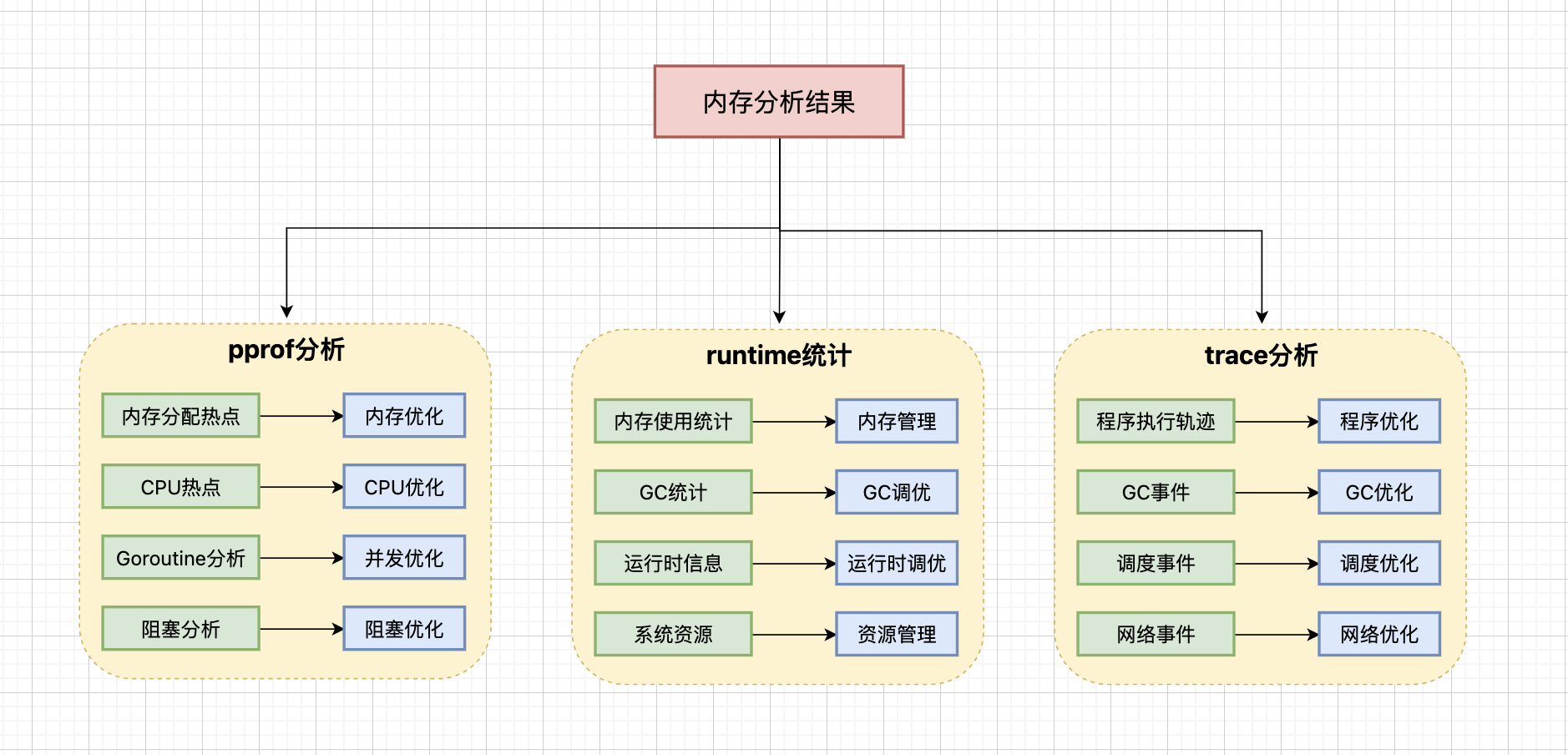
// go tool pprof -list=main.createGoroutine goroutine.prof内存profile分析要点:内存分配热点(识别内存分配最多的函数,重点关注频繁分配的对象)、内存泄漏(分析内存使用趋势,检查是否有持续增长的内存使用)、对象大小分布(了解对象大小分布情况,优化大对象分配)、GC压力(分析GC对程序的影响,检查GC频率和停顿时间)和内存碎片(识别内存碎片问题,优化内存分配模式)。
CPU profile分析要点:CPU热点(识别CPU使用最多的函数,重点关注计算密集型操作)、调用关系(分析函数调用关系,找出调用链中的瓶颈)、性能瓶颈(定位性能瓶颈,识别可优化的代码路径)、优化机会(识别优化机会,重点关注热点函数)和并发问题(分析并发相关的问题,检查锁竞争和调度)。
Goroutine profile分析要点:Goroutine数量(监控goroutine数量变化,检查是否有异常增长)、Goroutine泄漏(识别goroutine泄漏,检查是否有未正确退出的goroutine)、阻塞分析(分析goroutine阻塞情况,找出阻塞原因)、调度问题(分析调度器问题,检查goroutine调度效率)和死锁检测(检测死锁问题,分析goroutine之间的依赖关系)。
runtime包提供了详细的内存和GC统计信息,是实时监控的重要工具。
内存使用统计:Alloc(当前堆内存使用量,反映程序的内存占用)、Sys(系统分配的内存总量,包括堆内存和栈内存)、Mallocs/Frees(内存分配和释放次数,反映内存分配模式)、HeapAlloc(堆内存分配量,与Alloc相同)和HeapSys(堆内存系统分配量,反映堆内存的系统占用)。
GC统计信息:NumGC(GC触发次数,反映GC频率)、PauseTotalNs(总停顿时间,反映GC对程序的影响)、PauseNs(每次GC的停顿时间,用于分析GC性能)和GCCPUFraction(GC占用的CPU时间比例,反映GC开销)。
运行时信息:NumGoroutine(当前goroutine数量,监控并发度)、NumCPU(CPU核心数,用于性能分析)和GOMAXPROCS(最大处理器数,影响并发性能)。
go tool trace可以分析程序的执行轨迹,提供时间维度的性能分析。
程序执行轨迹:时间线分析(查看程序在时间轴上的执行情况)、CPU使用率(分析CPU使用的时间分布)、内存分配(跟踪内存分配的时间点)和函数调用(分析函数调用的时间分布)。
GC事件分析:GC触发时间(分析GC触发的时机和频率)、GC停顿时间(查看每次GC的停顿时长)、GC并发度(分析GC与用户程序的并发程度)和GC效率(评估GC的回收效率)。
调度事件分析:Goroutine调度(分析goroutine的调度情况)、系统调用(跟踪系统调用的频率和耗时)、网络事件(分析网络IO的时间分布)和阻塞事件(识别程序中的阻塞点)。
根据上述分析结果,可以制定相应的优化策略:
内存分析过程中会遇到各种问题,需要掌握常见问题的诊断和解决方法。
内存泄漏诊断:使用pprof(生成heap profile分析内存分配)、监控内存使用(持续监控内存使用趋势)、分析对象引用(分析对象的引用关系)、检查goroutine(检查goroutine是否泄漏)和分析GC行为(分析GC的频率和效果)。
性能瓶颈诊断:CPU profile(分析CPU使用热点)、内存profile(分析内存分配热点)、block profile(分析阻塞情况)、mutex profile(分析锁竞争)和trace分析(分析程序执行轨迹)。
GC问题诊断:GC频率异常(GC触发过于频繁或稀少)、停顿时间过长(GC停顿时间超过预期)、内存使用异常(内存使用量持续增长)、GC压力过大(GC占用过多CPU时间)和内存碎片(内存碎片影响分配效率)。
并发问题诊断:Goroutine泄漏(goroutine数量持续增长)、死锁检测(检测程序死锁)、竞争条件(分析数据竞争)、调度问题(分析调度器行为)和锁竞争(分析锁的使用情况)。
诊断工具组合使用:
// 综合诊断工具
type MemoryDiagnostic struct {
cpuProfile *os.File
heapProfile *os.File
traceFile *os.File
memStats []runtime.MemStats
}
func NewMemoryDiagnostic() *MemoryDiagnostic {
return &MemoryDiagnostic{
memStats: make([]runtime.MemStats, 0),
}
}
func (d *MemoryDiagnostic) StartDiagnostic() error {
// 启动CPU profile
cpuFile, err := os.Create("cpu.prof")
if err != nil {
return err
}
d.cpuProfile = cpuFile
pprof.StartCPUProfile(cpuFile)
// 启动trace
traceFile, err := os.Create("trace.out")
if err != nil {
return err
}
d.traceFile = traceFile
trace.Start(traceFile)
return nil
}
func (d *MemoryDiagnostic) StopDiagnostic() {
// 停止CPU profile
pprof.StopCPUProfile()
d.cpuProfile.Close()
// 停止trace
trace.Stop()
d.traceFile.Close()
// 生成heap profile
heapFile, _ := os.Create("heap.prof")
defer heapFile.Close()
pprof.WriteHeapProfile(heapFile)
}
func (d *MemoryDiagnostic) CollectMemStats() {
var m runtime.MemStats
runtime.ReadMemStats(&m)
d.memStats = append(d.memStats, m)
}
func (d *MemoryDiagnostic) Analyze() {
if len(d.memStats) < 2 {
return
}
// 分析内存使用趋势
first := d.memStats[0]
last := d.memStats[len(d.memStats)-1]
fmt.Printf("内存使用分析:\n")
fmt.Printf(" 初始内存: %d bytes\n", first.Alloc)
fmt.Printf(" 最终内存: %d bytes\n", last.Alloc)
fmt.Printf(" 内存增长: %d bytes\n", last.Alloc-first.Alloc)
fmt.Printf(" GC次数: %d\n", last.NumGC-first.NumGC)
}容器环境下的内存管理策略需要考虑资源限制和隔离性的特殊要求。核心策略包括:内存限制设置(通过cgroup限制容器内存使用)、GOMEMLIMIT环境变量(设置Go程序的内存限制)、GC调优(根据容器资源调整GC参数)、内存监控(实时监控容器内存使用)和OOM处理(预防和处理内存不足)。
容器内存管理的关键技术:内存限制(使用--memory参数限制容器内存)、内存预留(使用--memory-reservation预留内存)、内存交换(控制swap使用)、内存监控(使用docker stats监控内存使用)和自动重启(配置内存超限自动重启策略)。
容器环境下的内存管理首先需要正确设置内存限制,确保应用在有限资源下稳定运行。
Docker内存限制:--memory参数(设置容器最大内存使用量)、--memory-reservation参数(设置内存预留量)、--memory-swap参数(设置swap使用限制)和 --oom-kill-disable参数(禁用OOM killer)。
Kubernetes内存限制:requests.memory(容器请求的内存资源)、limits.memory(容器最大可用内存)、memory.available(节点可用内存监控)和HorizontalPodAutoscaler(基于内存使用自动扩缩容)。
内存限制示例:
# Docker运行示例
docker run --memory=512m --memory-reservation=256m --memory-swap=1g myapp
# Kubernetes部署示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
template:
spec:
containers:
- name: myapp
image: myapp:latest
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
env:
- name: GOMEMLIMIT
value: "400Mi"内存监控配置:
// 容器内存监控
func monitorContainerMemory() {
go func() {
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for range ticker.C {
var m runtime.MemStats
runtime.ReadMemStats(&m)
// 检查内存使用是否接近限制
memoryLimit := getMemoryLimit() // 获取容器内存限制
if m.Alloc > memoryLimit*0.8 { // 80%警告阈值
log.Printf("内存使用接近限制: %d/%d bytes", m.Alloc, memoryLimit)
}
// 检查系统内存
if m.Sys > memoryLimit*0.9 { // 90%危险阈值
log.Printf("系统内存使用过高: %d/%d bytes", m.Sys, memoryLimit)
runtime.GC() // 强制GC
}
}
}()
}
// 获取容器内存限制
func getMemoryLimit() uint64 {
// 从cgroup读取内存限制
data, err := os.ReadFile("/sys/fs/cgroup/memory/memory.limit_in_bytes")
if err != nil {
return 0
}
limit, err := strconv.ParseUint(strings.TrimSpace(string(data)), 10, 64)
if err != nil {
return 0
}
return limit
}GOMEMLIMIT是Go 1.19引入的新特性,用于设置Go程序的内存限制。
GOMEMLIMIT作用:内存限制(设置Go程序的最大内存使用量)、GC触发(当内存使用接近限制时触发GC)、OOM预防(防止程序因内存不足而崩溃)、资源管理(帮助容器更好地管理内存资源)和性能优化(在内存限制下优化GC行为)。
GOMEMLIMIT设置策略:容器内存的80%(为系统和其他进程预留空间)、根据应用特点调整(内存密集型应用设置较低,CPU密集型应用设置较高)、考虑GC开销(为GC预留足够内存)、监控调整(根据实际使用情况调整)和安全边际(设置合理的安全边际)。
GOMEMLIMIT使用示例:
// 设置内存限制
func setMemoryLimit() {
// 获取容器内存限制
containerMemory := getContainerMemoryLimit()
// 设置Go内存限制为容器内存的80%
goMemoryLimit := containerMemory * 0.8
// 设置GOMEMLIMIT环境变量
os.Setenv("GOMEMLIMIT", fmt.Sprintf("%d", goMemoryLimit))
// 或者使用debug包设置
debug.SetMemoryLimit(int64(goMemoryLimit))
}
// 动态调整内存限制
func adjustMemoryLimit() {
go func() {
ticker := time.NewTicker(time.Minute)
defer ticker.Stop()
for range ticker.C {
var m runtime.MemStats
runtime.ReadMemStats(&m)
// 根据内存使用情况动态调整GC参数
if m.Alloc > m.Sys*0.7 { // 内存使用超过70%
// 降低GOGC值,更频繁GC
os.Setenv("GOGC", "50")
} else if m.Alloc < m.Sys*0.3 { // 内存使用低于30%
// 提高GOGC值,减少GC频率
os.Setenv("GOGC", "200")
}
}
}()
}容器环境下的GC调优需要考虑资源限制和性能要求的平衡。
GC参数调优:GOGC设置(根据容器内存限制调整GC触发频率)、GC目标百分比(在内存限制下优化GC目标)、并发GC(利用容器多核特性)、GC停顿时间(在容器环境下控制GC停顿)和内存分配优化(减少内存分配频率)。
容器GC优化策略:低内存环境(设置较低的GOGC值,更频繁GC)、高内存环境(设置较高的GOGC值,减少GC开销)、CPU密集型(减少GC对CPU的影响)、内存密集型(优化内存分配模式)和混合负载(平衡GC频率和性能)。
OOM(Out of Memory)是容器环境下的常见问题,需要建立完善的预防和处理机制。
OOM预防策略:合理设置内存限制(根据应用实际需求设置内存限制)、内存监控(实时监控内存使用情况)、GC优化(优化GC参数减少内存压力)、内存泄漏检测(定期检测内存泄漏)和资源预留(为系统和其他进程预留足够内存)。
OOM处理机制:优雅降级(在内存不足时降低服务质量)、数据持久化(及时保存重要数据)、服务重启(配置自动重启策略)、告警通知(及时通知运维人员)和日志记录(记录OOM事件和上下文信息)。
OOM处理示例:
// OOM预防和处理
func handleOOM() {
// 设置内存限制
memoryLimit := getContainerMemoryLimit()
debug.SetMemoryLimit(int64(memoryLimit * 0.8))
// 监控内存使用
go func() {
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for range ticker.C {
var m runtime.MemStats
runtime.ReadMemStats(&m)
// 内存使用超过90%时采取措施
if m.Alloc > memoryLimit*0.9 {
log.Printf("内存使用过高: %d/%d bytes", m.Alloc, memoryLimit)
// 强制GC
runtime.GC()
// 清理缓存
clearCache()
// 发送告警
sendAlert("内存使用过高")
}
// 内存使用超过95%时紧急处理
if m.Alloc > memoryLimit*0.95 {
log.Printf("内存使用危急: %d/%d bytes", m.Alloc, memoryLimit)
// 停止非关键服务
stopNonCriticalServices()
// 保存重要数据
saveImportantData()
// 准备重启
prepareRestart()
}
}
}()
}
// 清理缓存
func clearCache() {
// 清理应用缓存
cache.Clear()
// 清理对象池
objectPool.Clear()
// 清理临时数据
clearTempData()
}
// 停止非关键服务
func stopNonCriticalServices() {
// 停止后台任务
stopBackgroundTasks()
// 停止定时器
stopTimers()
// 关闭非关键连接
closeNonCriticalConnections()
}
// 保存重要数据
func saveImportantData() {
// 保存用户会话
saveUserSessions()
// 保存处理中的数据
saveProcessingData()
// 保存配置信息
saveConfiguration()
}
// 准备重启
func prepareRestart() {
// 记录重启原因
log.Printf("准备重启,原因:内存使用过高")
// 保存状态
saveApplicationState()
// 通知外部系统
notifyExternalSystems("restart")
// 优雅关闭
gracefulShutdown()
}容器内存管理最佳实践:
# Docker Compose配置示例
version: '3.8'
services:
myapp:
image: myapp:latest
environment:
- GOMEMLIMIT=400Mi
- GOGC=100
deploy:
resources:
limits:
memory: 512M
reservations:
memory: 256M
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
