
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
回答:
HashMap 基于哈希表实现,通过键的 hashCode 值定位元素在数组中的位置,处理哈希冲突时使用链表或红黑树结构来提升性能。
分析:
HashMap 是 Java 中最常用的 Map 实现,其核心思想是"通过哈希函数将 key 映射为数组下标,再通过数组存取 value"。
当调用 put(key, value) 时,HashMap 首先会调用 hash() 方法对 key 进行扰动计算,生成较为均匀的哈希值,然后通过取模操作映射到数组的某个位置。如果当前位置为空,直接插入;否则判断该位置是否存在相同 key(通过 equals 判断)。
若存在则覆盖,否则形成链表或树结构。自 JDK 1.8 起,当链表长度超过 8 且桶数组长度大于 64 时,链表结构将自动转换为红黑树,以提升查询效率。在读取操作中,如 get(key),HashMap 会根据 hash 定位数组,再遍历链表或红黑树查找目标 key,查找到后返回对应 value。这种设计结合了数组的快速访问与链表/树结构的冲突解决能力,实现了空间与效率的平衡。
在 HashMap 中,key 为 null 是一个被显式支持的特性。内部在调用 put(null, value) 时,会直接将 key 为 null 的键值对存入数组的第一个位置(即下标 0 处)。
这是通过在 hash() 方法中对 null 做特殊处理实现的:若 key 为 null,哈希值直接为 0,绕过了 hashCode 的调用。
虽然 HashMap 支持一个 null key,但由于 key 的唯一性原则,再次插入 null 会覆盖已有值。value 值方面,HashMap 支持任意多个 null value。这个特性在某些场景下非常有用,例如初始化缓存、延迟加载等。但需要注意,其他一些 Map 实现如 Hashtable、ConcurrentHashMap 出于线程安全考虑并不允许 key 为 null。
大的方向有两个:
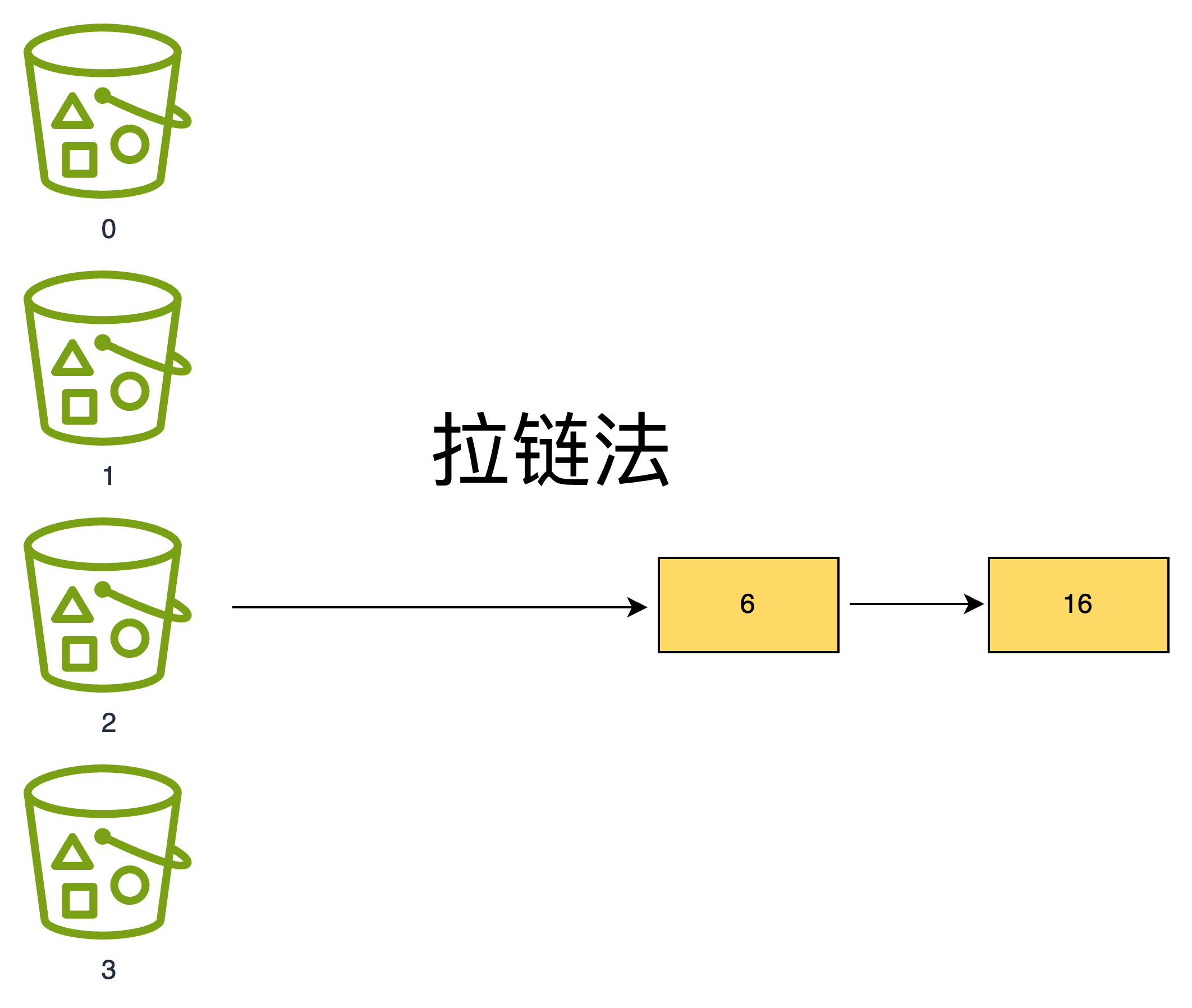
1.拉链法,又称链地址法,其思路很直接:哈希表底层是数组,当不同元素计算出相同索引时,就在该数组位置挂一个链表,把所有冲突元素都存到这个链表中。查询时,先定位到数组索引,再遍历链表找到对应元素。
Java 中的 HashMap 就是拉链法典型例子,Java 7 中,HashMap 解决哈希冲突仅依赖「数组 + 单向链表」结构,冲突元素通过头插法加入链表,Java 8则做了优化,引入了红黑树 优化长链表性能,同时改用尾插法,不用再翻转顺序,解决了链表环问题。
2.开放地址法,属于另一种思路:发生冲突时,不额外创建链表,而是在哈希表内部重新寻找空闲位置存储元素。
比如线性探测法,若索引 i 冲突,就检查 i+1、i+2…… 直到找到空位。这种方法不需要额外指针空间,内存利用率高,但容易出现 “聚集现象”—— 连续的空位被占用后,新元素需要探测更远的位置,导致效率下降,而且删除元素时不能直接清空位置,因为可能破坏探测链,需要做标记处理,没有拉链法直观。
Java 7 中,HashMap 采用「数组 + 链表」的结构存储数据:当哈希冲突时,相同哈希值的元素会被放入同一条链表中。但随着链表长度增加,查询效率会从 O (1) 退化到 O (n)(需遍历链表)。
Java 8 对此进行了关键改进:当链表长度超过阈值(默认 TREEIFY_THRESHOLD = 8),且数组容量不小于 MIN_TREEIFY_CAPACITY = 64 时,会将链表转换为红黑树(一种自平衡二叉查找树)。红黑树的查询、插入、删除效率为 O (log n),远高于长链表的 O (n),大幅优化了哈希冲突严重时的性能。
关键函数如下,从该代码我们能看出根据容量,会做对应的策略选择:
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 若数组容量不足64,先扩容而非树化
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 链表转红黑树的具体实现
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab); // 执行树化操作
}
}同时,当红黑树中的元素数量减少到 UNTREEIFY_THRESHOLD = 6 时,会自动退化为链表,平衡树结构的维护成本。
哈希算法的核心目标是让元素在 HashMap 数组中分布更均匀,减少哈希冲突(即不同元素被分到同一个数组位置)。Java 8 对哈希值的计算逻辑做了关键优化,我们通过具体例子来拆解:
HashMap 中,元素的数组下标由「哈希值 & 数组长度 - 1」计算得出(类似取模运算,但更高效)。例如:
数组长度为 16(二进制1111)时,下标 = 哈希值 & 15(只保留哈希值的低 4 位)。
如果两个元素的哈希值低 4 位相同,就会产生冲突,被放入同一个链表 / 红黑树。
Java 7 为了让哈希值更分散,对key.hashCode()做了4 次扰动(右移 + 异或),代码大致如下:
int h = key.hashCode();
h = h ^ (h >>> 20) ^ (h >>> 12);
h = h ^ (h >>> 7) ^ (h >>> 4); // 最终哈希值Java 8 仅用1 次扰动就达到了类似效果,代码是:
int h = key.hashCode();
int hash = h ^ (h >>> 16); // 核心优化这么做的原理是这样的:
先看h >>> 16:将哈希值的高 16 位右移到低 16 位(高位信息保留,低位被丢弃)。
整体h ^ (h >>> 16):让高 16 位与低 16 位 "异或"(相同为 0,不同为 1),相当于把高位信息 "混合" 到低位中。
原哈希值 h:1010 1100 0011 1010 0001 0110 1100 0101
高16位右移后:0000 0000 0000 0000 1010 1100 0011 1010
异或结果 hash:1010 1100 0011 1010 1011 1001 1111 1111可以看到,最终的hash既保留了高 16 位的特征,又让低 16 位更混乱,减少了因 "低 16 位重复" 导致的冲突。
实际测试中,这种简化几乎不增加冲突率,但哈希值计算速度提升明显,尤其在高频插入 / 查询场景下,能间接优化 HashMap 的整体性能。
在 HashMap 中,将 hash 值映射为数组索引时,使用 hash & (table.length - 1) 而非传统的 hash % length。
这要求数组长度必须为 2 的幂次方,因为只有这样才能确保每一位都参与哈希映射,分布更加均匀,避免哈希冲突集中。
同时,& 操作比 % 运算速度快,能提升整体性能。若数组长度不是 2 的幂次,则位与运算不能正确替代取模操作,导致分布不均甚至数组越界,因此 JDK 内部强制将容量调整为 2 的幂。
负载因子(loadFactor)是衡量 HashMap 空间使用效率的关键参数,其定义是:实际存储元素数 ÷ 数组容量,值越大,数组使用越充分,但冲突概率上升,链表/树结构加长,降低查询效率,反之,负载因子越小,查找快但浪费空间。
JDK 选择 0.75 这一经验值,是经过大量性能测试得出的权衡结果——在实际业务中能达到较好的查找效率,又不会因频繁扩容而增加性能开销。若有特殊场景,可通过构造函数手动设置更适配的负载因子。
HashMap 的默认容量为 16(2^4),这一数值不是随意选择的,而是根据实际应用中的负载均衡与性能表现做出的折中。
容量过小(如 4 或 8)在面对较多元素时容易频繁扩容,影响性能;过大则会导致内存浪费。16 是一个恰当的起点:结合默认负载因子 0.75,首次扩容会在存入 12 个元素后触发,既保障性能,又利于控制空间开销。
此外,16 是 2 的幂次,便于 hash 计算。JDK 虽未在文档中显式说明原因,但这是一种基于历史实践的合理经验值。
Java 8 为提升 HashMap 在高冲突场景下的查找效率,引入了链表转红黑树的机制。当某个桶中的链表节点数超过 8 且数组长度超过 64 时,链表将转为红黑树。
这一阈值并非随意设定,而是基于泊松分布等实证数据得出的结论:哈希碰撞超过 8 次的概率非常小,若真的发生了,说明哈希算法或 key 分布存在问题,此时使用红黑树可显著提升查找性能。
而红黑树转链表的阈值设为 6,是为了避免在节点数反复波动于 7 附近时频繁切换树与链表。
AVL 树在插入/删除操作后保持严格的高度平衡,虽然查找效率略高于红黑树,但为了保持这种平衡,其插入删除时需频繁做旋转,代价较大。
而红黑树在保持大致平衡的基础上,通过颜色标记限制最长路径,结构调整相对简单,插入删除开销小。
在 HashMap 的应用场景中,更多关注的是插入性能与平均查找效率的平衡,极端场景也较少,因此红黑树是更合适的选择。JDK 也广泛采用红黑树作为 TreeMap、TreeSet、ConcurrentSkipListMap 等结构的底层实现。
HashMap 的本质是"数组 + 链表/红黑树"的结构。当元素数量增加、哈希冲突增多时,多个键可能落入同一个桶内,形成链表结构。
此时查询效率将从 O(1) 降为 O(n),如果是红黑树则为 O(log n),依然存在性能下降问题。扩容通过将底层数组容量翻倍,并重新映射已有元素,降低每个桶的负载,从而提升平均访问速度。
Java 8 中的优化更进一步,在扩容时并不重新计算元素的 hash 值,而是通过新增的一位 hash bit 来判断元素是留在原索引还是转移到"原索引 + oldCap"位置,实现高效迁移。
HashMap 扩容是为了解决容量不足引起的哈希冲突。其扩容触发主要有两个条件:
一个是整体元素数量超过 threshold = capacity × loadFactor(默认为 16×0.75=12)。
loadFactor就是负载因子,是衡量 HashMap 空间使用效率的关键参数。负载因子值越大,数组使用越充分,但冲突概率上升,链表/树结构加长,降低查询效率。反之,负载因子越小,查找快但浪费空间。
JDK 选择 0.75 这一经验值,是经过大量性能测试得出的权衡结果——在实际业务中能达到较好的查找效率,又不会因频繁扩容而增加性能开销。若有特殊场景,可通过构造函数手动设置更适配的负载因子。
另一个是在 Java 8 中,如果单个桶内链表长度达到 8 且当前数组长度小于 64,也会触发扩容而非转红黑树。
扩容时,HashMap 会将原数组中的元素重新计算 hash 后搬迁到新数组,扩容代价较大,因此应尽量通过构造函数提前指定合适初始容量,减少 resize 次数,提升性能。
HashMap 的默认容量为 16(2^4),这一数值不是随意选择的,而是根据实际应用中的负载均衡与性能表现做出的折中。容量过小,比如4或8,在面对较多元素时容易频繁扩容,影响性能;
过大则会导致内存浪费,16 是一个恰当的起点:结合默认负载因子 0.75,首次扩容会在存入 12 个元素后触发,既保障性能,又利于控制空间开销。此外,16 是 2 的幂次,便于 hash 计算。JDK 虽未在文档中显式说明原因,但这是一种基于历史实践的合理经验值。
这个问题,1.8版优化之后,其实有点晦涩。
我们用生活场景 + 二进制计算结合的方式,彻底讲透这个优化点。先记住一个核心前提:HashMap 的数组长度永远是 2 的幂(如 16、32、64...),扩容时直接翻倍。
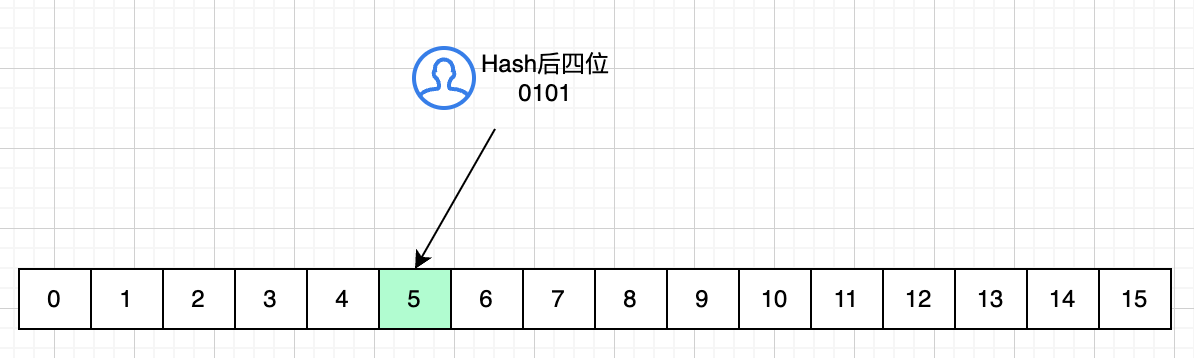
场景类比:给学生排座位,假设学校的教室座位是 “2 的幂” 排列:
初始有 16 个座位(编号 0-15),学生按 “学号的后 4 位” 找座位(比如学号后 4 位是 0101,坐 5 号)。
后来学生变多,座位扩容到 32 个(编号 0-31),此时需要重新排座位,Java 7 和 Java 8 的区别,就像两种不同的排座位方式。
原来 16 个座位时,按 “学号后 4 位” 排(如学号xxxx0101→5 号)。
扩容到 32 个座位后,Java 7 要求重新计算学号(比如把原学号打乱重算),再按 “新学号的后 5 位” 排座位(如yyyy10101→21 号)。
这里的 “重新计算学号” 就是 Java 7 的问题:明明只是座位变多了,却要重复计算哈希值(类似重算学号),完全没必要。
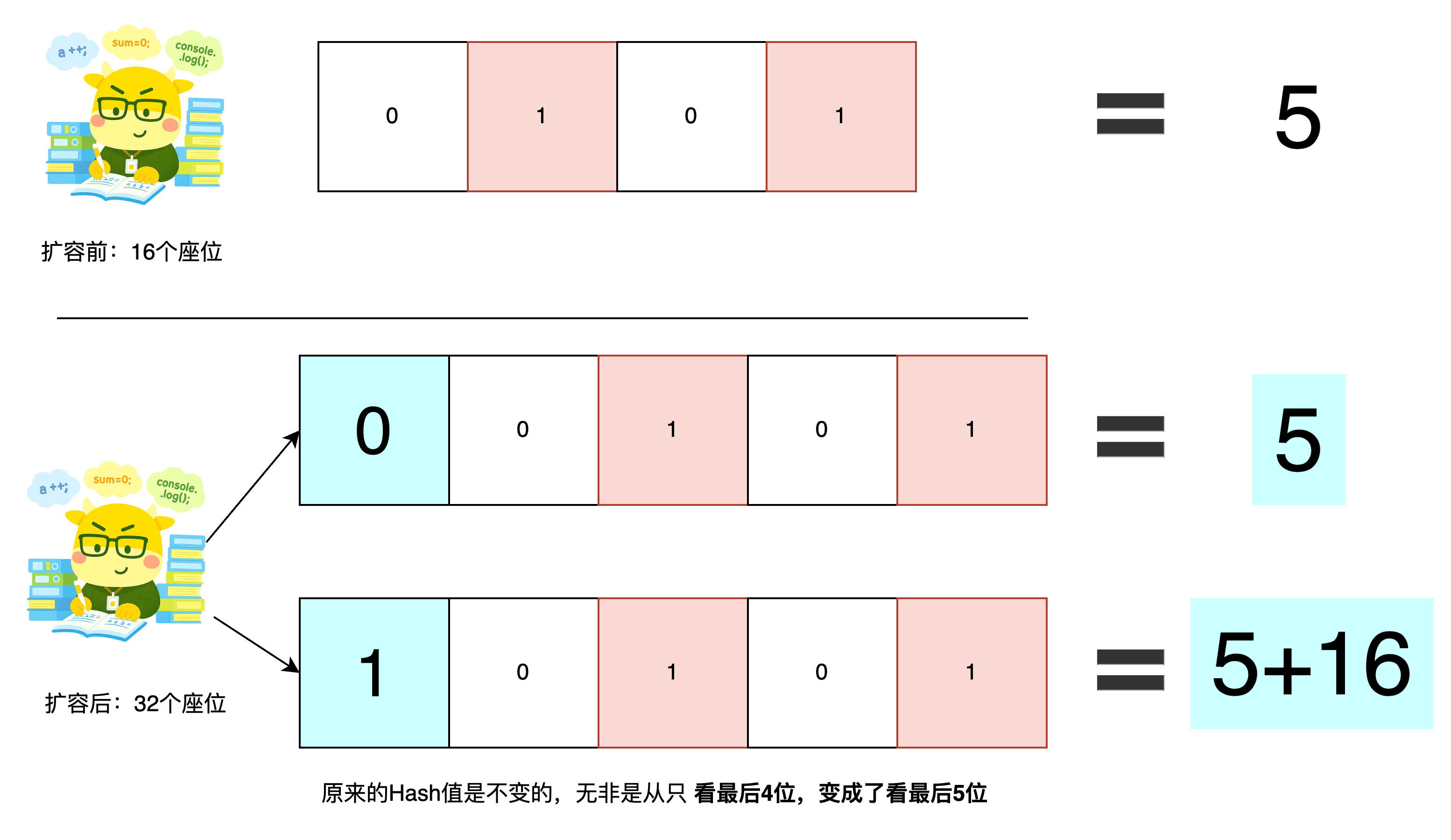
Java 8 发现,座位从 16→32,本质是座位编号从 “4 位二进制”(0000-1111)变成 “5 位二进制”(00000-11111)。新增的第 5 位(最高位)决定了新座位的位置。
用二进制具体计算:
原座位(16 个):位置 = 哈希值 & 15(15 是 16-1,二进制1111),本质是取哈希值的低 4 位(如哈希值低 4 位0101→5 号)。
扩容后(32 个座位):新位置 = 哈希值 & 31(31 是 32-1,二进制11111),本质是取哈希值的低 5 位。
对比原位置和新位置的低 5 位:
前 4 位和原位置的低 4 位完全相同(比如原低 4 位0101,新低 5 位可能是00101或10101)。
唯一的区别是新增的第 5 位(从右数第 5 位):
若第 5 位是0 → 新位置 = 原位置(如00101→5 号)。
若第 5 位是1 → 新位置 = 原位置 + 16(旧长度,也就是多的那个1)(如10101→5+16=21 号)。
原哈希值已经包含了所有信息,没必要重新计算(就像学号没变,只是座位变多了,不用重算学号)。
只需判断哈希值中 “旧长度对应的那一位”(16 对应的是第 4 位,32 对应的是第 5 位),1 次判断就能确定新位置,比 Java 7 的 “重算哈希 + 重新计算位置” 快得多。
Java 8 的优化本质是:利用 “数组长度翻倍” 的特性,通过哈希值中 “新增的一位” 直接确定新位置,避免重复计算哈希。就像从 “4 位数座位号” 变 “5 位数” 时,只需看第 5 位是 0 还是 1,就能快速找到新座位,既简单又高效。
HashMap 与 HashTable 都是基于哈希表实现的 key-value 容器。HashMap 出现在 JDK 1.2,取代 HashTable 成为主流,主要区别包括:
1)线程安全性:HashTable 所有方法都加了 synchronized,适用于单线程但性能低;HashMap 默认非线程安全,适用于单线程或外部同步场景;
2)key/value 支持:HashMap 允许 key 为 null,HashTable 不允许;
3)扩容机制:HashMap 默认容量为 16,扩容为 2 倍;HashTable 初始容量为 11,扩容为原来的 2 倍 + 1;
4)hash 实现:HashMap 使用扰动函数增强 hash 分布,HashTable 直接使用原始 hashCode。综合来看,HashMap 更现代、灵活,而 HashTable 已逐渐被淘汰。
想象这样的场景:你需要存储用户的操作记录,既要能快速通过操作 ID 查找详情,又要能按用户操作的先后顺序遍历记录。这时 HashMap 虽然查询快但无序,TreeMap 虽然有序但查询效率稍低,而 LinkedHashMap 正好能满足这两个需求。
LinkedHashMap 继承自 HashMap,因此拥有 HashMap 的所有功能(如 key 去重、哈希存储等),但额外提供了顺序性—— 可以按元素的插入顺序或访问顺序遍历,完美结合了哈希表的高效和链表的有序特性。
// 示例:按插入顺序遍历
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
map.put("a", 1);
map.put("b", 2);
map.put("c", 3);
// 遍历结果与插入顺序一致
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey()); // 输出 a → b → c
}LinkedHashMap 的底层结构是哈希表 + 双向链表 的混合体:
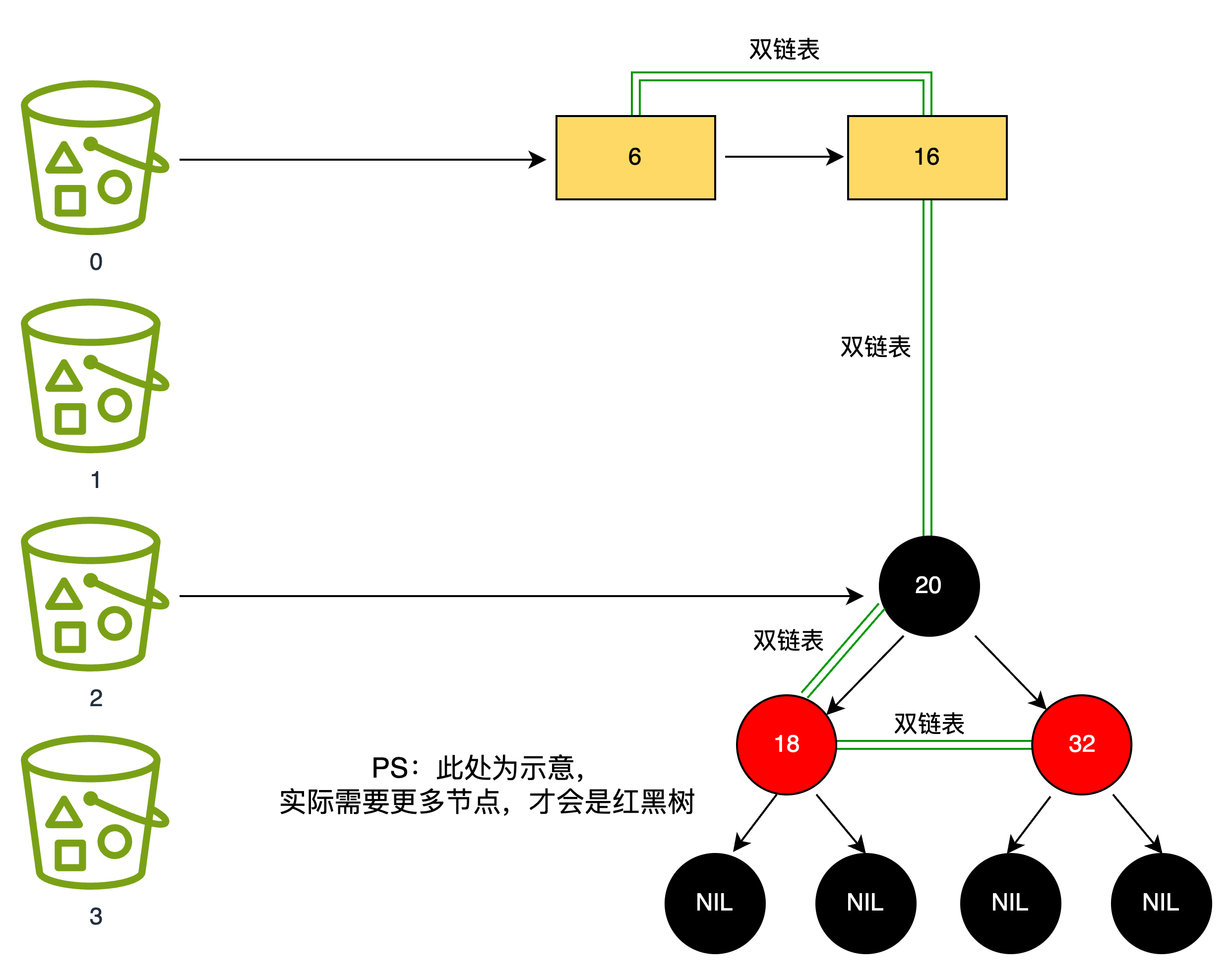
哈希表:与 HashMap 相同,由数组 + 链表 / 红黑树组成,用于通过 key 的哈希值快速定位元素,保证 get/put 等操作的时间复杂度为 O (1)。
双向链表:这是 LinkedHashMap 独有的部分,通过每个节点的 before 和 after 指针,将所有元素按特定顺序(插入或访问顺序)连接起来,实现有序遍历。节点结构关键部分源码:
// LinkedHashMap 的节点类,继承自 HashMap 的 Node
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 双向链表的前后指针
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next); // 继承 HashMap 节点的哈希表指针
}
}可以看出,每个节点既包含哈希表所需的 next 指针(用于解决哈希冲突),又包含双向链表的 before 和 after 指针(用于维护顺序)
想象一个场景:你需要存储一批员工的 ID 和姓名,并且经常要按 ID 从小到大遍历,或者快速找到 ID 在某个区间的员工。如果用 HashMap,每次遍历前都要手动对键进行排序,既麻烦又影响效率。
而 TreeMap 正是为这种需求设计的 —— 它会在你添加元素时自动按 key 排序,遍历的时候直接就是有序的,省去了手动排序的步骤。
// 用 HashMap 存储,遍历是无序的
Map<Integer, String> hashMap = new HashMap<>();
hashMap.put(3, "张三");
hashMap.put(1, "李四");
hashMap.put(2, "王五");
System.out.println(hashMap.keySet()); // 输出可能是 [1, 2, 3] 或 [3, 1, 2] 等随机顺序
// 用 TreeMap 存储,自动按 key 排序
Map<Integer, String> treeMap = new TreeMap<>();
treeMap.put(3, "张三");
treeMap.put(1, "李四");
treeMap.put(2, "王五");
System.out.println(treeMap.keySet()); // 一定输出 [1, 2, 3]TreeMap 之所以能做到有序且高效,全靠它底层的红黑树数据结构,红黑树需要满足节点规则:
这些规则保证了红黑树的 "平衡" 特性 —— 最长路径不超过最短路径的 2 倍,从而维持 O (log n) 的查询效率,下面就是一张红黑树的示意图:
红黑树还有两个关键特性:
二叉搜索树特性:左子树的所有 key 都小于根节点的 key,右子树的所有 key 都大于根节点的 key。这保证了按 “左 - 根 - 右” 顺序遍历(中序遍历)时,能得到有序的 key 序列。
自平衡特性:通过 “变色” 和 “旋转”(左旋、右旋)操作,保证树的高度始终是 O (log n)(n 为元素数量)。这意味着无论插入、查询还是删除元素,效率都很稳定,不会像普通二叉树那样在极端情况下退化成链表(导致效率骤降)。
简单说,红黑树就像一个智能书架:新放进去的书会自动插到合适的位置(保证有序),而且书架永远不会长得 “歪歪扭扭”(保证高效操作)。
三者的选择应根据实际需求决定:若只关注性能选 HashMap;需要顺序则用 LinkedHashMap;需排序与范围查找则选 TreeMap。需要线程安全版本时,推荐使用 ConcurrentHashMap 或同步包装类。
JDK1.8 中的 ConcurrentHashMap 通过无锁+细粒度加锁的混合机制,实现了高效线程安全的 put 操作。整体流程是惰性初始化 + 分段插入 + 局部加锁,既兼顾并发性能,又保证数据一致性。
当我们调用 put 方法时,ConcurrentHashMap 首先会判断底层桶数组(Node[] table)是否已初始化,如果尚未初始化,会触发懒加载过程。接下来根据 key 的 hash 值定位出应该落入的桶位。若目标位置为空,会尝试用 CAS 操作直接写入新的节点,这一步无需加锁,是并发安全的。
若该位置已经有节点存在,说明发生了 hash 冲突。此时需要判断当前节点结构类型:如果是链表,则对该 bin 头节点加锁,然后遍历链表,查找是否已存在相同 key,若存在则更新其值;若不存在则插入新节点。如果 bin 已经树化为红黑树,则按照红黑树的插入规则处理,同样在同步块中进行。
此外,在插入新节点后,ConcurrentHashMap 会更新总元素数量,并评估是否需要进行扩容。若达到阈值,将由当前线程或其他线程协助执行扩容逻辑,这是一种渐进式的协作扩容方式,避免阻塞。
整套机制体现了 JDK1.8 对并发控制的精细设计:尽可能用 CAS 减少锁竞争,必要时局部加锁来保持一致性,在高并发环境下能显著提升性能表现。
ConcurrentHashMap 是 Java 为并发场景专门设计的线程安全 Map 实现。在 JDK 1.7 中,它采用分段锁 Segment 技术,每段独立加锁,允许多个线程并发访问不同段,极大提升并发性能。
而 JDK 1.8 弃用 Segment,改为 Node + CAS + synchronized 的无锁+锁结合机制,读操作尽可能无锁,写操作使用 synchronized 保证一致性。
其底层结构也引入红黑树优化冲突严重的桶位,提高效率。相比之下,HashTable 对整个对象加锁(synchronized 全方法),即便访问不同 key 也无法并发,性能较差。综上,ConcurrentHashMap 在并发性能、粒度控制与现代化设计上全面优于 HashTable。

