
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
map 不是线程安全的。如果某个任务正在对map进行写操作,那么其他任务就不能对该字典执行并发操作(读、写、删除),否则会导致进程崩溃。在查找、赋值、遍历、删除的过程中都会检测写标志,一旦发现写标志等于1,则直接 fatal 退出程序。
map的并发安全问题是一个经常被忽视但又极其重要的问题。在Go语言中,map的并发不安全主要体现在写操作上。当我们对map进行并发读写时,如果不加锁保护,很容易触发一个特殊的错误:concurrent map writes。这个错误的特点是它会导致程序直接崩溃,而且无法被recover捕获,这在实际生产环境中是非常危险的。
从底层实现来看,map在运行时维护了一个写标志位。当进行写操作时,会先检查这个标志位是否为0,如果是0则将其设置为1,然后执行写操作,最后再将其恢复为0。如果在写操作过程中,其他goroutine也尝试进行写操作,就会检测到标志位为1,此时就会触发panic。
这种设计其实很好理解,因为map的底层是一个哈希表,在扩容、rehash等操作时,需要保证数据的一致性。如果允许多个goroutine同时写入,可能会导致数据错乱,甚至破坏map的内部结构。
在实际开发中,我经常看到一些开发者对map的并发安全性认识不足,导致在生产环境中出现难以排查的问题。因此,我建议在使用map时,如果存在并发访问的场景,一定要使用sync.Map或者加锁来保护map的访问。这也是为什么Go语言在标准库中提供了sync.Map这个并发安全的map实现。
从性能角度来说,如果确实需要使用map,而且并发访问的场景不是特别多,使用互斥锁保护map也是一个不错的选择。但如果是高并发场景,特别是读多写少的场景,使用sync.Map会是更好的选择,因为它的设计就是针对这种场景优化的。
map的遍历是无序的。每次遍历时,都会从一个随机序号的桶开始,在每个桶中,再从随机槽位开始遍历。这种设计是Go语言刻意为之,目的是避免开发者对遍历顺序产生依赖。
在Go语言的map实现中,遍历过程分为两个随机步骤:首先随机选择一个桶号,然后随机选择一个槽位。这种双重随机性确保了遍历的完全无序性。具体来说,map在遍历时会维护一个随机种子,每次遍历都会使用这个种子生成一个随机数,用来决定从哪个桶开始遍历。
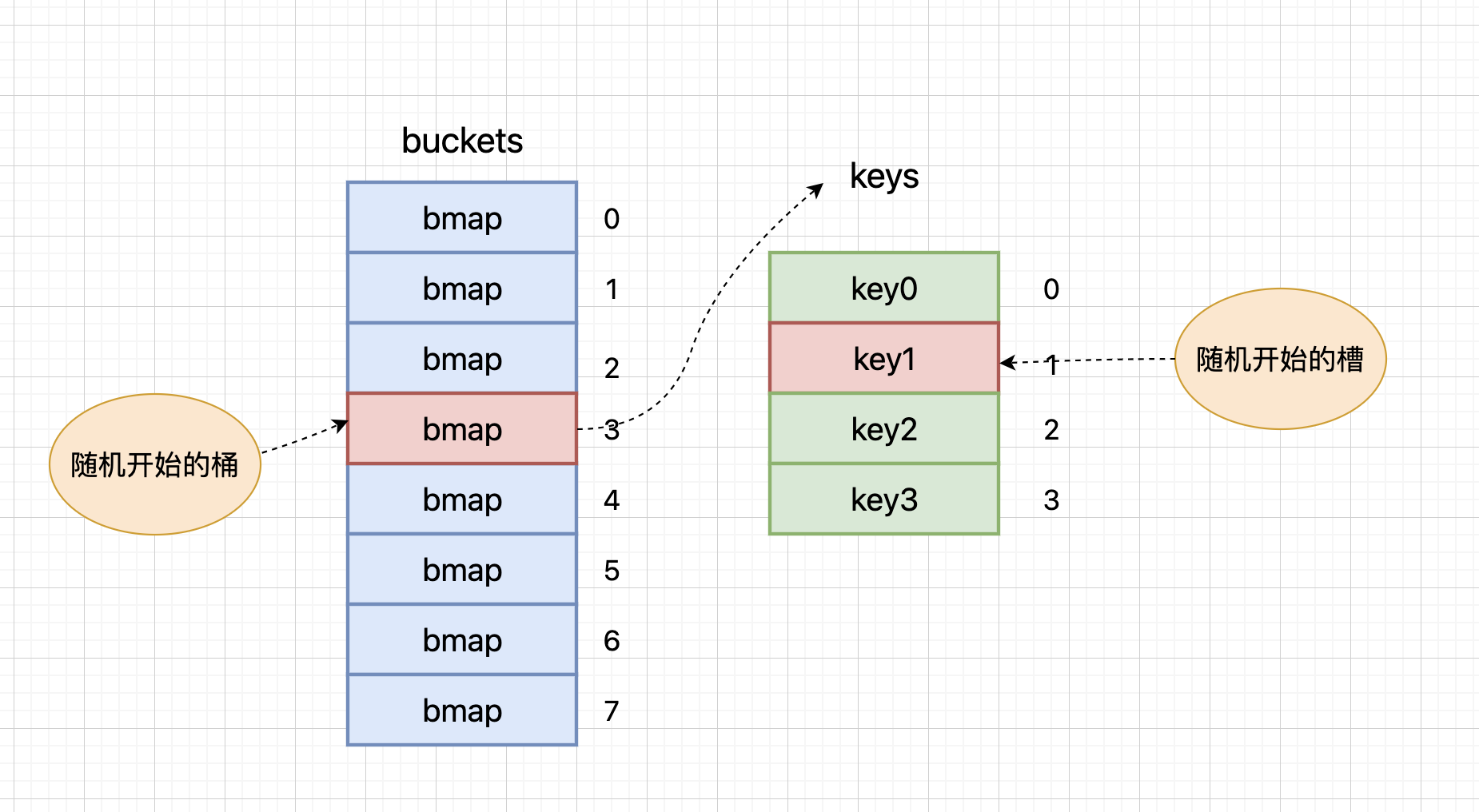
这种设计的主要原因是map的扩容机制。当map发生扩容时,key的位置会发生改变。如果遍历是有序的,那么在扩容前后,遍历的顺序就会发生变化,这可能会导致一些难以排查的问题。通过强制每次遍历都随机开始,Go语言实际上是在提醒开发者:不要依赖map的遍历顺序。
在实际开发中,我经常遇到一些开发者试图依赖map的遍历顺序,这往往会导致一些难以排查的bug。比如,有些开发者可能会假设map的遍历顺序是固定的,并基于这个假设编写代码。当map发生扩容时,这些代码就会出现问题。
从性能角度来说,map的无序遍历实际上是有好处的。它避免了在遍历过程中维护顺序的开销,使得遍历操作更加高效。这也是为什么Go语言的设计者选择让map的遍历保持无序的原因之一。
map的顺序读取是一个常见的需求,特别是在需要保证输出结果一致性的场景中。虽然Go语言的map本身是无序的,但我们可以通过一些技巧来实现顺序读取。
让我来详细解释一下实现顺序读取的具体步骤:
这里是一个具体的实现示例:
func orderedMapIteration(m map[string]int) {
// 创建key切片
keys := make([]string, 0, len(m))
// 收集所有key
for k := range m {
keys = append(keys, k)
}
// 对key进行排序
sort.Strings(keys)
// 按序遍历map
for _, k := range keys {
fmt.Printf("key: %s, value: %d\n", k, m[k])
}
}从性能角度来说,这种方法的开销主要来自两个方面:一是创建切片和收集key的开销,二是排序的开销。如果map的大小较小,这些开销是可以接受的。但如果map很大,或者需要频繁进行顺序读取,我们可能需要考虑其他方案,比如使用有序的数据结构(如红黑树)来替代map。
在实际开发中,我经常看到一些开发者试图通过其他方式来实现map的顺序读取,比如维护一个额外的有序列表。这种方法虽然可行,但会增加代码的复杂度,而且容易出错。相比之下,使用切片和排序的方法更加简单直接,也更容易维护。
需要注意的是,如果map的内容经常变化,每次变化后都需要重新收集key并排序,这可能会带来额外的性能开销。在这种情况下,我们需要权衡是否真的需要顺序读取,或者是否可以使用其他数据结构来满足需求。
不会释放。删除一个key只是将对应位置标记为空,并不会真正释放内存。只有当整个map被置空时,map占用的内存才会被垃圾回收器回收。
在Go语言的map实现中,删除key的过程实际上是一个标记删除的过程。当我们调用delete函数删除一个key时,map会执行以下操作:找到key对应的桶和槽位,将该槽位的key和value设置为空值,将tophash设置为emptyOne(表示该位置为空)。
这种设计类似于数据库中的"软删除",它只是标记了数据的位置为空,但并没有真正释放内存。这样设计的主要原因是避免频繁的内存分配和释放,提高性能;保持map的连续性,避免出现内存碎片;为后续的插入操作提供快速定位空位的能力。
当map中的key被大量删除后,map会进入一个"稀疏"状态。在这种情况下,如果后续有新的key插入,map会优先使用这些被标记为emptyOne的位置,而不是分配新的内存。这种机制可以有效地重用内存,避免不必要的内存分配。
需要注意的是,虽然删除key不会立即释放内存,但这并不意味着map会无限增长。Go语言的垃圾回收器会在适当的时机回收整个map占用的内存。如果map被置为nil,或者不再被引用,垃圾回收器会回收map占用的所有内存。
从性能角度来说,这种设计是合理的。频繁的内存分配和释放会带来较大的性能开销,而标记删除的方式可以避免这些开销。同时,通过重用已分配的内存,map可以保持较好的性能表现。
在实际应用中,如果确实需要释放map占用的内存,我们可以将map置为nil,等待垃圾回收;或者创建一个新的map,将需要的key-value对复制过去;或者使用sync.Map的LoadAndDelete方法,它提供了更细粒度的内存管理。不过,在大多数情况下,我们不需要特别关注map的内存管理,因为Go语言的垃圾回收器会自动处理这些工作。
实现map的并发安全访问主要有五种方案:sync.Map、互斥锁保护、读写锁优化、分段锁map和channel通信。sync.Map是标准库提供的并发安全map,适合读多写少场景;互斥锁方案实现简单但性能较低;读写锁在读多写少场景下性能更好;分段锁map通过减小锁粒度提高并发性能;channel方案利用Go的CSP模型实现无锁访问。选择哪种方案需要根据具体的读写比例、并发量和性能要求来决定。
| 方案 | 实现复杂度 | 性能特点 | 适用场景 | 内存开销 |
|---|---|---|---|---|
| sync.Map | 简单 | 读多写少性能极佳 | 读多写少,不同key访问 | 高 |
| 互斥锁 | 简单 | 全部操作加锁,性能较低 | 低并发,简单场景 | 低 |
| 读写锁 | 中等 | 读多无锁,写操作加锁 | 读多写少 | 中等 |
| 分段锁map | 复杂 | 减小锁粒度,提高并发 | 写多读少,高并发 | 高 |
| channel | 中等 | 无锁访问,CSP模型 | 生产者消费者模式 | 中等 |
在实际应用中,需要根据具体的业务场景、性能要求和开发复杂度来选择合适的方案。
nil map和空map在声明方式、内存占用、操作安全性等方面存在显著区别。
声明和初始化:nil map通过var m map[string]int声明但未初始化,而空map通过m := make(map[string]int)声明并初始化。
内存占用:nil map不占用内存空间,空map会占用一定的内存空间用于存储map的元数据。
操作安全性:nil map不能进行任何读写操作,任何操作都会导致panic;空map可以安全进行所有map操作。
使用场景:nil map适合作为默认值或可选字段,空map适合确定要使用的map场景。
nil map是Go语言中的零值map
// nil map的声明和操作
var m map[string]int // 声明nil map
// 以下操作会导致panic
// m["key"] = 1 // panic: assignment to entry in nil map
// value := m["key"] // panic: runtime error: invalid memory address or nil pointer dereference
// 正确的使用方式
if m == nil {
m = make(map[string]int)
}
m["key"] = 1 // 现在可以安全操作空map是已初始化但无元素的map
// 空map的创建和操作
m := make(map[string]int) // 创建空map
// 可以安全进行所有操作
m["key1"] = 1
m["key2"] = 2
delete(m, "key1")
// 遍历空map(不会执行循环体)
for k, v := range m {
fmt.Printf("key: %s, value: %d\n", k, v)
}
// len()返回0
fmt.Println(len(m)) // 输出: 0函数参数设计:当map参数是可选的,使用nil map作为默认值;当确定需要使用map时,使用空map避免panic。在函数内部检查map是否为nil,决定是否初始化。
结构体字段设计:对于可选字段,使用指针类型*map[string]int可以区分nil和空map;对于必需字段,使用值类型map[string]int确保字段已初始化。在方法中检查字段是否为nil,按需初始化。
内存优化:在内存敏感场景下使用nil map节省内存,按需初始化;在频繁访问场景下使用空map避免重复检查,提高性能。
代码安全:在关键代码中使用空map避免panic,在团队中统一map的使用规范,在代码中明确说明map的预期状态和用途。
错误处理:在使用map前进行nil检查,当map为nil时提供合理的默认行为,记录map的初始化状态便于调试。
回答
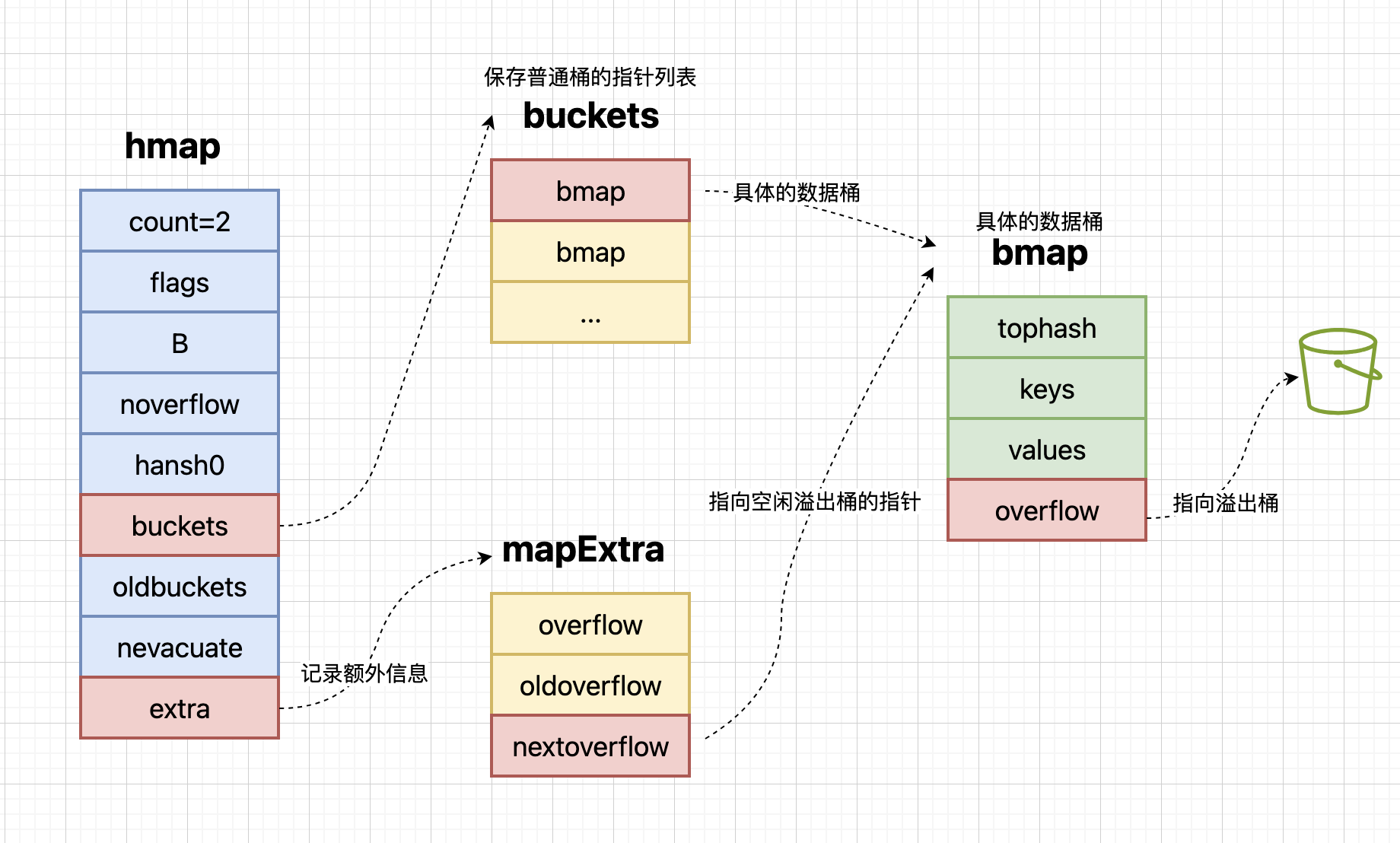
Map的底层实现是一个哈希表,由hmap结构体和bmap结构体组成。hmap包含桶数组指针、溢出桶指针等字段,而bmap是具体的桶结构,可以存储8个键值对。
hmap结构体的主要字段:count(当前map中的元素个数);B(桶数量的对数,桶数量 = 2^B);buckets(指向桶数组的指针);oldbuckets(扩容时指向旧桶数组的指针);extra(指向溢出桶的指针)。
bmap结构体的主要字段:tophash(存储key的哈希值高8位);keys(存储8个key);values(存储8个value);overflow(指向溢出桶的指针)。
查找过程:
计算key的哈希值:使用Go语言内置的哈希函数计算key的哈希值,这个哈希值是一个64位的整数,用于后续的桶定位和快速比较
用哈希值低B位确定桶位置:将哈希值的低B位作为桶数组的索引,B是map中桶数量的对数(桶数量 = 2^B)。这一步确定了key应该存储在哪个桶中
用哈希值高8位(tophash)快速过滤:在桶内,每个槽位都存储了对应key哈希值的高8位。通过比较tophash可以快速过滤掉不匹配的槽位,避免对每个key进行完整的比较操作
在桶内遍历keys数组进行精确匹配:对于tophash匹配的槽位,需要遍历桶内的keys数组,进行完整的key比较。由于桶内最多只有8个key,这个比较过程很快
如果发生冲突,通过overflow指针查找溢出桶:当桶内8个槽位都满了,或者发生哈希冲突时,map会创建溢出桶。通过overflow指针可以链接到下一个溢出桶,继续查找过程,直到找到匹配的key或确认key不存在
map的扩容机制容采用渐进式策略,通过负载因子触发,在操作过程中逐步迁移数据,避免性能抖动。
map的扩容分为两种类型,由不同条件触发:
增量扩容:
等量扩容:
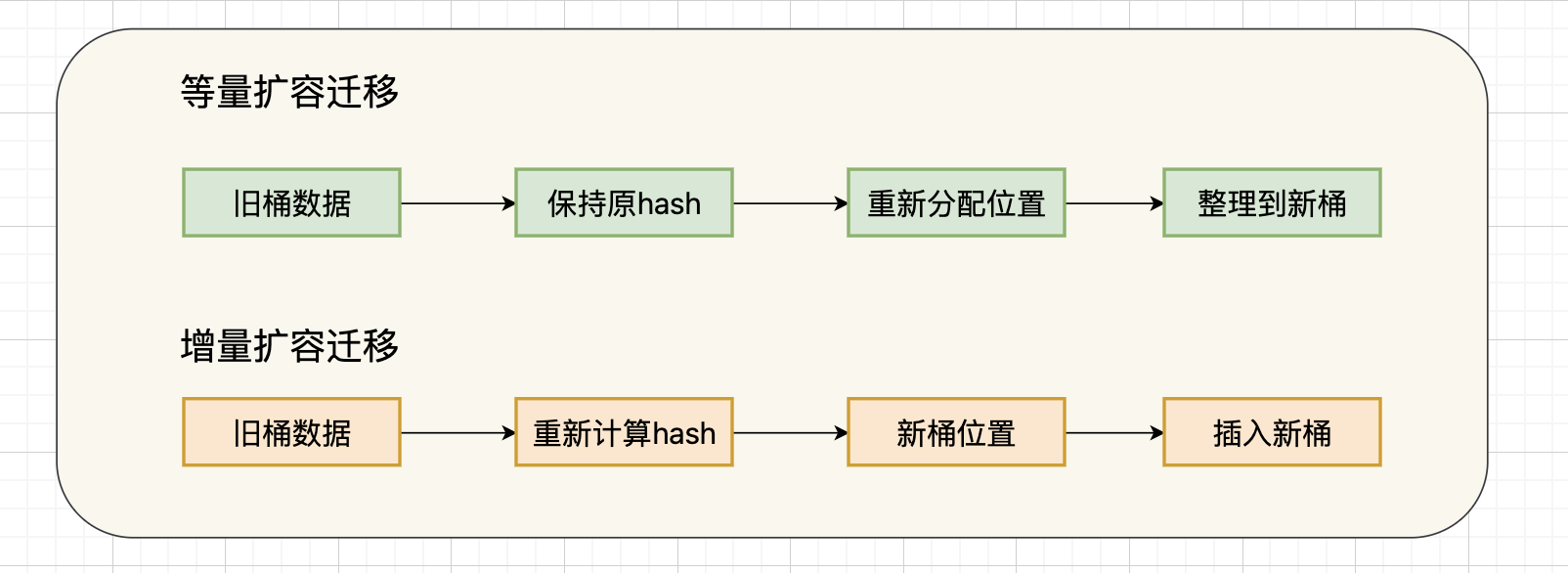
增量扩容的迁移过程:
// 伪代码示例
for each bucket in oldbuckets {
for each key-value pair in bucket {
newHash := hash(key) // 重新计算哈希值
newBucketIndex := newHash & (newB - 1) // 计算新桶位置
insertIntoNewBucket(newBucketIndex, key, value) // 插入新桶
}
}等量扩容的迁移过程:
// 伪代码示例
for each bucket in oldbuckets {
for each key-value pair in bucket {
// 保持原有哈希值,只重新分配桶位置
newBucketIndex := hash(key) & (B - 1) // B值不变
insertIntoNewBucket(newBucketIndex, key, value)
}
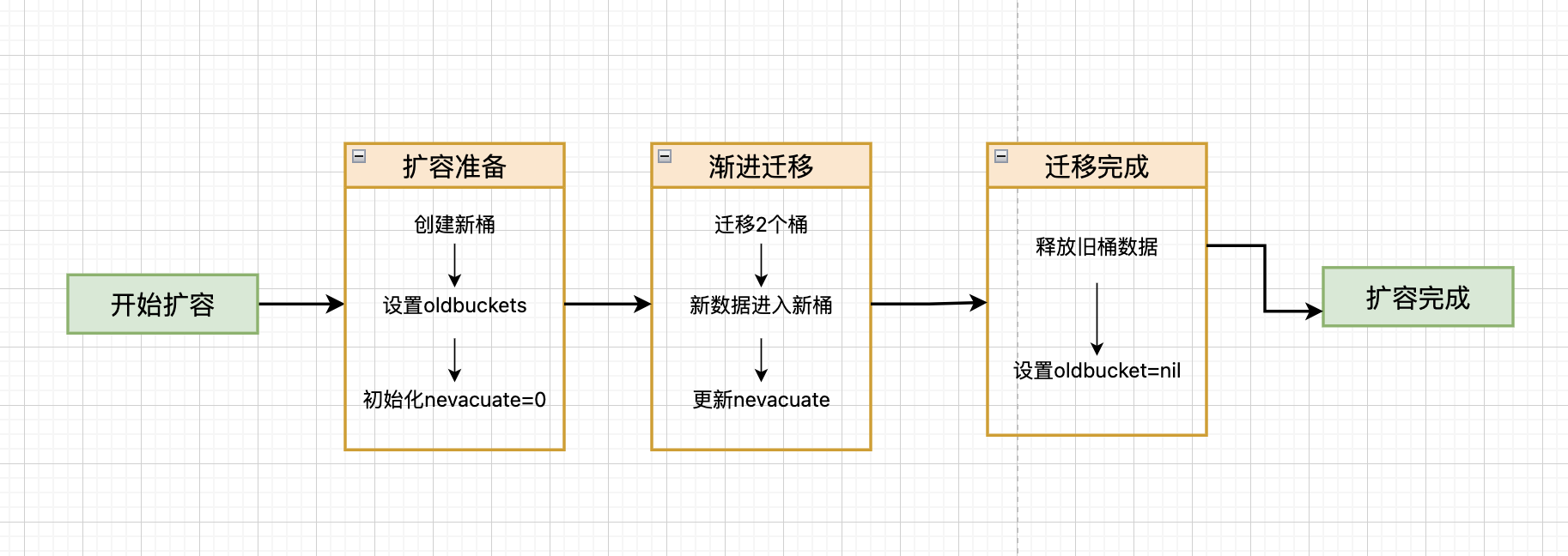
}无论哪种扩容类型,都采用渐进式策略:
扩容准备阶段:
渐进迁移阶段:
迁移完成阶段:
map的key必须是可比较类型,这是因为map在查找、插入和删除操作时,需要通过比较key来确定key的位置。如果key不可比较,就无法判断两个key是否相等,也就无法正确地进行这些操作。
map通过以下步骤查找key对应的value:
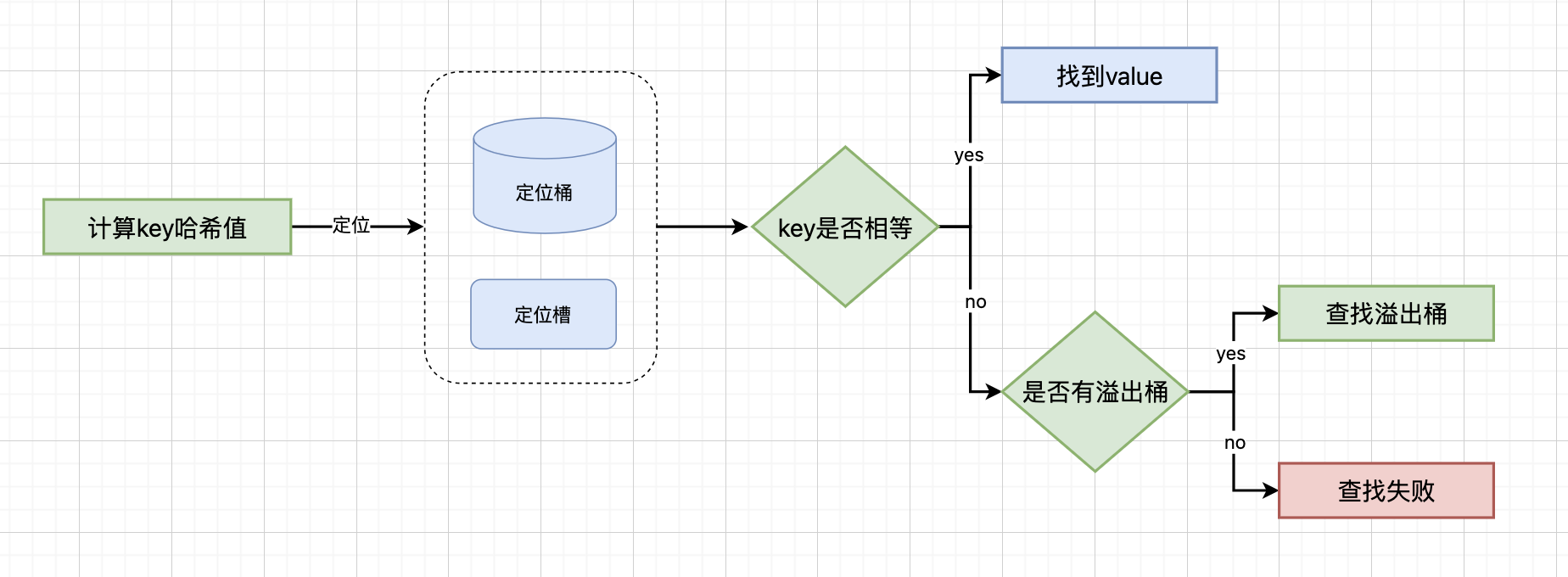
这就是为什么key必须是可比较的:在查找时,需要比较key是否相等;在插入时,需要判断key是否已存在;在删除时,需要确认要删除的key。
sync.Map采用空间换时间的策略,通过维护两个map(read map和dirty map)来实现并发安全。read map可以无锁访问,而dirty map需要加锁访问。这种设计使得读操作在大多数情况下可以无锁进行,大大提高了并发性能。
read map是sync.Map的第一层,具有以下特点:
dirty map是sync.Map的第二层,具有以下特点:
mutex锁专门保护dirty map的访问:
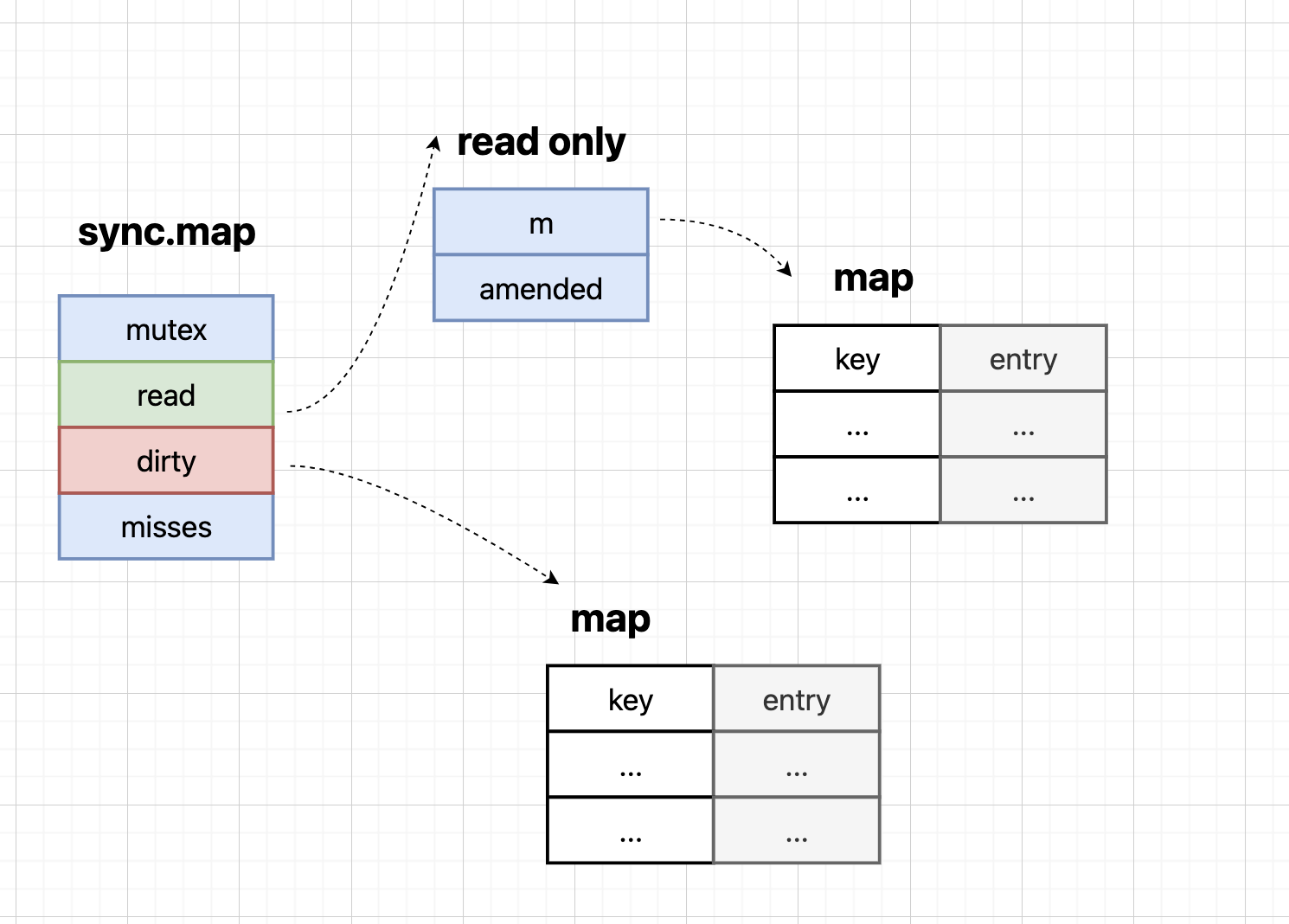
read map和dirty map是sync.Map中的两个核心结构,它们相互配合,共同保证map的并发安全。read map作为保护层,通过原子操作拦截大部分读、更新、删除操作;dirty map作为兜底层,处理read map无法完成的操作。
两个map之间通过精妙的数据流转保持一致性。
初始化阶段:dirty map为空时,从read map复制数据,确保数据完整性。
promotion机制:当read map命中率降低时,dirty map提升为新的read map,这个过程称为"promotion",是sync.Map性能优化的关键机制。
数据同步:确保两个map中的数据始终保持一致,通过原子操作和锁机制保证数据安全。
不同的操作由不同的map处理,这种分工策略是sync.Map高性能的核心。
读操作:优先在read map中查找,无锁访问,大部分读操作都能在这里快速完成。
写操作:在dirty map中处理,需要加锁,确保数据修改的原子性。
删除操作:先在read map中标记,必要时同步到dirty map,通过状态管理机制优化删除性能。
nil和expunged状态的设计是为了优化sync.Map的性能。nil状态表示软删除,可以让删除操作在read map层完成;expunged状态表示硬删除,用于标识key是否存在于dirty map中。
nil状态的设计使得删除操作可以在read map层完成,这大大提高了删除操作的性能。通过将key对应的value设置为nil,我们可以快速标记一个key为已删除状态,而不需要立即进行实际的删除操作。这种设计避免了频繁的加锁操作,提高了并发性能。
expunged状态则是一个更深入的设计,它用于标识key是否存在于dirty map中。当一个key被标记为expunged时,表示这个key已经从dirty map中删除,不需要再进行数据同步。这种设计避免了重复的数据同步操作,优化了内存使用。
sync.Map适用于读多写少的场景,特别是当不同goroutine访问不同的key时。它不适合写操作频繁的场景,因为写操作需要加锁,会导致性能下降。
| 场景类型 | 适用场景 | 不适用场景 |
|---|---|---|
| 读写比例 | 读多写少 | 写操作频繁 |
| 并发模式 | 不同key访问 | 并发写入 |
| 数据特征 | 频繁读取 | 数据量大 |
| 性能表现 | 性能优势 | 性能劣势 |
核心适用场景:当读操作远多于写操作时,大部分操作都可以通过无锁的read map完成,性能优势非常明显。这种场景下,不同goroutine访问不同的key,read map的无锁特性得到充分发挥,并发性能极佳。
典型应用:配置缓存、用户会话管理、API响应缓存等需要频繁读取但写入较少的场景,sync.Map是理想选择。
性能优势体现:大部分读操作无需加锁,性能比传统map+mutex方案高出数倍;利用Go语言的原子操作保证线程安全,避免了锁竞争;写操作延迟同步到read map,减少锁竞争频率。
// 场景1:配置缓存 - sync.Map的理想应用
type ConfigCache struct {
data sync.Map
}
func (cc *ConfigCache) Get(key string) (interface{}, bool) {
return cc.data.Load(key)
}
func (cc *ConfigCache) Set(key string, value interface{}) {
cc.data.Store(key, value)
}
// 场景2:用户会话管理
type SessionManager struct {
sessions sync.Map
}
func (sm *SessionManager) GetSession(userID string) (*Session, bool) {
if session, ok := sm.sessions.Load(userID); ok {
return session.(*Session), true
}
return nil, false
}
func (sm *SessionManager) SetSession(userID string, session *Session) {
sm.sessions.Store(userID, session)
}
// 场景3:API响应缓存
type ResponseCache struct {
cache sync.Map
}
func (rc *ResponseCache) GetCachedResponse(requestID string) ([]byte, bool) {
if response, ok := rc.cache.Load(requestID); ok {
return response.([]byte), true
}
return nil, false
}
func (rc *ResponseCache) CacheResponse(requestID string, response []byte) {
rc.cache.Store(requestID, response)
}sync.Map的局限性主要体现在性能和功能两个方面。
写操作性能问题:每次写操作都需要获取mutex锁,在写多读少的场景下性能会明显下降,甚至不如传统map+mutex方案。
内存占用增加:由于需要维护两个map,内存占用比普通map大约增加一倍,在内存敏感的场景下需要谨慎考虑。
数据同步开销:当read map命中率降低时,需要进行promotion操作,这个过程是线性的,可能导致性能抖动。
不支持并发写入:sync.Map不支持多个goroutine同时写入,这在某些高并发写入场景下是严重限制。
在实际应用中,需要根据具体场景选择合适的并发map方案。
sync.Map适用场景:读多写少、不同key访问、内存充足、对性能要求高的场景。
传统map+mutex适用场景:写操作频繁、内存敏感、需要简单可靠方案的场景。
分段锁map适用场景:写多读少、需要高并发写入的场景。
分段锁map是一种通过将map分成多个段,每个段使用独立的锁来保护的方式。这种方式可以减小锁的粒度,提高并发性能,特别适合写操作频繁的场景。
分段锁map的核心思想是将数据分片,每个分片使用独立的锁来保护。这种设计大大减小了锁的粒度,使得不同分片可以并发访问,从而提高了并发性能。通过锁粒度细化,我们可以显著减少锁竞争,提高系统的吞吐量。
分片策略:使用哈希函数将key分配到不同的段,确保数据分布均匀,避免热点问题。
独立锁保护:每个段使用独立的读写锁,不同段可以并发访问,只有访问同一段的goroutine才会发生锁竞争。
可扩展性:可以通过增加段的数量来提高并发性能,但需要在内存占用和性能之间找到平衡。
分段锁map的核心数据结构包含两个主要部分:
分片数组:存储多个独立的map段,每个段包含一个map和一个读写锁。
哈希函数:用于将key分配到特定的段,确保数据分布均匀。
其并发访问机制为:
读操作:获取对应段的读锁,允许多个goroutine同时读取同一段。
写操作:获取对应段的写锁,独占访问,但不同段可以并发写入。
删除操作:获取对应段的写锁,安全删除数据。
使用代码示例:
func main() {
// 创建16个分片的分段锁map
sm := NewShardedMap(16)
// 并发写入
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
key := fmt.Sprintf("key%d", id)
sm.Set(key, fmt.Sprintf("value%d", id))
}(i)
}
// 并发读取
for i := 0; i < 50; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
key := fmt.Sprintf("key%d", id)
if value, exists := sm.Get(key); exists {
fmt.Printf("Key: %s, Value: %v\n", key, value)
}
}(i)
}
wg.Wait()
// 遍历所有数据
sm.Range(func(key string, value interface{}) bool {
fmt.Printf("Key: %s, Value: %v\n", key, value)
return true
})
}
