
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
Context是Go语言中用于传递请求范围的值、取消信号和截止时间的接口。它提供了一种在API边界之间传递请求范围数据、取消信号和截止时间的机制,是Go语言中处理请求生命周期的重要工具。
Context就像是一个"请求的身份证",它携带了请求相关的所有信息。想象一下,当你在银行办理业务时,银行会给你一个号码牌,这个号码牌包含了你的排队信息、办理时间限制等。Context就是程序中的"号码牌"。
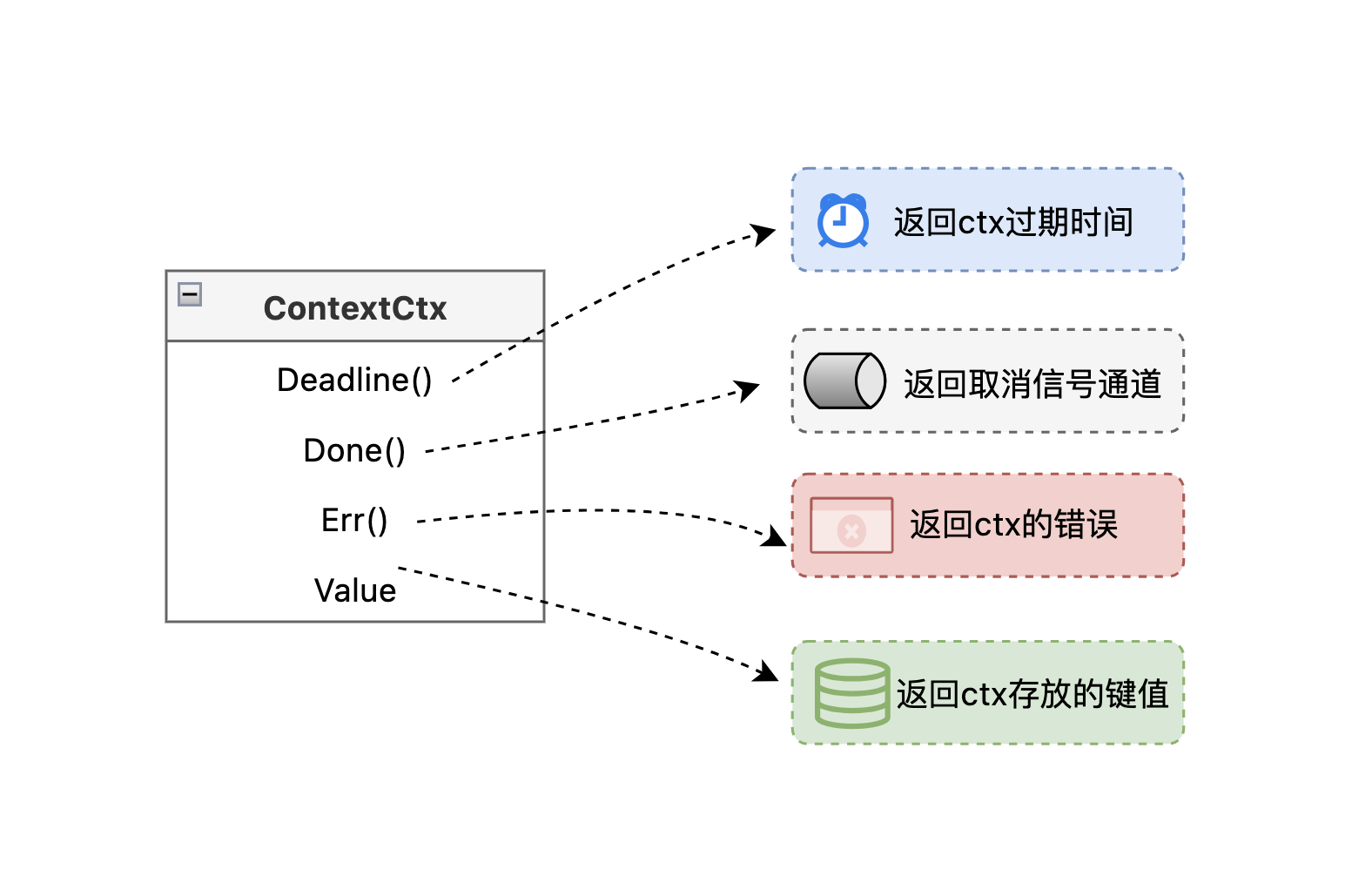
Context有四个核心功能:Deadline(截止时间)、Done(取消信号)、Err(错误信息)和Value(传递数据)。当父Context被取消时,所有子Context也会自动取消,就像银行下班时,所有排队的人都要离开一样。
Context在实际开发中主要用于HTTP请求生命周期管理、数据库操作控制、微服务架构中的调用链追踪和并发任务管理四个场景。
在HTTP请求生命周期管理中,Context用于传递用户认证信息、请求ID、会话数据,设置请求超时时间避免长时间等待,在中间件中传递请求上下文实现统一的日志记录和错误处理。这种设计让每个HTTP请求都有独立的上下文,避免了全局状态污染。
数据库操作控制场景下,Context为数据库查询设置合理的超时时间,在事务处理中传递上下文信息,实现数据库连接池的上下文感知。通过Context的超时机制,可以防止长时间查询阻塞系统,提高系统的响应性。
在微服务架构中的调用链追踪方面,Context在RPC调用中传递调用链ID,实现分布式链路追踪,在服务间传递用户上下文信息。这种设计让分布式系统中的请求追踪变得简单高效,有助于问题定位和性能分析。
并发任务管理场景中,Context控制goroutine的生命周期,实现优雅的取消机制,防止goroutine泄漏。通过Context的取消机制,可以及时释放系统资源,避免资源浪费。
使用示例
package main
import (
"context"
"fmt"
"time"
)
// 自定义key类型,避免类型冲突
type userIDKey struct{}
type requestIDKey struct{}
func main() {
// 创建根Context
ctx := context.Background()
// 添加请求ID
ctx = context.WithValue(ctx, requestIDKey{}, "req-123")
// 添加用户ID
ctx = context.WithValue(ctx, userIDKey{}, "user-456")
// 设置5秒超时
ctx, cancel := context.WithTimeout(ctx, 5*time.Second)
defer cancel()
// 模拟耗时操作
go doWork(ctx)
// 等待操作完成或超时
select {
case <-ctx.Done():
fmt.Printf("操作被取消: %v\n", ctx.Err())
case <-time.After(6 * time.Second):
fmt.Println("操作完成")
}
}
func doWork(ctx context.Context) {
// 获取请求ID
if requestID, ok := ctx.Value(requestIDKey{}).(string); ok {
fmt.Printf("处理请求: %s\n", requestID)
}
// 获取用户ID
if userID, ok := ctx.Value(userIDKey{}).(string); ok {
fmt.Printf("用户ID: %s\n", userID)
}
// 模拟工作
time.Sleep(3 * time.Second)
// 检查是否被取消
select {
case <-ctx.Done():
fmt.Println("工作被取消")
default:
fmt.Println("工作完成")
}
}Context的生命周期管理包括创建、传递、使用和清理四个阶段。
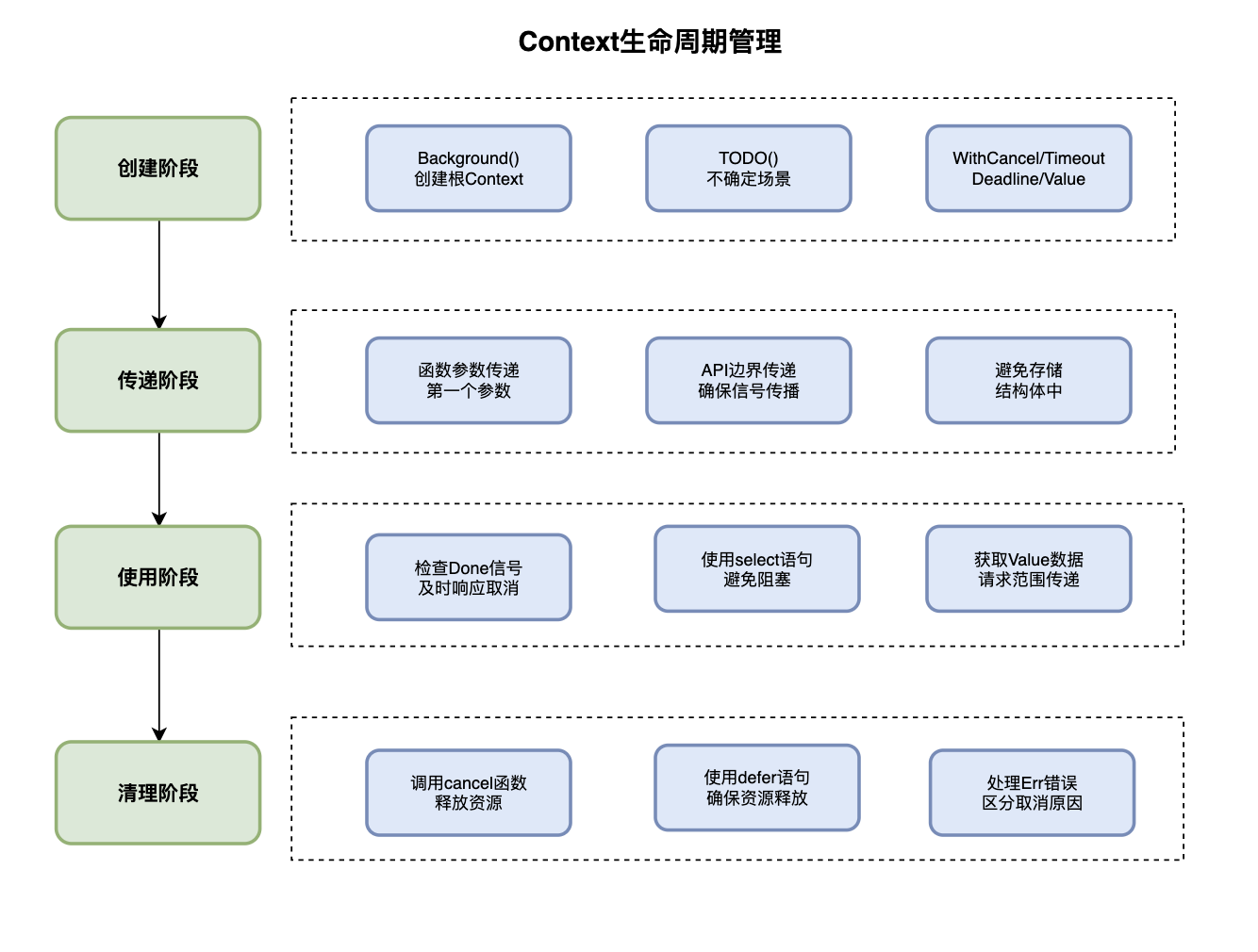
在创建阶段,使用context.Background创建根Context适用于主函数、初始化或测试,使用context.TODO创建根Context适用于不确定使用哪个Context的场景,通过WithCancel、WithTimeout、WithDeadline、WithValue创建派生Context。
传递阶段中,Context应该作为函数的第一个参数传递,这是Go语言的约定。在API边界之间传递Context,确保取消信号能够正确传播。避免将Context存储在结构体中,应该通过参数传递。
使用阶段需要定期检查Context.Done,及时响应取消信号。使用select语句处理取消信号,避免阻塞。通过Context.Value获取请求范围的数据。
清理阶段调用cancel函数释放资源,防止goroutine泄漏。在defer语句中调用cancel,确保资源被正确释放。处理Context.Err返回的错误信息。
使用示例
// Context完整使用示例
func contextCompleteExample() {
// 创建阶段:创建根Context并添加值
ctx := context.Background()
ctx = context.WithValue(ctx, "userID", "user123")
ctx = context.WithValue(ctx, "requestID", "req456")
// 创建阶段:派生带超时的Context
ctx, cancel := context.WithTimeout(ctx, 3*time.Second)
defer cancel() // 清理阶段:确保资源释放
// 传递阶段:启动goroutine处理
go processRequest(ctx)
// 使用阶段:等待结果
select {
case <-ctx.Done():
fmt.Printf("请求被取消: %v\n", ctx.Err())
case <-time.After(4 * time.Second):
fmt.Println("请求完成")
}
}
func processRequest(ctx context.Context) {
// 使用阶段:获取Context值
if userID, ok := ctx.Value("userID").(string); ok {
fmt.Printf("处理用户: %s\n", userID)
}
// 使用阶段:检查取消信号
select {
case <-ctx.Done():
fmt.Printf("处理被取消: %v\n", ctx.Err())
return
default:
fmt.Println("正在处理...")
time.Sleep(2 * time.Second)
}
}传统的并发控制方式(如channel、mutex)主要关注数据同步和资源保护,而Context更关注请求的生命周期管理。
| 特性 | 传统方式 | Context |
|---|---|---|
| 关注点 | 数据同步 | 生命周期管理 |
| 传播方式 | 手动传递 | 自动传播 |
| 超时控制 | 复杂实现 | 内置支持 |
| 取消机制 | 需要自定义 | 标准实现 |
| 数据传递 | 全局变量或参数 | 请求范围传递 |
| 错误处理 | 分散处理 | 统一处理 |
Context包提供了Context接口和四类核心创建函数。Context接口定义了Deadline、Done、Err、Value四个方法,用于获取截止时间、取消信号、错误信息和请求范围的值。
四类核心创建函数包括:
// Background()和TODO()函数使用示例
func backgroundAndTodoExample() {
// Background() - 创建根Context
ctx1 := context.Background()
// TODO() - 不确定场景的占位
ctx2 := context.TODO()
// 两个函数都返回空的Context
fmt.Printf("Background Context: %v\n", ctx1)
fmt.Printf("TODO Context: %v\n", ctx2)
}// WithCancel()函数使用示例
func withCancelExample() {
// 创建可取消的Context
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 启动goroutine
go func() {
for {
select {
case <-ctx.Done():
fmt.Println("收到取消信号")
return
default:
fmt.Println("正在工作...")
time.Sleep(500 * time.Millisecond)
}
}
}()
// 3秒后取消
time.Sleep(3 * time.Second)
cancel()
}// WithTimeout()和WithDeadline()函数使用示例
func timeoutAndDeadlineExample() {
// WithTimeout() - 带超时的Context
ctx1, cancel1 := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel1()
// WithDeadline() - 带截止时间的Context
deadline := time.Now().Add(3 * time.Second)
ctx2, cancel2 := context.WithDeadline(context.Background(), deadline)
defer cancel2()
// 使用超时Context
go func() {
select {
case <-ctx1.Done():
fmt.Printf("超时Context被取消: %v\n", ctx1.Err())
case <-time.After(3 * time.Second):
fmt.Println("操作完成")
}
}()
// 使用截止时间Context
go func() {
select {
case <-ctx2.Done():
fmt.Printf("截止时间Context被取消: %v\n", ctx2.Err())
case <-time.After(4 * time.Second):
fmt.Println("操作完成")
}
}()
}// WithValue()函数使用示例
func withValueExample() {
// 创建带值的Context
ctx := context.WithValue(context.Background(), "userID", "user123")
ctx = context.WithValue(ctx, "requestID", "req456")
// 使用Context
go processWithContext(ctx)
}
func processWithContext(ctx context.Context) {
// 获取值
if userID, ok := ctx.Value("userID").(string); ok {
fmt.Printf("处理用户: %s\n", userID)
}
if requestID, ok := ctx.Value("requestID").(string); ok {
fmt.Printf("处理请求: %s\n", requestID)
}
// 检查取消信号
select {
case <-ctx.Done():
fmt.Printf("处理被取消: %v\n", ctx.Err())
return
default:
fmt.Println("正在处理...")
time.Sleep(2 * time.Second)
}
}Context的传递遵循特定的约定和最佳实践,确保取消信号能够正确传播,同时保持代码的可读性和可维护性。
函数参数传递:Context应该作为函数的第一个参数传递,这是Go语言的约定。这种设计让Context在函数调用链中始终可见,便于调试和维护。同时,这种约定也让代码更加一致,提高了可读性。
API边界传递:在API边界之间传递Context,确保取消信号能够正确传播。当外部调用取消Context时,内部的所有操作都应该能够及时响应。这种设计让程序能够优雅地处理外部取消请求,避免资源浪费。
避免存储Context:不要将Context存储在结构体中,应该通过参数传递。Context是请求范围的数据,不应该跨越请求边界。将Context存储在结构体中可能导致生命周期管理混乱,增加内存泄漏的风险。
合理使用WithValue:WithValue函数应该用于传递请求范围的数据,而不是用于传递可选参数。请求范围的数据包括用户ID、请求ID、认证信息等,这些数据在整个请求生命周期中都是必需的。
// Context传递最佳实践示例
type UserService struct {
db *sql.DB
}
// 正确:Context作为第一个参数
func (s *UserService) GetUser(ctx context.Context, userID string) (*User, error) {
// 传递Context到数据库操作
return s.db.GetUser(ctx, userID)
}
// 错误:将Context存储在结构体中
type BadUserService struct {
db *sql.DB
ctx context.Context // 不应该这样做
}
// 正确:使用WithValue传递请求范围数据
func processRequest(ctx context.Context, userID string) {
// 添加用户ID到Context
ctx = context.WithValue(ctx, "userID", userID)
// 传递到其他函数
processUserData(ctx)
}
func processUserData(ctx context.Context) {
// 获取用户ID
if userID, ok := ctx.Value("userID").(string); ok {
fmt.Printf("处理用户数据: %s\n", userID)
}
}Context的底层实现采用了树形结构,每个Context节点都可以有父节点,形成一棵Context树。当父Context被取消时,所有子Context也会被取消,这种设计使得取消信号可以高效地传播。
具体来说,当你调用WithCancel、WithTimeout或WithValue时,Go会创建一个新的Context节点,并让它指向原来的Context作为父节点。新节点会继承父节点的所有特性,同时添加自己的新功能。
在树形结构中,每个cancelCtx节点维护一个children映射表,记录所有子Context的引用。当父Context被取消时,会遍历所有子Context并调用它们的取消方法。这种设计确保了取消信号的快速传播和完整覆盖,避免了goroutine泄漏问题。
树形结构的优势体现在几个方面:首先,内存效率高,多个Context可以共享相同的父节点;其次,取消传播快,通过树形结构可以快速找到所有需要取消的子Context;最后,结构清晰,每个Context都有明确的父子关系,便于理解和调试。
Context的取消机制基于通道关闭事件和原子操作实现。每个cancelCtx结构体包含一个done通道和一个err字段,当调用cancel()函数时,Go会原子性地关闭done通道并设置取消原因。这种设计确保了取消操作的原子性和线程安全。
取消机制的核心在于非阻塞的通道操作。当done通道被关闭时,所有对该通道的读取操作都会立即返回,不会阻塞goroutine。这种特性让取消信号能够实时传播,避免了传统轮询方式带来的性能开销。
Context的树形传播机制是取消功能的关键设计。每个Context节点都维护着对父Context的引用,当父Context被取消时,所有子Context也会自动取消。这种设计通过组合模式实现,确保了取消信号的一致性传播。
树形传播的优势在于自动管理和完整性保证。开发者不需要手动管理每个子Context的取消,系统会自动确保所有相关的Context都被正确取消。这种设计大大简化了并发程序的复杂度,减少了出错的可能性。
传播机制还支持多级嵌套,无论Context树的深度如何,取消信号都能正确传播到所有子节点。这种特性让Context能够处理复杂的并发场景,如微服务架构中的调用链管理。
使用示例
package main
import (
"context"
"fmt"
"time"
)
func main() {
// 创建一个可以取消的Context
ctx, cancel := context.WithCancel(context.Background())
// 启动一个工作协程
go worker(ctx, "任务1")
go worker(ctx, "任务2")
// 让程序运行3秒
time.Sleep(3 * time.Second)
// 取消所有任务
fmt.Println("取消所有任务...")
cancel()
// 等待一下让协程有时间退出
time.Sleep(1 * time.Second)
fmt.Println("程序结束")
}
func worker(ctx context.Context, name string) {
for {
select {
case <-ctx.Done():
// 收到取消信号,优雅退出
fmt.Printf("%s: 收到取消信号,正在退出...\n", name)
return
default:
// 正常工作中
fmt.Printf("%s: 正在工作...\n", name)
time.Sleep(500 * time.Millisecond)
}
}
}Context的值传递机制通过WithValue函数实现,它可以在Context树中存储和传递请求范围的值。这些值具有不可变性特点,每次调用WithValue都会创建新的Context节点,保持原有Context不变。
值传递采用向上查找机制,当在当前Context中找不到指定key时,会自动向上查找父Context,直到找到对应的值或到达根节点。这种设计让数据能够在Context树中高效传播,同时保持了数据的层次结构。
值传递具有类型安全和请求范围的特点。通过自定义key类型避免类型冲突,数据只在特定请求范围内有效,不会污染全局状态。这种设计确保了数据的安全性和隔离性。
Context的值传递机制就像是在信封上贴标签。每次你贴一个新标签时,都会创建一个新的信封,但原来的信封保持不变。这样设计的好处是:即使多个goroutine同时使用,也不会相互干扰,因为每个人都有自己的"信封"。
具体来说,当你调用WithValue时,Go会创建一个新的Context节点,把新的数据存储在这个节点中,然后返回这个新节点。原来的Context完全不受影响,这就是所谓的"不可变性"。当需要查找数据时,程序会先从当前节点开始查找,如果找不到,就会向上查找父节点,就像在家族中查找某个信息一样。
这种设计有三个重要特点:第一,数据是安全的,不会被意外修改;第二,查找是高效的,可以快速找到需要的数据;第三,使用起来很简单,只需要调用Value方法就能获取数据。
使用示例
package main
import (
"context"
"fmt"
)
// 自定义key类型,避免类型冲突
type userIDKey struct{}
type requestIDKey struct{}
type sessionKey struct{}
func main() {
// 创建根Context
ctx := context.Background()
// 添加用户ID
ctx = context.WithValue(ctx, userIDKey{}, "user123")
// 添加请求ID
ctx = context.WithValue(ctx, requestIDKey{}, "req456")
// 添加会话信息
ctx = context.WithValue(ctx, sessionKey{}, map[string]string{
"token": "abc123",
"role": "admin",
})
// 在不同的函数中使用这些值
processRequest(ctx)
validateUser(ctx)
}
func processRequest(ctx context.Context) {
// 获取请求ID
if requestID, ok := ctx.Value(requestIDKey{}).(string); ok {
fmt.Printf("处理请求: %s\n", requestID)
}
// 获取会话信息
if session, ok := ctx.Value(sessionKey{}).(map[string]string); ok {
fmt.Printf("用户角色: %s\n", session["role"])
}
}
func validateUser(ctx context.Context) {
// 获取用户ID
if userID, ok := ctx.Value(userIDKey{}).(string); ok {
fmt.Printf("验证用户: %s\n", userID)
}
// 尝试获取不存在的值
if value := ctx.Value("不存在的key"); value == nil {
fmt.Println("未找到指定的key")
}
}
// 演示值传递的不可变性
func demonstrateImmutability() {
ctx := context.Background()
// 创建第一个Context
ctx1 := context.WithValue(ctx, "key", "value1")
// 创建第二个Context,不影响第一个
ctx2 := context.WithValue(ctx1, "key", "value2")
// 两个Context的值不同
fmt.Printf("ctx1的值: %v\n", ctx1.Value("key"))
fmt.Printf("ctx2的值: %v\n", ctx2.Value("key"))
// 但ctx1的值没有改变
fmt.Printf("ctx1的值仍然是: %v\n", ctx1.Value("key"))
}Context值传递的应用场景主要包括认证信息传递、请求追踪和业务数据传递三个方面。在认证信息传递中,Context用于存储用户ID、权限信息、认证令牌等数据,这些数据在整个请求生命周期中都是必需的。通过Context传递认证信息,避免了在每个函数中重复传递这些参数,简化了代码结构。
在请求追踪中,Context用于存储请求ID、调用链ID、时间戳等信息,这些信息用于分布式系统的链路追踪和问题定位。通过Context传递追踪信息,可以实现统一的日志记录和错误处理,提高了系统的可观测性。
在业务数据传递中,Context用于存储与业务逻辑相关的数据,如用户偏好、语言设置、时区信息等。这些数据虽然不是必需的,但可以提高系统的用户体验和功能完整性。
Context的超时控制机制通过WithTimeout和WithDeadline函数实现,它们可以创建带有超时或截止时间的Context。当超时或截止时间到达时,Context会自动取消,这有助于控制操作的执行时间。
Context的超时控制机制就像是一个"定时炸弹"。你设置一个时间,当时间到了,所有相关的操作都会自动停止。这种机制让程序不会无限期地等待,避免了资源浪费和系统卡死的问题。
具体来说,WithTimeout函数接收一个时间长度(比如5秒),WithDeadline函数接收一个具体的时间点(比如下午3点)。当时间到达时,Go会自动关闭Context的Done通道,就像按下了一个"停止按钮",所有使用这个Context的goroutine都会收到停止信号。
这种机制在实际开发中非常有用。想象一下,当用户访问网站时,如果数据库查询太慢,我们不能让用户一直等待。通过设置超时时间,比如3秒,如果3秒内数据库没有返回结果,我们就告诉用户"请求超时,请稍后重试"。这样既保护了系统资源,又提供了良好的用户体验。
超时控制还可以防止"雪崩效应"。如果某个服务响应很慢,没有超时控制的话,可能会导致大量请求堆积,最终让整个系统崩溃。通过合理的超时设置,我们可以快速失败,释放资源,保持系统的稳定性。
超时和取消在Context中具有相同的触发机制,都是通过关闭done通道来实现。这种设计让超时和取消操作具有统一的处理方式,简化了错误处理逻辑。
当同时存在超时和手动取消时,先发生的操作会生效。这种设计避免了竞态条件,确保了操作的可预测性。通过ctx.Err()方法可以准确区分取消的具体原因,为不同的错误处理提供了依据。
协调机制还体现在资源管理上。无论是超时还是手动取消,都会触发相同的资源清理流程,确保系统资源得到及时释放。这种统一性让错误处理变得更加简单可靠。
Context在HTTP服务中主要用于请求生命周期管理和数据传递。通过r.Context()获取请求的Context,在中间件中传递用户认证信息、请求ID等数据,在数据库操作中设置超时时间,在微服务调用中传递调用链信息。
请求入口处理是Context使用的起点。通过r.Context()获取HTTP请求的原始Context,这个Context包含了请求的基本信息如客户端IP、请求时间等。在请求处理函数中,Context应该作为第一个参数传递,确保取消信号能够正确传播到所有相关的操作。
中间件中的Context传递是HTTP服务架构的重要组成部分。中间件可以在Context中添加认证信息、请求ID、用户信息等数据,这些数据在整个请求生命周期中都是可用的。通过context.WithValue添加数据,通过ctx.Value()获取数据,实现了请求级别的数据隔离。
HTTP服务中的Context传递遵循自上而下的传递原则,从HTTP处理器开始,依次传递给中间件、业务逻辑、数据库操作等。每个层级都可以添加自己的Context信息,形成完整的请求上下文链。
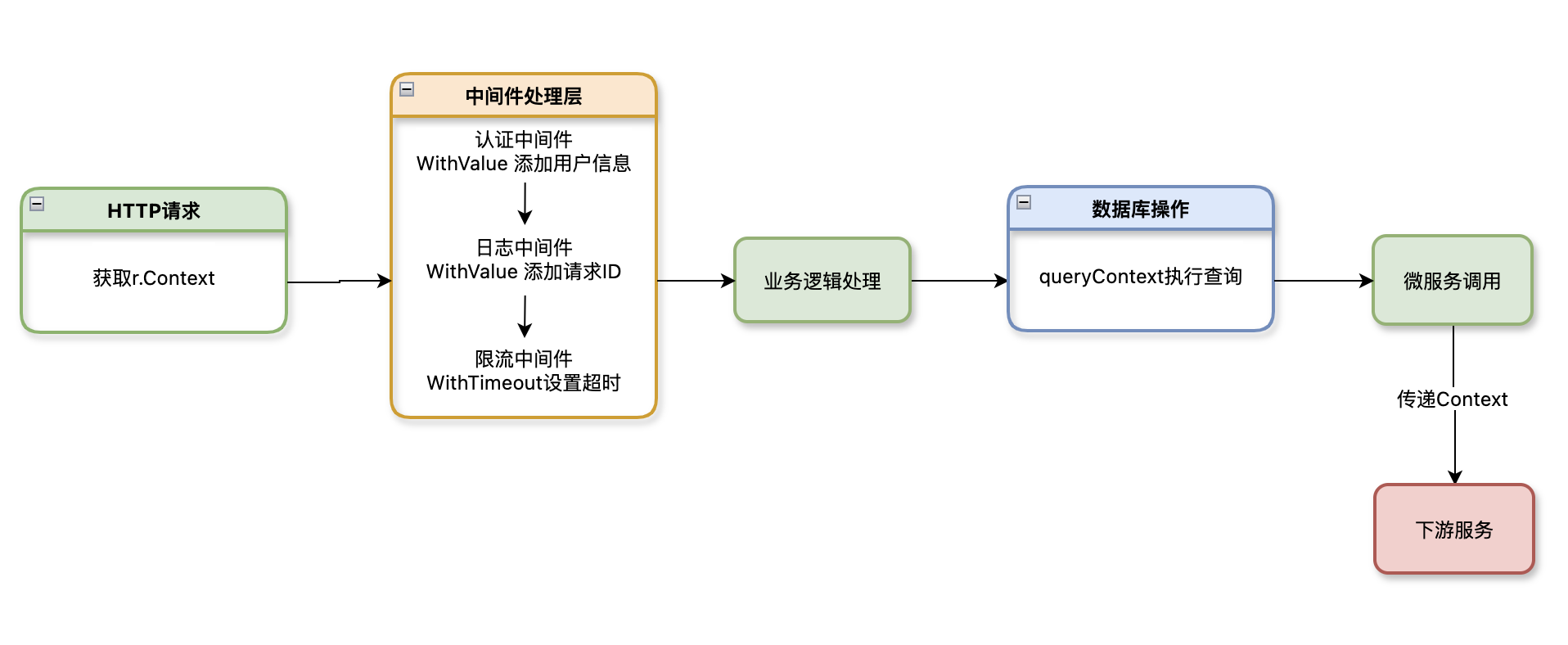
HTTP服务中的Context使用示例
func httpContextExample() {
http.HandleFunc("/api/user", func(w http.ResponseWriter, r *http.Request) {
// 获取请求Context
ctx := r.Context()
// 添加用户认证信息
ctx = context.WithValue(ctx, "userID", "user123")
ctx = context.WithValue(ctx, "requestID", "req456")
// 设置请求超时
ctx, cancel := context.WithTimeout(ctx, 30*time.Second)
defer cancel()
// 处理请求
handleUserRequest(ctx, w, r)
})
}
func handleUserRequest(ctx context.Context, w http.ResponseWriter, r *http.Request) {
// 获取Context中的用户信息
if userID, ok := ctx.Value("userID").(string); ok {
fmt.Printf("处理用户请求: %s\n", userID)
}
// 检查取消信号
select {
case <-ctx.Done():
http.Error(w, "请求被取消", http.StatusRequestTimeout)
return
default:
// 继续处理请求
processUserData(ctx)
}
}Context在HTTP服务中的最佳实践围绕生命周期管理和错误处理展开,确保系统能够优雅地处理各种异常情况。
生命周期管理要求正确设置Context的超时时间和取消机制。对于不同的操作类型,需要设置不同的超时时间:用户界面操作通常设置3-10秒,API调用设置10-30秒,文件上传设置60-300秒。通过合理的超时设置,既保证了用户体验,又避免了系统资源被长时间占用。
错误处理体现在对Context取消信号的及时响应。在所有的长时间操作中,都应该使用select语句监听ctx.Done(),当收到取消信号时立即停止操作并返回适当的错误信息。这种设计让系统能够快速响应外部的取消请求,提高了系统的响应性。
Context的使用还体现在资源管理上。通过defer cancel()确保Context相关的资源被正确释放,防止goroutine泄漏。在数据库连接池中,Context用于控制连接的获取和释放,确保连接能够及时返回到连接池中。
这种统一的Context使用模式让HTTP服务具备了良好的可维护性和可扩展性,为构建高性能的Web应用提供了坚实的基础。
Context在数据库操作中主要用于查询超时控制和事务管理。通过context.WithTimeout设置查询超时时间,防止长时间查询阻塞系统。在事务处理中传递Context,实现事务级别的超时控制和取消传播。
数据库操作中的Context应用体现在连接池管理和查询优化两个方面。通过Context控制数据库连接的获取和释放,确保连接能够及时返回到连接池。在复杂查询中使用Context设置合理的超时时间,避免查询时间过长影响系统性能。
连接池中的Context使用是数据库操作的基础。当从连接池获取数据库连接时,Context用于控制获取操作的超时时间,防止在高并发情况下长时间等待连接。如果获取连接超时,系统会立即返回错误,避免阻塞其他操作。在连接使用完毕后,Context确保连接能够及时返回到连接池中,提高连接池的利用率。
查询超时控制的实现是数据库操作的核心。通过context.WithTimeout为查询操作设置合理的超时时间,当查询时间超过设定值时,Context会自动取消,数据库驱动会中断查询操作。这种机制防止了长时间查询对系统性能的影响,提高了系统的响应性。
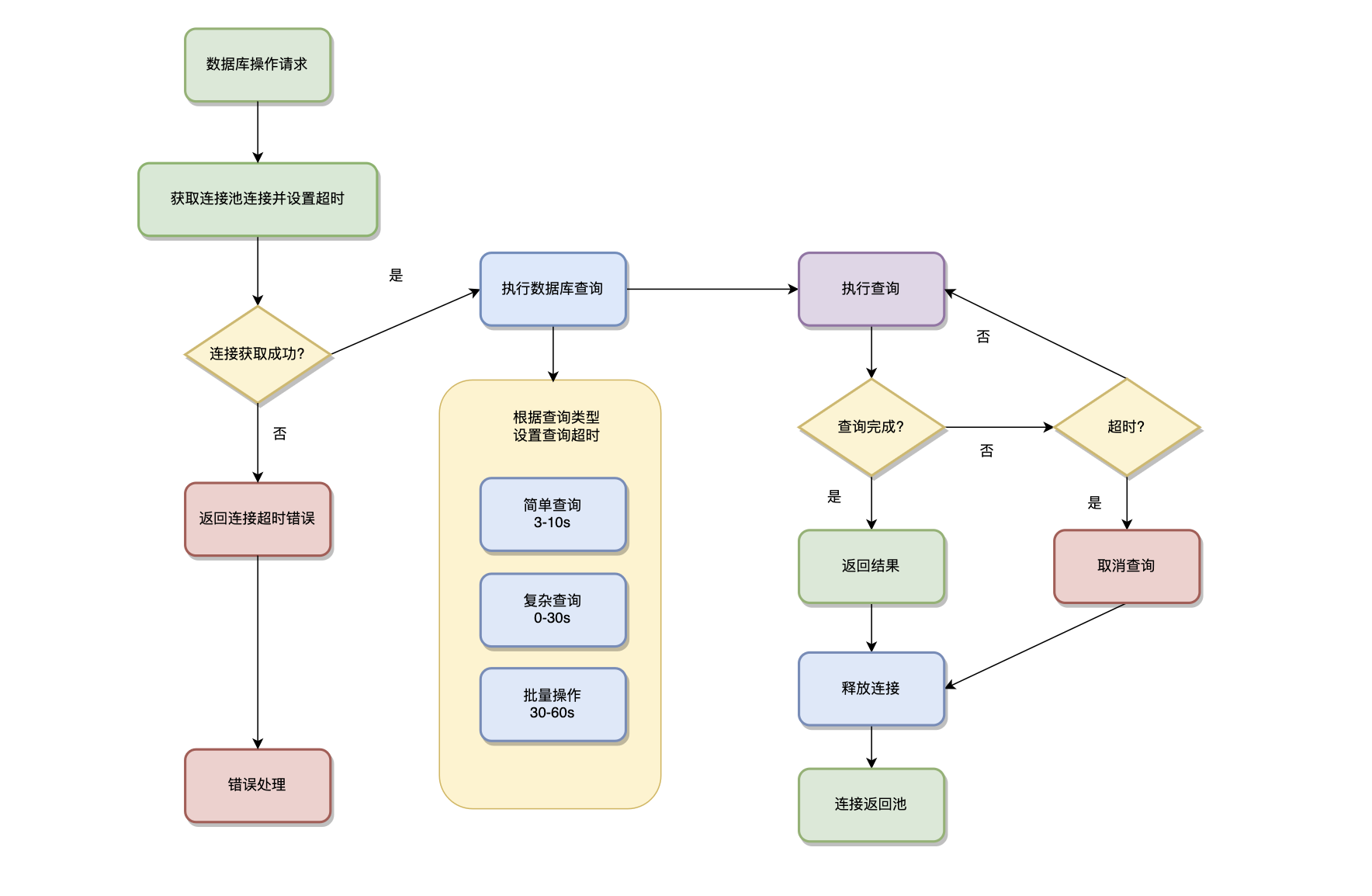
数据库操作中的Context应用示例
func databaseContextExample() {
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 执行数据库查询
rows, err := db.QueryContext(ctx, "SELECT * FROM users WHERE status = ?", "active")
if err != nil {
if err == context.DeadlineExceeded {
fmt.Println("查询超时")
} else {
fmt.Printf("查询错误: %v\n", err)
}
return
}
defer rows.Close()
// 处理查询结果
for rows.Next() {
var user User
if err := rows.Scan(&user.ID, &user.Name, &user.Email); err != nil {
fmt.Printf("扫描错误: %v\n", err)
continue
}
fmt.Printf("用户: %s\n", user.Name)
}
}事务处理中的Context应用体现了Context在复杂数据库操作中的重要作用。在事务开始时就设置Context的超时时间,确保整个事务的执行时间在可控范围内。当Context被取消时,事务会自动回滚,确保数据的一致性。这种设计让事务处理变得更加可靠,避免了长时间事务对数据库性能的影响。
数据库操作中的Context最佳实践围绕超时设置和错误处理展开,确保数据库操作既高效又可靠。
超时设置的策略需要根据操作类型和业务需求来确定。对于简单的查询操作,通常设置3-10秒的超时时间;对于复杂的聚合查询,可以设置10-30秒;对于大批量操作,可以设置30-60秒。这种差异化的超时设置既保证了操作的完成,又避免了系统资源的浪费。
错误处理的机制体现在对Context取消信号的及时响应。当数据库操作收到取消信号时,应该立即停止当前操作并返回适当的错误信息。通过检查ctx.Err()可以区分不同的取消原因,为不同的错误处理提供依据。
Context的应用还体现在连接管理上。通过Context控制数据库连接的获取和释放,确保在高并发情况下连接池能够正常工作。当Context被取消时,相关的数据库连接应该立即释放,避免连接泄漏。
这种统一的Context使用模式让数据库操作具备了良好的可维护性和可扩展性,为构建高性能的数据库应用提供了坚实的基础。

