
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
GORM是Go语言生态中最成熟的ORM框架,它在保证开发效率的同时,也兼顾了程序性能的要求。GORM不仅提供了标准的ORM功能,还充分利用了Go语言的特性,比如反射、接口、并发安全等,为开发者提供了强大且符合Go语言习惯的数据库操作方式。
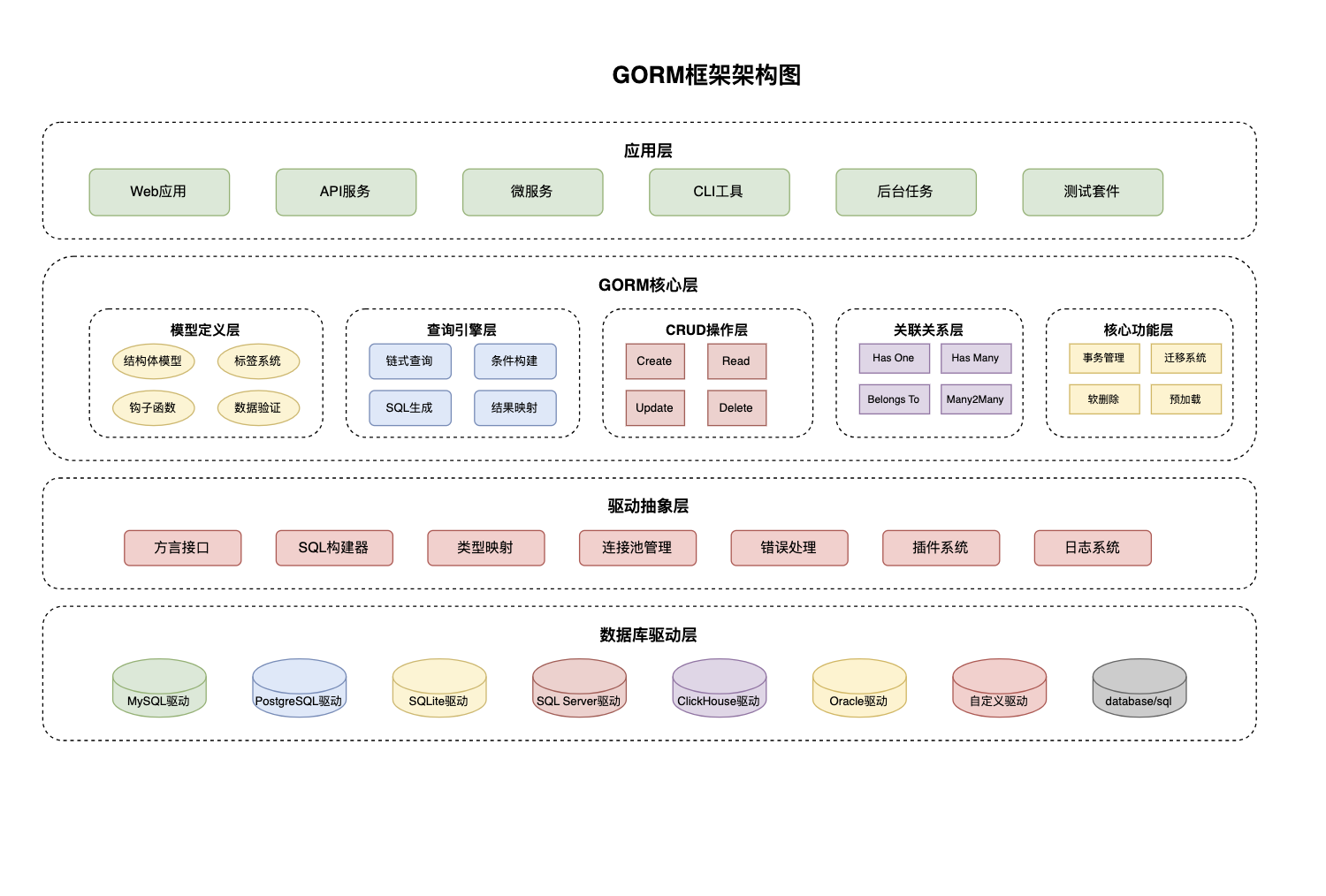
ORM模式要解决的核心问题是对象与数据库表之间的映射差异,也就是面向对象编程和关系型数据库在数据表示方式上的不同。GORM通过三个技术层次解决这个问题:结构映射层将Go结构体转换为数据库表结构,自动分析字段类型并生成建表语句;查询抽象层把对象方法调用转换成SQL语句,支持链式调用和动态查询;结果映射层把数据库查询结果自动转换回Go对象,处理数据类型转换。
GORM的智能映射机制是其核心优势之一,它能够自动识别Go语言的各种数据类型并映射为合适的数据库字段类型。例如,Go的time.Time类型会自动映射为数据库的DATETIME类型,bool类型映射为BOOLEAN或TINYINT类型。这种自动映射大大减少了手动配置的工作量,同时通过struct标签提供了精细控制的能力。
// GORM结构映射示例
type User struct {
ID uint `gorm:"primaryKey;autoIncrement"`
Name string `gorm:"size:100;not null"`
Email string `gorm:"uniqueIndex;size:255"`
Age int `gorm:"default:18"`
CreatedAt time.Time `gorm:"autoCreateTime"`
UpdatedAt time.Time `gorm:"autoUpdateTime"`
DeletedAt gorm.DeletedAt `gorm:"index"`
}
// 使用示例
func gormBasicExample() {
db, _ := gorm.Open(sqlite.Open("test.db"), &gorm.Config{})
// 自动迁移,创建表结构
db.AutoMigrate(&User{})
// 创建记录
user := User{Name: "张三", Email: "zhang@example.com", Age: 25}
db.Create(&user)
// 查询记录
var users []User
db.Where("age > ?", 20).Find(&users)
// 更新记录
db.Model(&user).Update("Age", 26)
// 软删除
db.Delete(&user)
}GORM采用了多种设计模式的组合来实现其强大功能。GORM使用了建造者模式通过链式调用来构建查询条件;使用策略模式处理不同数据库的语法差异,通过统一接口操作各种数据库;使用模板方法模式定义数据操作的标准流程,同时允许自定义处理逻辑。
钩子函数机制是GORM的重要特性,它允许开发者在数据操作的关键节点插入自定义逻辑。这种设计既保持了框架的稳定性,又提供了良好的扩展性。钩子函数包括BeforeCreate、AfterCreate、BeforeUpdate、AfterUpdate等,支持在数据生命周期的各个阶段进行干预。
关联关系处理是GORM的核心功能之一,它支持一对一、一对多、多对多等各种关联关系。通过预加载(Preload)机制,可以有效解决N+1查询问题。GORM支持延迟加载(需要时才查询关联数据)和预加载(提前查询关联数据)两种方式,开发者可以根据需要选择,既保证性能又方便使用。
Active Record模式在GORM中体现为模型驱动的数据访问方式,每个模型结构体既包含数据字段,也通过方法提供数据访问功能。这种模式的优势在于代码简洁性和开发效率,开发者可以直接通过模型对象进行数据库操作,无需编写复杂的SQL语句。
GORM对Active Record模式进行了Go语言化的改进,通过接口组合而非继承来实现功能扩展,这更符合Go语言的设计理念。模型对象可以通过嵌入gorm.Model来获得基本的CRUD功能,也可以通过实现特定接口来定制行为。这种设计避免了传统Active Record模式中模型过重的问题,保持了代码的清晰性和可测试性。
然而,Active Record模式也存在一些局限性:职责混合可能导致模型类过于复杂,测试困难因为数据访问逻辑与业务逻辑耦合,性能问题在复杂查询场景下可能不如原生SQL高效。GORM通过提供Repository模式支持和原生SQL接口来缓解这些问题,让开发者可以根据具体场景选择最适合的方案。
// Active Record模式实现示例
type User struct {
gorm.Model
Username string `gorm:"uniqueIndex;size:50"`
Email string `gorm:"uniqueIndex;size:100"`
Age int `gorm:"default:18"`
}
// 模型包含数据访问方法
func (u *User) FindByUsername(db *gorm.DB, username string) error {
return db.Where("username = ?", username).First(u).Error
}
func (u *User) IsAdult() bool {
return u.Age >= 18
}
// 钩子函数实现业务逻辑
func (u *User) BeforeCreate(tx *gorm.DB) error {
if u.Username == "" {
return errors.New("用户名不能为空")
}
return nil
}
// 使用示例
func activeRecordExample() {
user := User{Username: "john", Email: "john@example.com"}
// 模型对象直接操作数据库
db.Create(&user)
// 通过模型方法查询
var foundUser User
foundUser.FindByUsername(db, "john")
// 业务逻辑方法
if foundUser.IsAdult() {
fmt.Println("用户已成年")
}
}GORM的模型定义遵循约定优于配置的原则,通过Go结构体定义数据模型,支持丰富的结构体标签进行精细控制。模型定义规范包括:字段命名约定(使用驼峰命名,自动转换为下划线数据库字段)、主键规范(默认ID字段为主键,支持自定义)、时间戳字段(CreatedAt、UpdatedAt自动管理)、软删除支持(DeletedAt字段实现逻辑删除)。
字段映射规范是GORM模型定义的基础,它建立了Go语言类型系统与SQL数据类型之间的桥梁。GORM采用智能类型推断机制,能够自动将Go的基本类型映射为合适的数据库字段类型。例如,string类型默认映射为VARCHAR(255),int类型映射为INT,bool类型映射为BOOLEAN或TINYINT。这种自动映射减少了开发者的配置工作,同时保持了类型安全性。
命名约定规范遵循Go语言的驼峰命名法转换为数据库的下划线命名法的惯例。例如,结构体字段FirstName会自动映射为数据库字段first_name,表名UserProfile映射为user_profiles。这种约定性规范使得代码更加一致和可预测,同时支持通过标签进行自定义覆盖。
嵌入式结构体支持允许通过结构体组合来实现代码复用和模块化设计。GORM提供了gorm.Model基础模型,包含了常用的ID、CreatedAt、UpdatedAt、DeletedAt字段,开发者可以通过嵌入这个结构体来快速获得基础功能。
// 模型定义规范示例
type BaseModel struct {
ID uint `gorm:"primaryKey;autoIncrement" json:"id"`
CreatedAt time.Time `gorm:"autoCreateTime" json:"created_at"`
UpdatedAt time.Time `gorm:"autoUpdateTime" json:"updated_at"`
DeletedAt gorm.DeletedAt `gorm:"index" json:"-"`
}
type User struct {
BaseModel
Username string `gorm:"uniqueIndex;size:50;not null" json:"username" validate:"required,min=3,max=50"`
Email string `gorm:"uniqueIndex;size:100;not null" json:"email" validate:"required,email"`
Password string `gorm:"size:255;not null" json:"-" validate:"required,min=6"`
Profile Profile `gorm:"constraint:OnUpdate:CASCADE,OnDelete:SET NULL;" json:"profile"`
}
type Profile struct {
BaseModel
UserID uint `gorm:"uniqueIndex;not null" json:"user_id"`
FirstName string `gorm:"size:50" json:"first_name"`
LastName string `gorm:"size:50" json:"last_name"`
Avatar string `gorm:"size:255" json:"avatar"`
}接口驱动的模型设计通过定义模型接口来规范模型行为,提高代码的可测试性和可维护性。模型可以实现特定的接口来获得额外的功能,比如实现BeforeCreate接口来在创建前执行自定义逻辑。
模型继承与组合虽然Go语言不支持传统的类继承,但可以通过结构体嵌入和接口组合来实现类似的功能。GORM充分利用了这一特性,允许通过嵌入基础模型来实现功能共享,同时保持代码的清晰性。
动态模型支持对于需要运行时确定模型结构的场景,GORM提供了基于interface{}和反射的动态模型支持。虽然这种方式牺牲了编译时的类型安全,但为某些特殊场景提供了必要的灵活性。
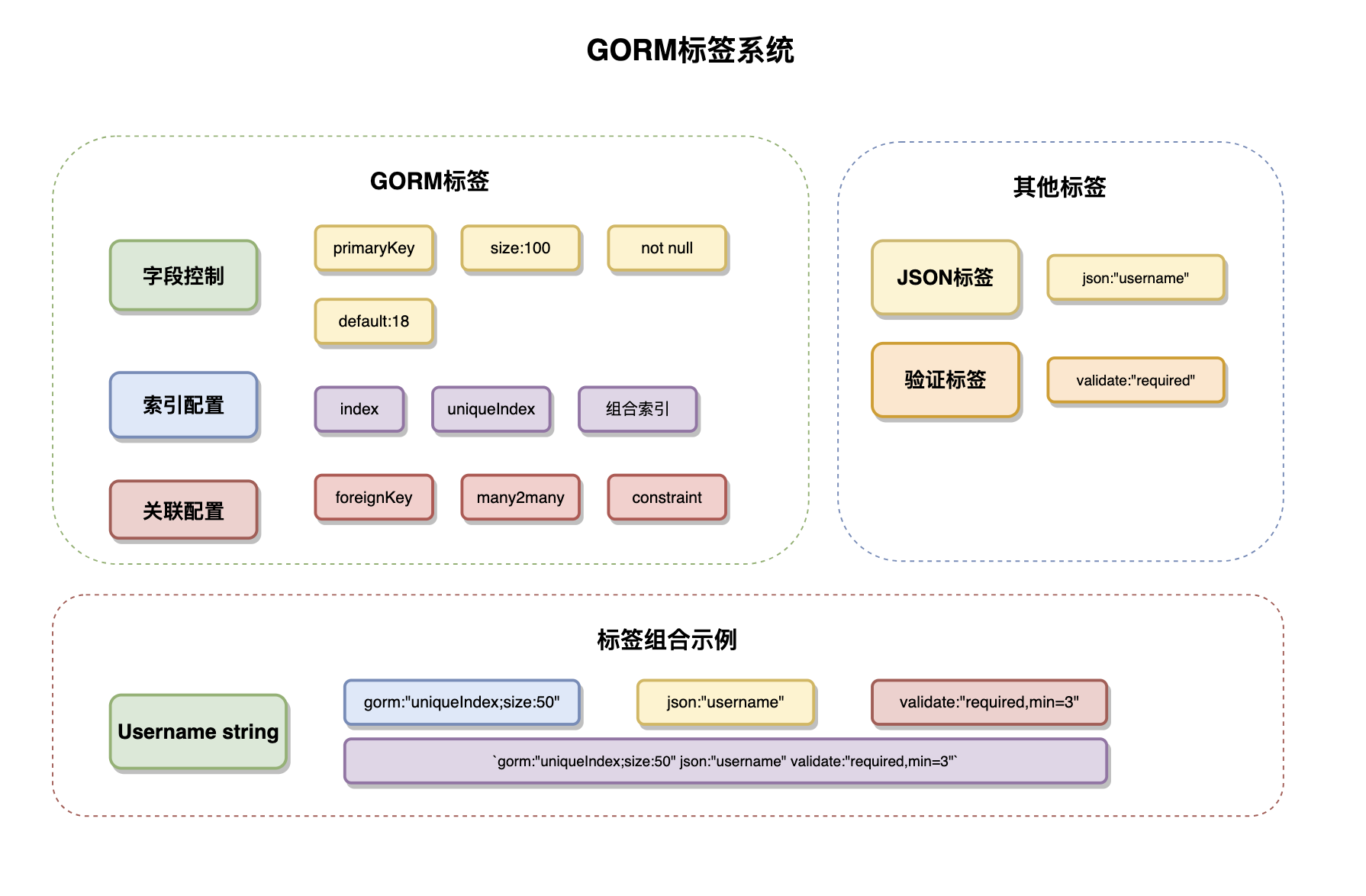
gorm标签系统是GORM最强大的功能之一,它提供了精确的字段控制功能。标签支持多种属性的组合使用,通过分号分隔不同的属性。常用的标签属性包括:字段属性(size、type、not null、default)、索引属性(index、uniqueIndex)、关联属性(foreignKey、references、constraint)、行为属性(autoCreateTime、autoUpdateTime、serializer)。
复合标签策略允许在单个字段上应用多个标签系统,实现多方面的数据控制。例如,同时使用gorm标签定义数据库约束、json标签控制API序列化、validate标签实现数据验证。这种分层的标签设计使得数据模型能够同时满足持久化、序列化和验证的需求。
自定义标签处理器支持开发者扩展标签系统的功能,通过实现特定接口可以处理自定义的标签逻辑。这种扩展机制使得GORM能够适应各种特殊的业务需求,比如数据加密、审计日志、字段脱敏等。
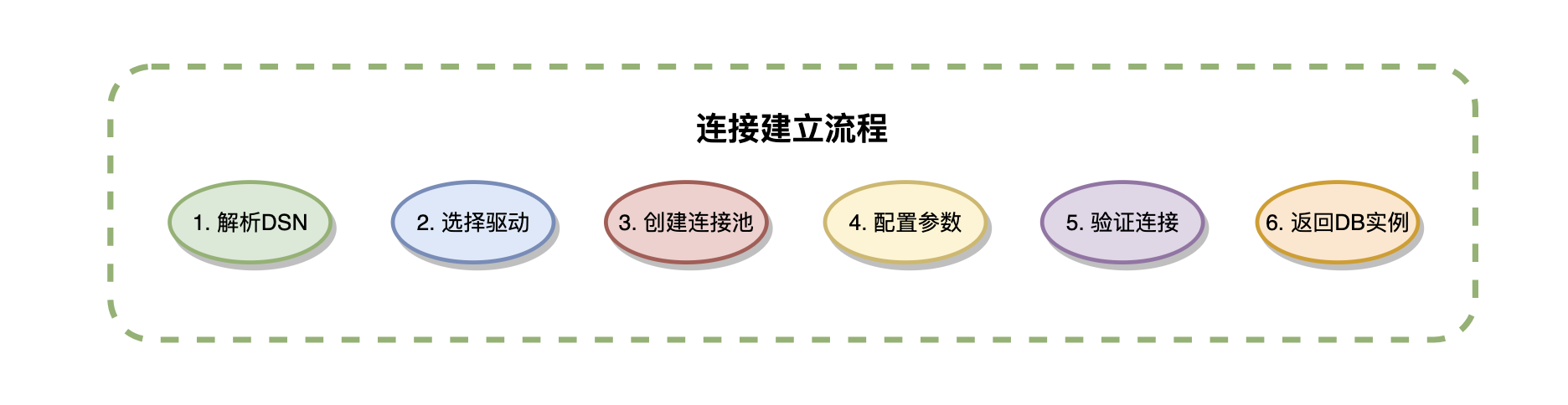
GORM通过数据库驱动和DSN连接串建立数据库连接,支持MySQL、PostgreSQL、SQLite、SQL Server等主流数据库。连接过程包括:驱动注册(导入相应数据库驱动)、DSN配置(数据源名称字符串)、连接建立(gorm.Open()方法)、配置优化(通过gorm.Config设置连接参数)。
多数据库支持架构是GORM的核心优势之一,它通过统一的驱动接口实现了对不同数据库的统一访问。每种数据库都有对应的驱动实现,如mysql驱动对应MySQL,postgres驱动对应PostgreSQL。GORM在驱动层之上提供了数据库方言系统,用于处理不同数据库的SQL语法差异、数据类型映射和特性支持。
DSN连接字符串是数据库连接的核心配置,它包含了服务器地址、端口、用户名、密码、数据库名等连接信息。GORM支持各种DSN格式,并提供了连接参数配置功能,如字符集设置、时区配置、SSL设置等。合理的DSN配置能够避免常见的连接问题,如字符编码错误、时区不一致等。
连接建立流程采用了按需连接策略,即在调用gorm.Open()时并不立即建立物理连接,而是在第一次数据库操作时才真正连接。这种设计提高了应用启动速度,同时通过连接验证确保配置的正确性。
数据库连接配置示例
func setupDatabase() *gorm.DB {
// MySQL连接配置
dsn := "user:password@tcp(localhost:3306)/dbname?charset=utf8mb4&parseTime=True&loc=Local"
// GORM配置
config := &gorm.Config{
Logger: logger.Default.LogMode(logger.Info),
NamingStrategy: schema.NamingStrategy{
TablePrefix: "app_",
SingularTable: false,
},
DisableForeignKeyConstraintWhenMigrating: true,
}
db, err := gorm.Open(mysql.Open(dsn), config)
if err != nil {
panic("failed to connect database")
}
// 获取底层sql.DB实例进行连接池配置
sqlDB, err := db.DB()
if err != nil {
panic("failed to get sql.DB")
}
// 连接池配置
sqlDB.SetMaxOpenConns(100) // 最大开放连接数
sqlDB.SetMaxIdleConns(10) // 最大空闲连接数
sqlDB.SetConnMaxLifetime(time.Hour) // 连接最大生命周期
sqlDB.SetConnMaxIdleTime(time.Minute * 30) // 空闲连接超时
return db
}连接池算法机制基于连接池模式实现,通过维护一个连接队列来管理数据库连接的分配和回收。当应用需要数据库连接时,连接池首先检查是否有可用的空闲连接,如果有则直接分配,否则创建新连接(在最大连接数限制内)。连接使用完毕后,会被放回池中供后续使用,这种复用机制大大减少了连接建立和销毁的开销。
动态连接管理通过连接状态检查确保连接池中的连接保持有效状态。GORM会定期检查空闲连接的健康状况,自动清理失效连接并根据需要创建新连接。这种自愈能力使得应用能够应对网络中断、数据库重启等异常情况。
性能监控与调优通过连接池状态监控帮助开发者了解连接使用情况。关键指标包括当前开放连接数、空闲连接数、等待连接的请求数、连接创建和销毁的频率等。基于这些指标可以动态调整连接池参数,实现最优的性能配置。
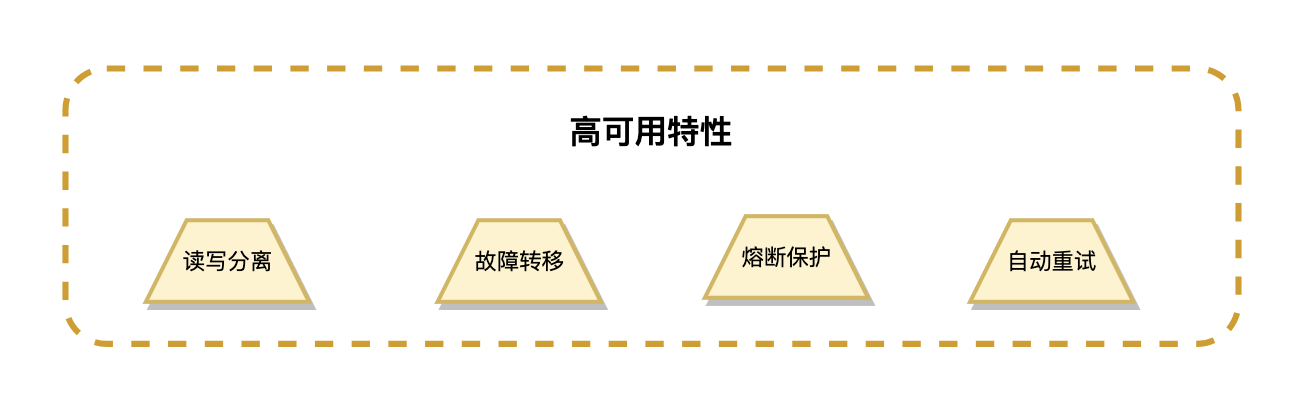
多数据源支持允许应用同时连接多个数据库实例,实现读写分离和数据分片等高级功能。GORM支持主从数据库配置,可以将读操作路由到从库,写操作路由到主库,从而提高系统的整体性能和可用性。
连接故障恢复通过重试机制和熔断保护机制提高系统的容错能力。当数据库连接出现问题时,GORM会自动重试连接,并在连续失败时触发熔断保护,避免系统雪崩。结合健康检查和自动恢复机制,确保系统能够在数据库故障恢复后快速恢复正常服务。
事务级连接管理在事务处理过程中,GORM会确保同一事务内的所有操作使用相同的数据库连接,避免事务跨连接导致的一致性问题。这种连接绑定策略是事务ACID特性的重要保障。
GORM的CRUD操作通过方法链式调用实现,提供了直观的API接口。Create操作支持单条和批量插入,Read操作支持多种查询方式,Update操作支持字段更新和结构体更新,Delete操作支持硬删除和软删除。每种操作都支持条件筛选、字段选择、关联处理等高级功能。
Create操作的智能处理不仅仅是简单的数据插入,还包含了数据验证、钩子函数执行、关联处理等复杂逻辑。GORM在插入数据前会自动设置CreatedAt时间戳,执行BeforeCreate钩子函数,处理关联对象的级联创建。对于批量插入操作,GORM会根据数据库特性选择最优的插入策略,如使用批量INSERT语句或准备语句来提高性能。
Read操作的查询优化通过自动索引选择和查询性能分析来生成高效的SQL语句。GORM会分析查询条件中涉及的字段,自动选择合适的索引,并通过EXPLAIN分析来验证查询性能。对于复杂查询,支持原生SQL和子查询,确保在复杂业务场景下也能获得最佳性能。
Update操作的精细控制支持零值更新、批量更新、条件更新等多种更新模式。GORM会自动处理UpdatedAt时间戳的更新,执行相应的钩子函数,并通过乐观锁机制防止并发更新冲突。Select和Omit方法提供了精确的字段控制,避免不必要的字段更新。
Delete操作的安全保障通过软删除机制提供了数据安全性保障,默认情况下删除操作只是设置DeletedAt字段,数据仍然保留在数据库中。这种设计既满足了业务上的删除需求,又为数据恢复提供了可能性。硬删除需要显式调用Unscoped()方法,确保重要数据不会被意外删除。
// CRUD操作示例
func crudOperationsExample(db *gorm.DB) {
// Create - 创建操作
user := User{
Username: "john_doe",
Email: "john@example.com",
Profile: Profile{
FirstName: "John",
LastName: "Doe",
},
}
// 单条插入,自动处理关联对象
result := db.Create(&user)
fmt.Printf("插入影响行数: %d, 用户ID: %d\n", result.RowsAffected, user.ID)
// 批量插入
users := []User{
{Username: "user1", Email: "user1@example.com"},
{Username: "user2", Email: "user2@example.com"},
}
db.CreateInBatches(users, 100) // 批量大小为100
// Read - 查询操作
var foundUser User
// 根据主键查询
db.First(&foundUser, user.ID)
// 条件查询
db.Where("username = ?", "john_doe").First(&foundUser)
// 复杂查询
var activeUsers []User
db.Where("created_at > ?", time.Now().AddDate(0, -1, 0)).
Where("deleted_at IS NULL").
Order("created_at desc").
Limit(10).
Find(&activeUsers)
// Update - 更新操作
// 更新单个字段
db.Model(&user).Update("email", "newemail@example.com")
// 更新多个字段
db.Model(&user).Updates(User{
Email: "updated@example.com",
Profile: Profile{FirstName: "Updated"},
})
// 批量更新
db.Model(&User{}).Where("created_at < ?", time.Now().AddDate(0, -6, 0)).
Update("status", "inactive")
// Delete - 删除操作
// 软删除(默认)
db.Delete(&user)
// 硬删除
db.Unscoped().Delete(&user)
// 批量软删除
db.Where("status = ?", "inactive").Delete(&User{})
}动态查询构建是GORM查询构建器的强大功能,它允许根据运行时条件动态组装查询逻辑。通过条件判断可以构建不同的查询分支,这种灵活性使得同一个查询函数能够处理多种业务场景。Scopes功能进一步增强了查询的可复用性,可以将常用的查询逻辑封装为可重用的作用域函数。
子查询和联表查询支持复杂的关系查询需求。GORM提供了Joins方法进行表连接,支持INNER JOIN、LEFT JOIN、RIGHT JOIN等多种连接方式。子查询可以通过SubQuery方法实现,支持在WHERE、SELECT、FROM等子句中使用子查询,满足复杂的业务查询需求。
查询性能优化通过查询缓存、预编译语句、索引提示等机制提升查询性能。GORM会自动缓存频繁使用的查询语句,减少SQL解析的开销。对于重复执行的查询,支持预编译语句来提高执行效率。
// 查询构建器高级特性示例
func advancedQueryBuilderExample(db *gorm.DB) {
// 动态查询构建
query := db.Model(&User{})
// 根据条件动态添加查询条件
var name, email string
var minAge int
if name != "" {
query = query.Where("name LIKE ?", "%"+name+"%")
}
if email != "" {
query = query.Where("email = ?", email)
}
if minAge > 0 {
query = query.Where("age >= ?", minAge)
}
// Scopes - 可复用的查询作用域
query.Scopes(ActiveUsers, AdultUsers).Find(&users)
// 子查询示例
subQuery := db.Model(&Order{}).Select("user_id").Where("amount > ?", 1000)
db.Where("id IN (?)", subQuery).Find(&users)
// 联表查询
db.Model(&User{}).
Select("users.name, profiles.first_name, COUNT(orders.id) as order_count").
Joins("LEFT JOIN profiles ON users.id = profiles.user_id").
Joins("LEFT JOIN orders ON users.id = orders.user_id").
Group("users.id").
Find(&results)
}
// 可复用的查询作用域
func ActiveUsers(db *gorm.DB) *gorm.DB {
return db.Where("deleted_at IS NULL")
}
func AdultUsers(db *gorm.DB) *gorm.DB {
return db.Where("age >= ?", 18)
}不可变对象设计是链式查询的核心设计理念,每个查询方法调用都会返回一个新的DB实例,而不是修改原有实例。这种设计确保了并发安全性,多个goroutine可以同时使用同一个DB实例进行查询而不会相互干扰。同时,这种设计也提高了代码的可测试性和可调试性。
延迟执行机制是链式查询的重要特性,查询条件的组装和SQL语句的生成是分离的。只有在调用终结方法(如Find、First、Create等)时才会生成并执行SQL语句。这种延迟执行允许查询构建器进行查询优化,比如合并重复条件、优化连接顺序、选择最佳索引等。
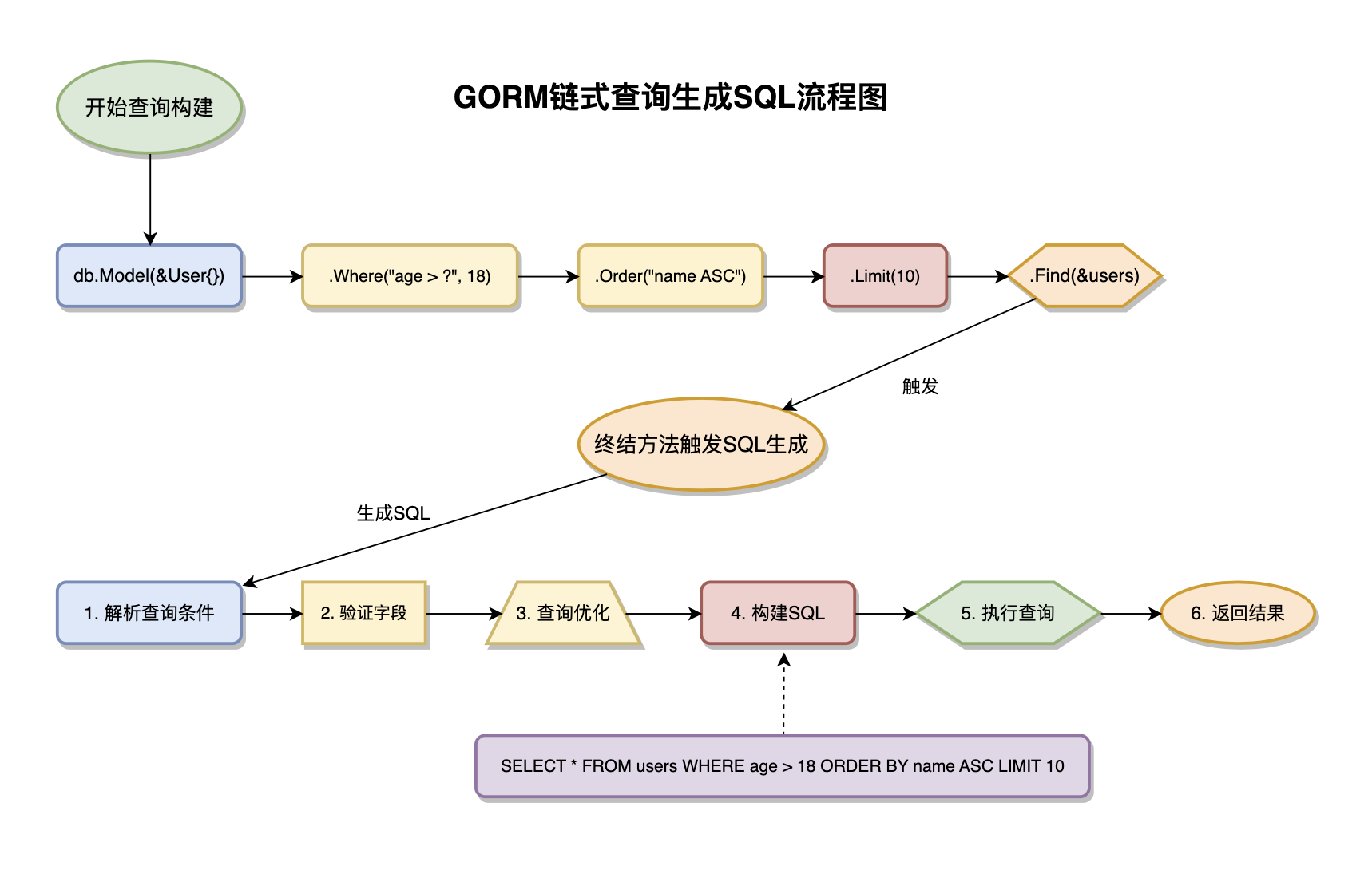
上下文传播机制通过Context在查询链中传递取消信号、超时控制、追踪信息等。这种设计使得查询操作能够很好地集成到Go语言的并发控制体系中,支持请求级别的超时控制和优雅关闭。
GORM支持完整的关联关系映射,包括:Has One关系(一对一,如用户与档案)、Has Many关系(一对多,如用户与订单)、Belongs To关系(多对一,反向关联)、Many To Many关系(多对多,如用户与角色)。每种关联都支持外键定义、关联约束、级联操作等高级配置。
Has One关系实现了一对一的关联映射,通常用于主实体与其详细信息的关联。在数据库层面,通过外键建立两表之间的引用关系,GORM会自动处理外键的设置和约束检查。这种关系支持双向访问,既可以从主实体访问关联实体,也可以通过Belongs To反向访问。关联的生命周期管理包括级联创建、更新和删除,确保数据一致性。
Has Many关系处理一对多的复杂关联场景,如用户拥有多个订单、文章有多个评论等。GORM通过数组字段来表示多个关联对象,支持关联对象的批量操作。在查询时,可以通过条件过滤关联对象,实现精确的数据检索。关联对象的排序、分页等功能确保了大数据量场景下的查询效率。
Many To Many关系通过关联表实现多对多关联,如用户与角色、文章与标签的关系。GORM会自动创建和管理中间表,处理关联关系的增删改查。支持在中间表中添加额外字段来存储关联的元数据,如关联创建时间、权重等信息。这种灵活性使得多对多关系能够适应复杂的业务需求。
关联关系定义示例
type User struct {
ID uint `gorm:"primaryKey"`
Name string `gorm:"size:100"`
// Has One - 一对一关系
Profile Profile `gorm:"foreignKey:UserID;constraint:OnUpdate:CASCADE,OnDelete:SET NULL;"`
// Has Many - 一对多关系
Orders []Order `gorm:"foreignKey:UserID;constraint:OnUpdate:CASCADE,OnDelete:CASCADE;"`
// Many To Many - 多对多关系
Roles []Role `gorm:"many2many:user_roles;constraint:OnUpdate:CASCADE,OnDelete:CASCADE;"`
}
type Profile struct {
ID uint `gorm:"primaryKey"`
UserID uint `gorm:"uniqueIndex"` // 外键
FirstName string `gorm:"size:50"`
LastName string `gorm:"size:50"`
// Belongs To - 反向关联
User User `gorm:"constraint:OnUpdate:CASCADE,OnDelete:CASCADE;"`
}
type Order struct {
ID uint `gorm:"primaryKey"`
UserID uint // 外键
Amount decimal.Decimal
// Belongs To
User User `gorm:"constraint:OnUpdate:CASCADE,OnDelete:CASCADE;"`
// Has Many
Items []OrderItem `gorm:"foreignKey:OrderID"`
}
type Role struct {
ID uint `gorm:"primaryKey"`
Name string `gorm:"size:50"`
// Many To Many
Users []User `gorm:"many2many:user_roles;"`
}
// 关联操作示例
func associationExample(db *gorm.DB) {
// 创建带关联的数据
user := User{
Name: "John Doe",
Profile: Profile{
FirstName: "John",
LastName: "Doe",
},
Orders: []Order{
{Amount: decimal.NewFromFloat(100.50)},
{Amount: decimal.NewFromFloat(200.75)},
},
}
// 自动处理关联创建
db.Create(&user)
// 查询关联数据
var userWithAssociations User
db.Preload("Profile").
Preload("Orders").
Preload("Roles").
First(&userWithAssociations, user.ID)
// 添加关联
role := Role{Name: "Admin"}
db.Create(&role)
db.Model(&user).Association("Roles").Append(&role)
// 删除关联
db.Model(&user).Association("Roles").Delete(&role)
}预加载机制通过Preload方法解决N+1查询问题,核心特性包括:急切加载(一次性加载关联数据)、条件预加载(带条件的关联查询)、嵌套预加载(多层关联预加载)、自定义预加载(自定义关联查询逻辑)。预加载将多次数据库查询合并为少数几次高效查询,显著提升查询性能。
急切加载策略是预加载的基础实现方式,通过分析关联关系自动生成高效的JOIN查询或分步查询。GORM会根据关联类型选择最优的加载策略:对于一对一和多对一关系,通常使用JOIN查询;对于一对多和多对多关系,使用分步查询避免笛卡尔积。这种自动查询优化确保了不同场景下的最佳性能。
条件预加载功能允许在预加载关联数据时应用过滤条件,实现准确的数据查询。可以对关联对象进行排序、限制数量、添加WHERE条件等操作,避免加载不必要的数据。这种精细化控制对于大数据量的关联查询特别重要,能够显著减少内存占用和网络传输。
嵌套预加载支持处理多层次的关联关系,如用户->订单->商品->分类的深层关联。GORM会自动优化查询计划,将多层关联合并为最少的数据库查询次数。通过查询计划缓存和批量查询优化,即使是复杂的嵌套关联也能获得良好的性能表现。
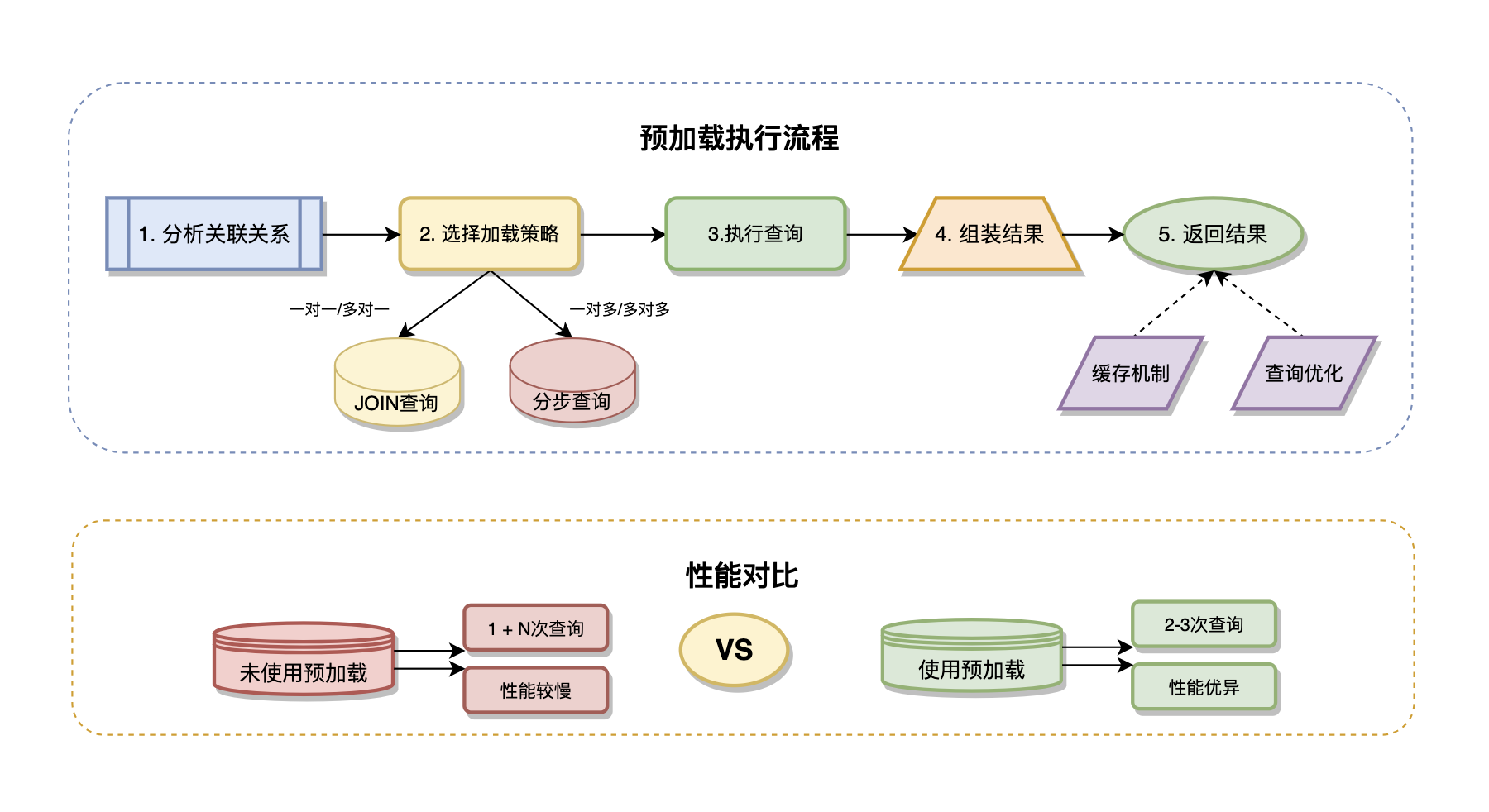
Select优化通过指定需要加载的字段来减少数据传输量,特别是在包含大字段(如BLOB、TEXT)的表中效果显著。结合预加载使用,可以实现精确的字段选择,只加载业务逻辑真正需要的数据。
批量预加载对于需要加载大量关联数据的场景,GORM提供了批量优化策略。通过批量查询和内存缓存,可以显著提高大数据量关联查询的性能。同时支持后台预加载,在不阻塞主查询的情况下异步加载关联数据。
缓存机制集成预加载可以与各种缓存系统集成,如Redis、Memcached等。通过查询结果缓存和关联数据缓存,可以进一步提升重复查询的性能。缓存策略支持TTL设置、版本控制、失效策略等高级功能,确保数据的一致性和实时性。
GORM事务处理通过Begin()、Commit()、Rollback()三个核心方法实现,支持手动事务和自动事务两种模式。提供Transaction()方法用于自动事务管理,发生错误时自动回滚。嵌套事务通过SavePoint实现,支持事务隔离级别设置。
手动事务控制提供了最大的灵活性,开发者可以精确控制事务的开始、提交和回滚时机。通过Begin()方法开启事务后,所有的数据库操作都会在同一个事务上下文中执行,直到显式调用Commit()或Rollback()。这种方式适用于复杂的业务逻辑,特别是需要跨多个数据库操作的场景。
// 手动事务控制示例
func manualTransactionExample(db *gorm.DB) error {
tx := db.Begin()
defer func() {
if r := recover(); r != nil {
tx.Rollback()
}
}()
// 创建用户
if err := tx.Create(&user).Error; err != nil {
tx.Rollback()
return err
}
// 创建用户配置文件
if err := tx.Create(&profile).Error; err != nil {
tx.Rollback()
return err
}
// 提交事务
return tx.Commit().Error
}自动事务管理通过Transaction()方法提供了更加简洁的事务处理方式。当传入的函数正常执行完成时自动提交事务,如果函数返回错误或发生panic时自动回滚事务。这种设计大大简化了事务管理的代码复杂度,减少了忘记提交或回滚导致的问题。
// 自动事务管理示例
func autoTransactionExample(db *gorm.DB) error {
return db.Transaction(func(tx *gorm.DB) error {
// 创建用户
if err := tx.Create(&user).Error; err != nil {
return err // 自动回滚
}
// 创建用户配置文件
if err := tx.Create(&profile).Error; err != nil {
return err // 自动回滚
}
// 函数正常返回,自动提交
return nil
})
}嵌套事务支持通过SavePoint机制实现,允许在一个大事务中创建多个保存点,当内层事务失败时只回滚到最近的保存点而不影响外层事务。这种机制对于复杂业务流程的分步处理特别有用,可以实现细粒度的错误恢复策略。
// 嵌套事务与SavePoint示例
func nestedTransactionExample(db *gorm.DB) error {
return db.Transaction(func(tx *gorm.DB) error {
// 创建用户(外层事务)
if err := tx.Create(&user).Error; err != nil {
return err
}
// 创建保存点
tx.SavePoint("sp1")
// 尝试创建配置文件(内层事务)
if err := tx.Create(&profile).Error; err != nil {
// 只回滚到保存点,不影响用户创建
tx.RollbackTo("sp1")
log.Printf("配置文件创建失败,回滚到保存点: %v", err)
}
// 继续其他操作
tx.Create(&settings)
return nil
})
}统一加锁顺序机制是预防死锁的核心策略,要求在访问多个资源时始终按照相同的顺序进行加锁。比如总是先锁定ID较小的记录,再锁定ID较大的记录,这样可以有效避免循环等待导致的死锁。在业务逻辑设计时,需要制定明确的资源访问规范,确保所有开发者遵循统一的加锁顺序。
事务时间最小化通过优化业务逻辑和预加载相关数据来减少事务持有时间,最小化锁持有的时间窗口。将复杂的计算逻辑移出事务范围,只在事务中执行必要的数据库操作。采用事务拆分策略,将大事务分解为多个小事务,降低锁冲突的概率。
超时控制与检测机制通过设置Context超时来避免长时间等待锁资源,防止死锁的无限期等待。GORM支持在事务级别设置超时时间,当事务执行时间超过阈值时自动回滚。结合数据库的锁等待超时配置(如innodb_lock_wait_timeout),可以构建完整的死锁检测和恢复机制。
乐观锁并发控制通过版本号或时间戳字段来检测数据变更冲突,适用于读多写少的场景。当检测到冲突时,可以选择重试或返回错误让业务层处理。这种方式避免了长时间的锁等待,提高了系统的并发性能。GORM通过模型的Version字段或UpdatedAt字段自动实现乐观锁机制。
连接池并发管理确保每个事务都使用独立的数据库连接,避免了连接共享导致的并发问题。GORM会自动为每个事务分配专用连接,事务结束后归还给连接池。这种设计保证了事务隔离性,同时最大化了连接的利用效率。连接池支持动态调整大小,适应不同的并发压力。
事务隔离级别优化根据业务需求选择合适的事务隔离级别,在数据一致性和并发性能之间找到平衡。读提交(Read Committed)适用于大多数场景,可重复读(Repeatable Read)适用于对一致性要求较高的场景。GORM支持在事务级别动态设置隔离级别,为不同的业务操作提供差异化的并发控制。
原子操作保障GORM确保每个数据库操作的原子性,通过事务机制保证操作要么全部成功,要么全部失败。在并发环境下,原子操作避免了部分更新导致的数据不一致问题。GORM的批量操作、条件更新、删除操作都具备原子性特征,为并发安全提供了基础保障。
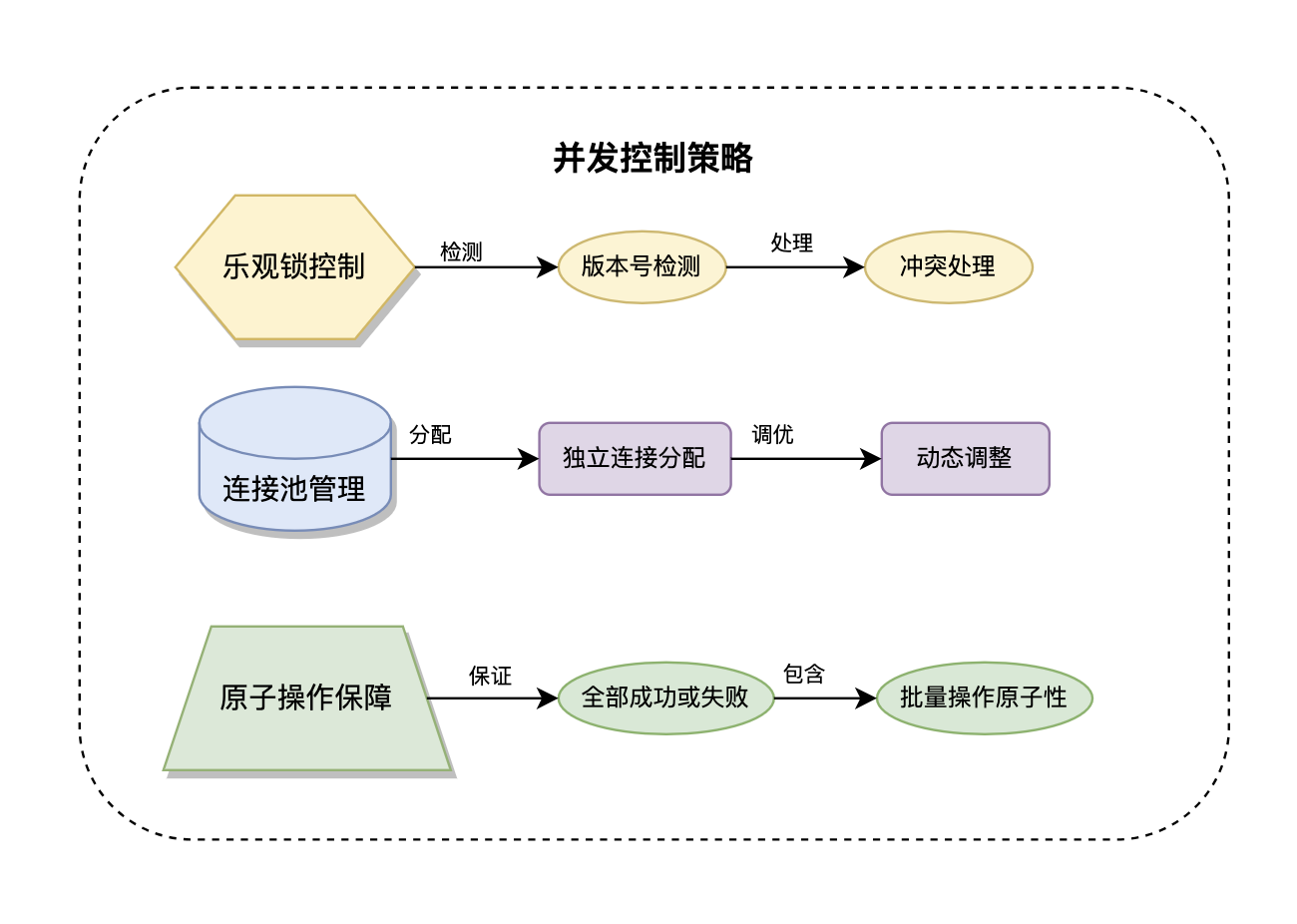
分布式事务协调在微服务架构中,GORM可以与Seata、TCC等分布式事务框架集成,实现跨服务的数据一致性。通过两阶段提交协议和补偿机制,确保分布式环境下的事务完整性。这种设计对于电商、金融等对数据一致性要求极高的场景尤为重要。
GORM钩子函数按生命周期分为三大类:创建钩子(BeforeCreate、AfterCreate)、更新钩子(BeforeUpdate、AfterUpdate、BeforeSave、AfterSave)、删除和查询钩子(BeforeDelete、AfterDelete、AfterFind)。
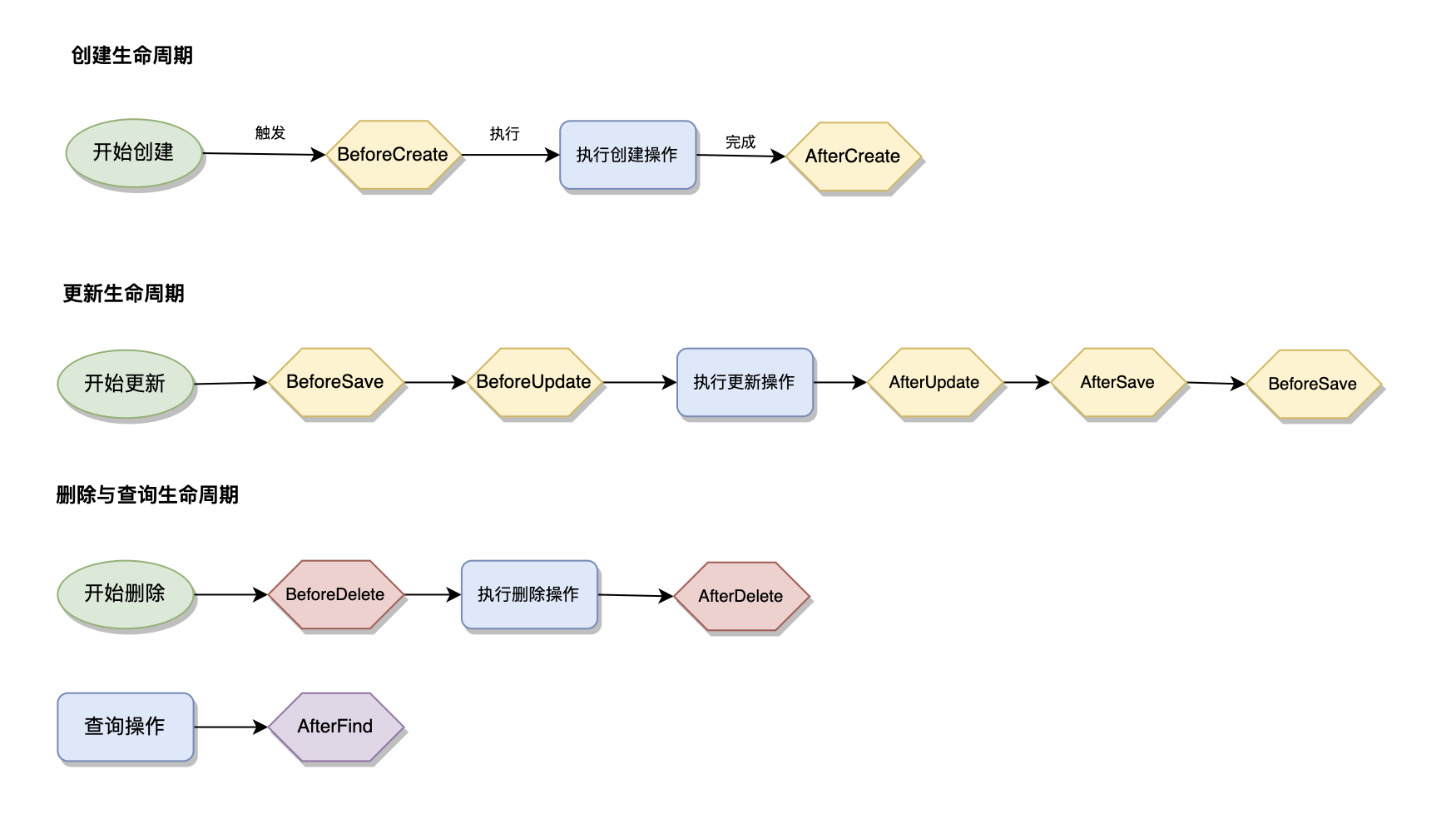
创建生命周期钩子包括BeforeCreate和AfterCreate,分别在数据插入前后执行。BeforeCreate常用于数据预处理、默认值设置、数据验证等场景,而AfterCreate则用于后置处理如缓存更新、消息发送、关联数据创建等。这种前后分离的设计使得业务逻辑的组织更加清晰。
更新生命周期钩子通过BeforeUpdate和AfterUpdate来处理数据修改场景。BeforeUpdate可以实现数据变更检测、权限验证、数据标准化等功能,AfterUpdate则处理变更后的业务逻辑如历史记录创建、缓存失效、事件通知等。BeforeSave和AfterSave作为通用的保存钩子,在创建和更新操作中都会被触发。
删除和查询钩子处理数据删除和检索场景。BeforeDelete可以实现删除权限检查、关联数据清理、软删除逻辑等,AfterDelete处理删除后的清理工作。AfterFind在数据查询后执行,常用于数据解密、格式转换、权限过滤等场景。
// 钩子函数实现示例
type User struct {
ID uint `gorm:"primaryKey"`
Username string `gorm:"uniqueIndex"`
Password string `json:"-"`
Email string `gorm:"uniqueIndex"`
CreatedAt time.Time
UpdatedAt time.Time
DeletedAt gorm.DeletedAt `gorm:"index"`
Version int `gorm:"default:1"` // 乐观锁版本号
}
// 创建前钩子
func (u *User) BeforeCreate(tx *gorm.DB) error {
// 密码加密
if u.Password != "" {
hashedPassword, err := bcrypt.GenerateFromPassword([]byte(u.Password), bcrypt.DefaultCost)
if err != nil {
return err
}
u.Password = string(hashedPassword)
}
// 数据验证
if len(u.Username) < 3 {
return errors.New("用户名长度不能少于3位")
}
return nil
}
// 创建后钩子
func (u *User) AfterCreate(tx *gorm.DB) error {
// 发送欢迎邮件
go sendWelcomeEmail(u.Email)
// 创建用户配置文件
profile := Profile{UserID: u.ID, DisplayName: u.Username}
return tx.Create(&profile).Error
}
// 更新前钩子
func (u *User) BeforeUpdate(tx *gorm.DB) error {
// 乐观锁版本检查
var count int64
tx.Model(&User{}).Where("id = ? AND version = ?", u.ID, u.Version).Count(&count)
if count == 0 {
return errors.New("数据已被其他用户修改,请刷新后重试")
}
// 版本号递增
u.Version++
return nil
}
// 查询后钩子
func (u *User) AfterFind(tx *gorm.DB) error {
// 记录访问日志
go logUserAccess(u.ID)
// 敏感信息脱敏
if u.Email != "" {
u.Email = maskEmail(u.Email)
}
return nil
}
// 删除前钩子
func (u *User) BeforeDelete(tx *gorm.DB) error {
// 检查是否有关联数据
var orderCount int64
tx.Model(&Order{}).Where("user_id = ?", u.ID).Count(&orderCount)
if orderCount > 0 {
return errors.New("用户存在订单记录,无法删除")
}
return nil
}钩子执行顺序严格按照GORM定义的生命周期阶段进行,保证了业务逻辑的可预测性。在同一个生命周期阶段,多个钩子按照定义顺序依次执行,支持钩子链式调用。这种设计使得复杂的业务逻辑可以分解为多个独立的钩子函数,提高了代码的可维护性。
错误中断机制确保当任何一个钩子函数返回错误时,整个操作链会被中断并回滚。这种故障快速失败的设计保证了数据的一致性,避免了部分操作成功部分操作失败的不一致状态。同时,钩子函数可以通过上下文传递参数和状态,实现钩子间的协作。
钩子执行性能优化对于频繁执行的钩子函数,GORM提供了多种优化策略。包括钩子缓存机制,将钩子函数的反射信息缓存以减少运行时开销;异步钩子执行,对于不影响主流程的钩子(如日志记录)可以异步执行;条件钩子触发,根据特定条件选择性执行钩子,避免不必要的计算。
企业级钩子应用模式在大型应用中,钩子系统常用于实现审计追踪、数据同步、权限控制、业务规则验证等企业级功能。通过设计通用的钩子接口和插件化架构,可以实现钩子功能的模块化管理和热插拔,提高系统的可扩展性和可维护性。
GORM的性能优化涵盖了从查询构建到数据库连接的全链路优化策略。这些优化不仅能够显著提升应用性能,还能减少数据库负载和网络传输开销。通过合理运用这些优化技术,可以构建出高性能、可扩展的数据访问层,满足大规模应用的性能要求。
预加载机制优化是解决关联查询性能问题的核心策略。通过Preload方法可以在查询主对象时同时加载关联对象,将多次查询合并为少数几次查询。Joins方法提供了更细粒度的控制,可以使用SQL连接来一次性获取相关数据,特别适合一对一和多对一关系的优化。
字段选择优化通过Select方法指定需要查询的字段,避免查询不必要的大字段如TEXT、BLOB等。这种策略在处理宽表或包含大量字段的表时效果尤为明显,可以大幅减少网络传输量和内存占用。结合Omit方法可以排除特定字段,实现灵活的字段控制。
批量操作优化通过CreateInBatches、FindInBatches等方法实现大量数据的高效处理。批量创建可以显著减少数据库往返次数,批量查询则避免了大结果集导致的内存问题。这些方法还支持自定义批次大小,可以根据具体场景进行调优。
// 性能优化示例
func performanceOptimizationExample(db *gorm.DB) {
// 预加载优化 - 解决N+1问题
var users []User
// 不好的方式 - 会导致N+1查询
// db.Find(&users)
// for _, user := range users {
// db.Model(&user).Association("Orders").Find(&user.Orders)
// }
// 优化方式 - 使用预加载
db.Preload("Orders").Preload("Profile").Find(&users)
// 或使用Joins优化一对一关系
db.Joins("Profile").Find(&users)
// 字段选择优化
var userSummary []User
db.Select("id, username, email").Find(&userSummary)
// 批量操作优化
var orders []Order
result := db.CreateInBatches(orders, 100) // 每批100条
// 分页查询优化
var paginatedUsers []User
db.Scopes(Paginate(page, pageSize)).Find(&paginatedUsers)
// 索引提示优化
db.Clauses(hints.UseIndex("idx_user_email")).Where("email = ?", email).Find(&user)
// 原生SQL优化复杂查询
db.Raw("SELECT u.*, COUNT(o.id) as order_count FROM users u LEFT JOIN orders o ON u.id = o.user_id GROUP BY u.id").Scan(&userStats)
}
// 分页作用域
func Paginate(page, pageSize int) func(db *gorm.DB) *gorm.DB {
return func(db *gorm.DB) *gorm.DB {
if page == 0 {
page = 1
}
if pageSize == 0 {
pageSize = 10
}
offset := (page - 1) * pageSize
return db.Offset(offset).Limit(pageSize)
}
}连接池调优通过合理配置最大连接数、最大空闲连接数、连接生命周期等参数来优化数据库连接性能。根据应用的并发量和数据库性能来调整这些参数,可以在性能和资源消耗之间找到最佳平衡点。
查询结果缓存通过集成Redis或内存缓存来缓存频繁查询的结果,减少数据库访问。支持TTL设置、标签失效、分层缓存等高级功能。对于读多写少的场景,缓存能够显著提升查询性能。
读写分离与分库分表在大规模应用中,通过配置多个数据源实现读写分离,将读操作分发到从库,写操作路由到主库。分库分表则通过数据分片来水平扩展数据库性能,GORM支持通过插件实现这些高级功能。
内存优化策略包括结果集流式处理,通过FindInBatches避免大结果集的内存溢出;对象池复用,减少频繁的内存分配和GC压力;查询结果缓存,将热点数据缓存在Redis或内存中,减少数据库访问。这些策略特别适用于高并发、大数据量的应用场景。
SQL执行计划优化通过分析数据库执行计划,识别慢查询的根本原因。GORM提供的SQL日志和执行时间统计,结合数据库的EXPLAIN功能,可以精确定位性能瓶颈。常见的优化包括索引优化、查询重写、分区表应用、统计信息更新等数据库层面的调优。
并发控制优化在高并发场景下,通过连接池调优、事务隔离级别优化、乐观锁替代悲观锁等策略提升并发性能。GORM的连接池支持动态调整,可以根据系统负载自动扩缩容,确保在不同业务压力下都能保持最佳性能。
N+1查询问题是ORM框架中最常见的性能陷阱,表现为查询N个主对象需要执行1次主查询加N次关联查询。GORM提供了多种解决方案来避免这个问题。
Preload预加载是最直接的解决方案,通过在主查询时指定需要预加载的关联关系,GORM会自动生成额外的查询来获取关联数据。支持嵌套预加载和条件预加载,可以处理复杂的关联关系场景。
Joins连接查询适用于一对一和多对一关系,通过SQL连接将主表和关联表的数据在一次查询中获取。这种方式查询效率最高,但需要注意笛卡尔积问题和数据重复的处理。
批量查询策略通过收集所有需要查询的关联ID,然后执行一次IN查询来获取所有关联数据。这种方式特别适合一对多和多对多关系,可以有效控制查询次数。
| 解决方案 | 查询次数 | 适用场景 | 数据量级 | 性能提升 | 内存消耗 |
|---|---|---|---|---|---|
| Preload预加载 | 2次 | 确定需要关联数据的场景 | 小-中 | ⭐⭐⭐⭐ | 中 |
| Joins连接查询 | 1次 | 一对一、多对一关系 | 小-中 | ⭐⭐⭐⭐⭐ | 低 |
| Select优化 | 1次 | 只需要部分字段的场景 | 任意 | ⭐⭐⭐ | 低 |
| 延迟加载 | N次 | 不确定是否需要关联数据 | 小-中 | ⭐⭐ | 低 |
| 批量查询 | 2-3次 | 一对多、多对多关系 | 中-大 | ⭐⭐⭐⭐ | 中 |
| 数据库读写分离 | 根据策略 | 读多写少的高并发场景 | 大 | ⭐⭐⭐⭐ | 低 |
| 分库分表 | 根据分片 | 超大数据量、高并发写入 | 超大 | ⭐⭐⭐⭐⭐ | 低 |
| 查询结果缓存 | 0-1次 | 热点数据频繁查询 | 任意 | ⭐⭐⭐⭐⭐ | 高 |
场景选择建议:
迁移系统概念是数据库版本控制的核心机制,它将数据库结构的变更以代码的形式进行管理,使得数据库结构演进能够像应用代码一样进行版本控制、回滚和部署。迁移系统解决了传统数据库管理中手动执行DDL语句容易出错、难以追踪、无法回滚的问题,为数据库运维提供了标准化、自动化的管理方式。
迁移系统的核心价值在于它将数据库结构变更从临时性的运维操作转变为代码化的可管理资产。通过迁移脚本,开发团队可以确保不同环境间的数据库结构一致性,实现数据库变更的自动化部署,并在出现问题时快速回滚到安全状态。这种方式大大降低了数据库运维的风险和复杂度。
企业级迁移管理需求包括环境同步、团队协作、风险控制等多个方面。在多人开发的项目中,迁移系统确保了每个开发者的本地环境与生产环境保持一致;在多环境部署中,迁移系统保证了从开发、测试到生产环境的结构一致性;在版本发布中,迁移系统提供了可靠的数据库升级和降级机制。
GORM迁移系统通过AutoMigrate()自动迁移和Migrator手动迁移两种方式管理数据库结构变更。
自动迁移根据模型结构自动创建表、添加字段、创建索引,适合开发环境快速迭代。
手动迁移提供精确的DDL控制,支持版本管理、回滚机制、数据迁移,适合生产环境。迁移功能包括表操作(创建、删除、重命名)、字段操作(添加、删除、修改)、索引管理、约束管理等。
自动迁移工作原理基于模型驱动的设计理念,通过比较Go结构体定义与实际数据库结构的差异,自动生成必要的DDL语句并执行。GORM会分析结构体的字段定义、标签配置、类型映射等信息,识别出需要创建的表、添加的字段、修改的索引等变更项,然后按照安全的顺序执行这些变更操作。
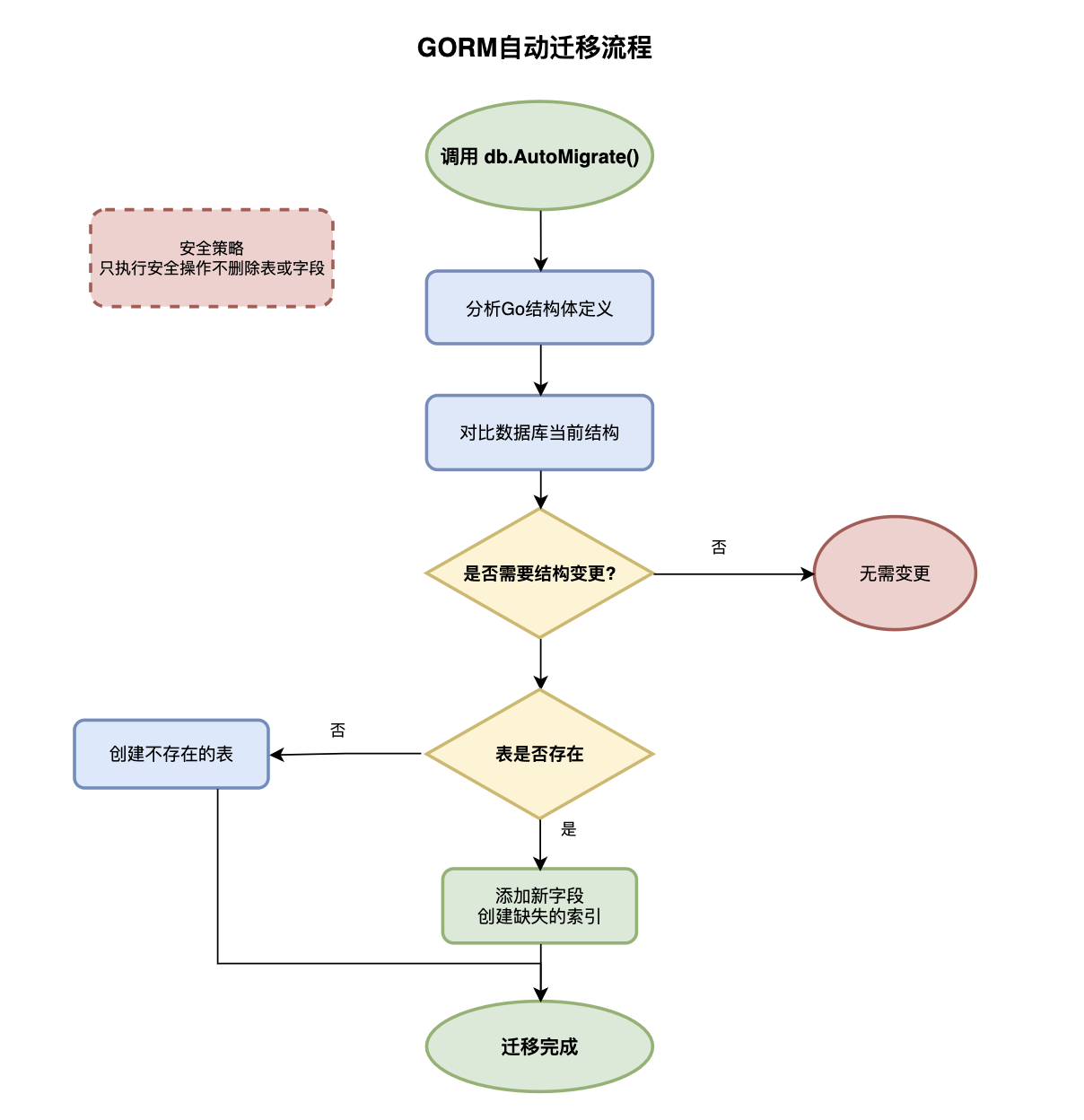
自动迁移的适用场景主要集中在开发阶段和快速原型开发中。当需求变化频繁、数据库结构调整较多时,自动迁移能够显著提高开发效率,让开发者专注于业务逻辑而非数据库维护。特别是在项目初期,当数据库设计尚不稳定时,自动迁移提供了极大的便利性。
自动迁移的安全机制采用了保守的变更策略,只执行安全的操作如创建表、添加字段、创建索引等,而不会执行可能导致数据丢失的操作如删除表、删除字段、修改字段类型等。这种设计确保了数据的安全性,避免了因自动操作导致的数据丢失风险。
// 自动迁移机制示例
func autoMigrationExample(db *gorm.DB) {
// 定义模型结构
type User struct {
ID uint `gorm:"primaryKey;autoIncrement"`
Username string `gorm:"uniqueIndex;size:50;not null"`
Email string `gorm:"uniqueIndex;size:100;not null"`
Password string `gorm:"size:255;not null"`
Profile Profile `gorm:"constraint:OnUpdate:CASCADE,OnDelete:SET NULL;"`
CreatedAt time.Time `gorm:"autoCreateTime"`
UpdatedAt time.Time `gorm:"autoUpdateTime"`
DeletedAt gorm.DeletedAt `gorm:"index"`
}
type Profile struct {
ID uint `gorm:"primaryKey"`
UserID uint `gorm:"uniqueIndex;not null"`
RealName string `gorm:"size:100"`
Avatar string `gorm:"size:255"`
Bio string `gorm:"type:text"`
}
// 自动迁移执行
err := db.AutoMigrate(&User{}, &Profile{})
if err != nil {
log.Fatal("自动迁移失败:", err)
}
// 检查迁移结果
migrator := db.Migrator()
// 验证表是否创建成功
if migrator.HasTable(&User{}) {
log.Println("User表创建成功")
}
// 验证字段是否添加成功
if migrator.HasColumn(&User{}, "username") {
log.Println("username字段添加成功")
}
// 验证索引是否创建成功
if migrator.HasIndex(&User{}, "idx_users_username") {
log.Println("用户名索引创建成功")
}
}手动迁移设计理念基于精确控制和版本管理的思想,提供了完整的DDL操作能力和迁移生命周期管理。开发者可以编写具体的迁移脚本,精确定义每一步的数据库变更操作,确保变更的可预测性和可控性。手动迁移支持复杂的数据变更、跨表操作、条件约束等高级功能。
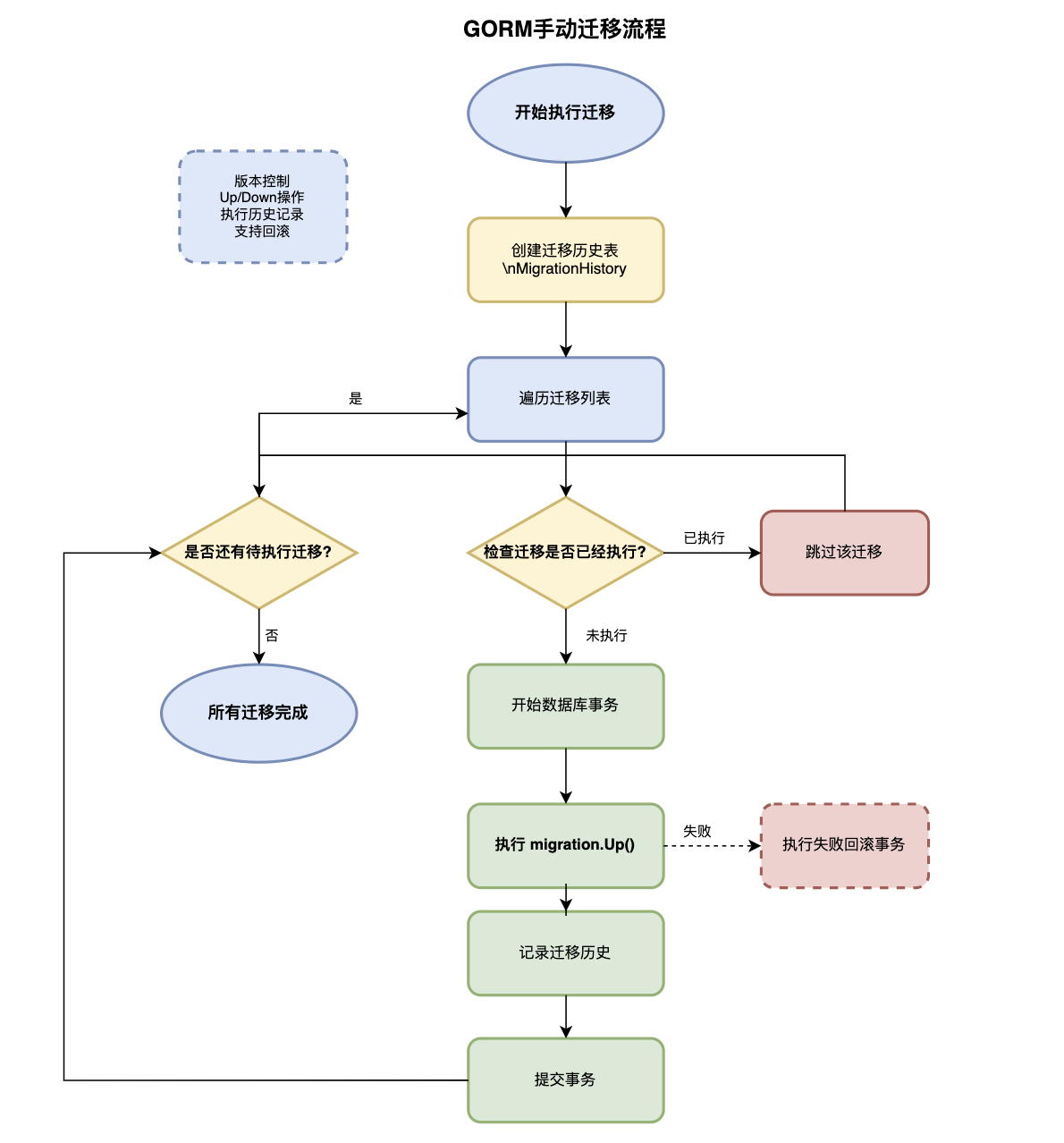
手动迁移的版本化管理通过迁移文件的命名约定和执行历史记录,实现了数据库变更的版本控制。每个迁移文件包含唯一的版本号、描述信息和Up/Down操作,支持前进式部署和回滚操作。迁移历史表记录了已执行的迁移信息,确保迁移的幂等性和一致性。
手动迁移的高级功能包括复杂数据变更、批量数据处理、性能优化等企业级需求。支持在迁移过程中执行自定义的Go代码逻辑,处理数据格式转换、业务规则应用、历史数据清理等复杂场景。提供了事务支持、错误处理、回滚机制等可靠性保障。
// 手动迁移核心结构
type Migration struct {
Version string
Name string
Up func(*gorm.DB) error
Down func(*gorm.DB) error
}
type MigrationHistory struct {
ID uint `gorm:"primaryKey"`
Version string `gorm:"uniqueIndex;size:50"`
Name string `gorm:"size:255"`
AppliedAt time.Time
}
// 迁移执行器
func runMigration(db *gorm.DB, migration Migration) error {
// 检查是否已执行
var count int64
db.Model(&MigrationHistory{}).Where("version = ?", migration.Version).Count(&count)
if count > 0 {
return nil // 已执行,跳过
}
// 在事务中执行迁移
return db.Transaction(func(tx *gorm.DB) error {
if err := migration.Up(tx); err != nil {
return err
}
// 记录迁移历史
history := MigrationHistory{
Version: migration.Version,
Name: migration.Name,
AppliedAt: time.Now(),
}
return tx.Create(&history).Error
})
}
// 迁移示例
func setupMigrations(db *gorm.DB) {
// 创建迁移历史表
db.AutoMigrate(&MigrationHistory{})
// 迁移1:创建用户表
migration1 := Migration{
Version: "20250120_001",
Name: "create_users_table",
Up: func(db *gorm.DB) error {
return db.Migrator().CreateTable(&User{})
},
Down: func(db *gorm.DB) error {
return db.Migrator().DropTable(&User{})
},
}
// 迁移2:添加字段
migration2 := Migration{
Version: "20250120_002",
Name: "add_user_status",
Up: func(db *gorm.DB) error {
return db.Exec("ALTER TABLE users ADD COLUMN status VARCHAR(20) DEFAULT 'active'").Error
},
Down: func(db *gorm.DB) error {
return db.Migrator().DropColumn(&User{}, "status")
},
}
// 执行迁移
runMigration(db, migration1)
runMigration(db, migration2)
}| 对比维度 | 自动迁移 | 手动迁移 |
|---|---|---|
| 适用环境 | 开发环境、快速原型 | 生产环境、企业级应用 |
| 控制精度 | 模型驱动,自动生成 | 完全手动控制,精确定义 |
| 安全性 | 只执行安全操作,避免数据丢失 | 需要开发者保证安全性 |
| 版本管理 | 通过代码版本控制模型变更 | 独立的迁移版本管理系统 |
| 回滚能力 | 不支持回滚 | 支持Up/Down双向操作 |
| 复杂度 | 简单易用,零配置 | 需要编写迁移脚本 |
| 数据处理 | 仅结构变更,不处理数据 | 支持复杂数据变更逻辑 |
| 执行记录 | 无执行历史记录 | 完整的执行历史和状态跟踪 |
| 性能优化 | 自动生成,可能不是最优 | 可针对性能进行精细优化 |
| 团队协作 | 通过模型定义协作 | 通过迁移脚本版本控制协作 |
| 错误处理 | 自动错误检测和跳过 | 自定义错误处理逻辑 |
| 学习成本 | 低,只需了解模型定义 | 中等,需要了解迁移概念和SQL |
迁移策略选择应该根据项目阶段和环境特点进行。在开发阶段,推荐使用自动迁移快速迭代;在测试和生产环境,建议使用手动迁移确保精确控制。对于大型项目,可以采用混合策略:开发环境使用自动迁移,然后将变更转换为手动迁移脚本部署到生产环境。
迁移测试与验证是生产部署的关键环节。包括迁移脚本的语法验证、执行时间评估、数据完整性检查、回滚测试等。建议在与生产环境相同的数据量和结构的测试环境中进行充分验证,确保迁移过程的可靠性和性能表现。
大表迁移优化对于千万级以上的大表,需要采用特殊的迁移策略。包括分批处理、在线迁移、影子表技术等。GORM的手动迁移提供了实现这些高级技术的基础能力,结合数据库特性可以实现零停机迁移。
监控与应急处理生产迁移需要实时监控和完善的应急预案。包括迁移进度监控、性能指标跟踪、错误告警、快速回滚等机制。通过完善的监控体系,可以及时发现问题并采取相应措施,确保业务的连续性。
GORM错误处理采用链式错误传播机制,通过Error字段统一管理错误状态。提供预定义错误类型(ErrRecordNotFound、ErrInvalidTransaction等)用于精确错误判断,支持自定义错误处理逻辑和错误恢复策略。
链式错误传播设计建立了统一的错误处理模式,每个GORM操作都会返回包含Error字段的结果对象,错误信息在操作链中自动传播直至被处理。这种设计避免了传统数据库操作中需要在每步都检查错误的繁琐代码,提供了更加优雅的错误处理方式。当操作链中的任何环节出现错误时,后续操作会自动跳过,确保错误的快速失败。
预定义错误类型体系为常见的数据库操作异常提供了标准化的错误分类。ErrRecordNotFound用于处理查询无结果的情况,ErrInvalidTransaction表示事务状态异常,ErrNotImplemented表示功能未实现,ErrDuplicatedKey处理唯一约束冲突等。通过errors.Is()进行错误类型判断,应用可以针对不同错误场景实施相应的处理策略,如重试、降级、用户提示等。
业务层错误扩展机制支持开发者定义特定的错误类型和处理逻辑,通过钩子函数在错误发生时执行自定义的错误处理代码。这种机制使得错误处理能够与业务规则紧密结合,实现错误日志记录、错误通知、错误恢复、用户友好提示等高级功能。支持错误的上下文信息保留,便于问题的精确定位和分析。
// 错误处理机制示例
func errorHandlingExample(db *gorm.DB) {
// 标准错误处理模式
var user User
result := db.Where("email = ?", "test@example.com").First(&user)
// 精确错误类型判断
switch {
case errors.Is(result.Error, gorm.ErrRecordNotFound):
log.Println("用户不存在,创建默认用户")
createDefaultUser(db)
case result.Error != nil:
log.Printf("数据库查询错误: %v", result.Error)
return handleDatabaseError(result.Error)
default:
log.Printf("查询成功,用户ID: %d", user.ID)
}
// 自定义错误类型
type ValidationError struct {
Field string
Message string
Err error
}
func (e *ValidationError) Error() string {
return fmt.Sprintf("字段 %s 验证失败: %s", e.Field, e.Message)
}
// 错误恢复中间件
db.Callback().Create().Before("gorm:create").Register("error_recovery", func(db *gorm.DB) {
defer func() {
if r := recover(); r != nil {
log.Printf("操作恢复: %v", r)
db.AddError(fmt.Errorf("操作异常: %v", r))
}
}()
})
}调试技巧涵盖多层次Logger配置(Silent、Error、Warn、Info模式)、慢查询阈值监控、DryRun模式验证、ToSQL方法转换。SQL分析工具包括执行计划分析、性能钩子注册、分布式链路追踪、实时监控集成等企业级诊断能力。
Logger配置管理提供了分级的日志控制策略,Silent模式用于生产环境避免性能影响,Error模式只记录错误信息,Warn模式包含警告和错误,Info模式提供完整的SQL执行日志。支持自定义Logger实现,可以与现有的日志系统(如logrus、zap)无缝集成,实现统一的日志管理和分析。
慢查询检测系统通过SlowThreshold参数设置慢查询阈值,自动识别执行时间超标的数据库操作。结合钩子函数可以实现慢查询的实时监控、性能数据收集、自动告警等功能。支持动态调整阈值,适应不同业务场景的性能要求。这种主动式监控机制帮助开发者及时发现性能瓶颈。
DryRun模式验证提供了SQL语句的预览和验证功能,在不实际执行数据库操作的情况下生成对应的SQL语句和参数。这种机制对于调试复杂查询、验证SQL正确性、性能预估等场景特别有用。ToSQL方法进一步扩展了这一功能,可以将任何GORM操作转换为可执行的SQL语句,便于问题排查和性能分析。
// 调试工具使用示例
func debuggingToolsExample(db *gorm.DB) {
// 自定义Logger配置
customLogger := logger.New(
log.New(os.Stdout, "\r\n", log.LstdFlags),
logger.Config{
SlowThreshold: 100 * time.Millisecond,
LogLevel: logger.Info,
IgnoreRecordNotFoundError: true,
Colorful: true,
},
)
db.Logger = customLogger
// DryRun模式调试
session := db.Session(&gorm.Session{DryRun: true})
stmt := session.Model(&User{}).Where("status = ?", "active").Find(&[]User{}).Statement
fmt.Printf("SQL: %s\n参数: %v\n", stmt.SQL.String(), stmt.Vars)
// ToSQL方法获取SQL
sql := db.ToSQL(func(tx *gorm.DB) *gorm.DB {
return tx.Model(&User{}).
Joins("Profile").
Where("users.age > ?", 18).
Order("users.created_at DESC").
Limit(10).
Find(&[]User{})
})
fmt.Println("生成SQL:", sql)
// 性能监控钩子
db.Callback().Query().Before("gorm:query").Register("perf_start", func(db *gorm.DB) {
db.InstanceSet("query_start_time", time.Now())
})
db.Callback().Query().After("gorm:query").Register("perf_end", func(db *gorm.DB) {
if startTime, exists := db.InstanceGet("query_start_time"); exists {
duration := time.Since(startTime.(time.Time))
if duration > 50*time.Millisecond {
log.Printf("慢查询警告 - 耗时: %v, SQL: %s",
duration, db.Statement.SQL.String())
}
}
})
}执行计划分析能力通过EXPLAIN语句分析查询的执行策略,识别性能瓶颈和优化机会。GORM支持直接执行EXPLAIN查询,结合Raw方法可以获取详细的执行计划信息。这种分析能力帮助开发者理解数据库的查询优化策略,指导索引设计和查询重构。
分布式链路追踪集成支持与OpenTelemetry、Jaeger、Zipkin等分布式追踪系统的集成,通过Span标记和上下文传播实现数据库操作的完整链路追踪。在微服务架构中,这种能力对于定位跨服务的性能问题和错误传播路径至关重要。支持自定义Span属性,记录SQL语句、执行时间、影响行数等关键信息。
实时监控数据收集通过钩子系统可以集成Prometheus、InfluxDB等监控系统,实时收集数据库操作的关键指标。包括查询响应时间分布、错误率统计、并发连接数、慢查询频率等。这些数据为性能调优、容量规划、SLA监控提供了重要依据。
智能错误恢复策略实现了多层次的容错机制,包括自动重试处理临时网络故障,熔断器模式防止级联故障,降级策略在数据库不可用时切换到缓存或只读模式。这些策略与业务逻辑结合,可以显著提升系统的可用性和用户体验。支持可配置的重试次数、退避策略、熔断阈值等参数。
错误聚合分析系统通过对生产环境错误数据的收集和分析,识别系统的薄弱环节和高频错误模式。结合错误上下文信息(用户ID、请求路径、查询参数、环境信息等),可以精确定位问题原因和影响范围。支持错误趋势分析、异常模式识别、根因分析等高级功能。
自动化运维建议基于监控数据和错误分析,构建智能的运维建议系统。能够自动识别缺失的索引、推荐查询优化方案、预警资源瓶颈、建议架构调整等。这种数据驱动的运维方式大大降低了人工维护成本,提高了系统的稳定性和性能表现。
GORM插件系统基于回调机制和钩子注册实现,支持在数据库操作的生命周期中插入自定义逻辑。插件通过Plugin接口定义,包含Name()方法和Initialize()方法。
回调机制设计是插件系统的基础,GORM将数据库操作分解为多个生命周期阶段,每个阶段都提供了回调注册点。插件可以在这些关键节点插入自定义逻辑,如数据预处理、后置处理、错误处理等。这种事件驱动的架构使得插件能够无缝集成到GORM的执行流程中。
Plugin接口标准化定义了插件的基本结构和行为规范。Name()方法返回插件的唯一标识符,用于插件管理和冲突检测。Initialize()方法在插件加载时被调用,负责设置回调函数、配置参数、初始化资源等工作。这种标准化接口确保了不同插件之间的兼容性和一致性。
回调注册机制允许插件在特定的操作阶段注册回调函数。GORM提供了Before和After两种类型的回调点,分别在操作执行前后触发。插件可以根据业务需求选择合适的注册点,实现精确的功能插入。支持多个插件在同一回调点注册,按照注册顺序依次执行。
开发自定义插件需要实现Plugin接口,在Initialize方法中注册回调函数到相应的操作阶段(Create、Query、Update、Delete、Raw、Row)。插件可以实现数据加密、审计日志、性能监控、缓存管理等功能。支持插件链式调用、条件执行、错误处理等高级特性。
自定义插件开发示例
// AuditPlugin 审计插件,用于记录数据库操作日志
// 实现了gorm.Plugin接口,可以在数据库操作前后插入自定义逻辑
type AuditPlugin struct {
enabled bool // 是否启用插件
tableName string // 审计日志表名
logger *log.Logger // 日志记录器
}
// Name 返回插件的唯一标识符
// GORM使用此名称进行插件管理和冲突检测
func (p *AuditPlugin) Name() string {
return "audit_plugin"
}
// Initialize 插件初始化方法,在插件加载时被调用
// 负责注册回调函数到GORM的生命周期钩子
func (p *AuditPlugin) Initialize(db *gorm.DB) error {
// 注册创建操作的后置回调,在数据创建完成后执行
db.Callback().Create().After("gorm:create").Register("audit:create", p.auditCallback)
// 注册更新操作的后置回调,记录数据变更
db.Callback().Update().After("gorm:update").Register("audit:update", p.auditCallback)
// 注册删除操作的后置回调,记录删除操作
db.Callback().Delete().After("gorm:delete").Register("audit:delete", p.auditCallback)
return nil
}
// auditCallback 审计回调函数,记录数据库操作日志
// 在每次数据库操作完成后被调用
func (p *AuditPlugin) auditCallback(db *gorm.DB) {
if !p.enabled {
return // 插件未启用时直接返回
}
// 获取操作信息
operation := "UNKNOWN"
if db.Statement.SQL.String() != "" {
// 根据SQL语句判断操作类型
sqlStr := strings.ToUpper(db.Statement.SQL.String())
if strings.Contains(sqlStr, "INSERT") {
operation = "CREATE"
} else if strings.Contains(sqlStr, "UPDATE") {
operation = "UPDATE"
} else if strings.Contains(sqlStr, "DELETE") {
operation = "DELETE"
}
}
// 记录审计日志,包含表名、操作类型、影响行数
p.logger.Printf("Audit Log - Table: %s, Operation: %s, RowsAffected: %d",
db.Statement.Table, operation, db.RowsAffected)
}
// NewAuditPlugin 创建新的审计插件实例
// 提供配置参数进行插件初始化
func NewAuditPlugin(enabled bool, tableName string) *AuditPlugin {
return &AuditPlugin{
enabled: enabled,
tableName: tableName,
logger: log.New(os.Stdout, "[AUDIT] ", log.LstdFlags),
}
}
// 使用示例:展示如何在应用中集成审计插件
func setupPlugin(db *gorm.DB) {
// 创建审计插件实例
plugin := NewAuditPlugin(true, "audit_logs")
// 将插件注册到GORM实例
db.Use(plugin)
}GORM在微服务架构中通过服务隔离、数据库分离、连接池管理实现数据访问层的优化。每个微服务维护独立的数据库实例和GORM配置,避免服务间的数据耦合。
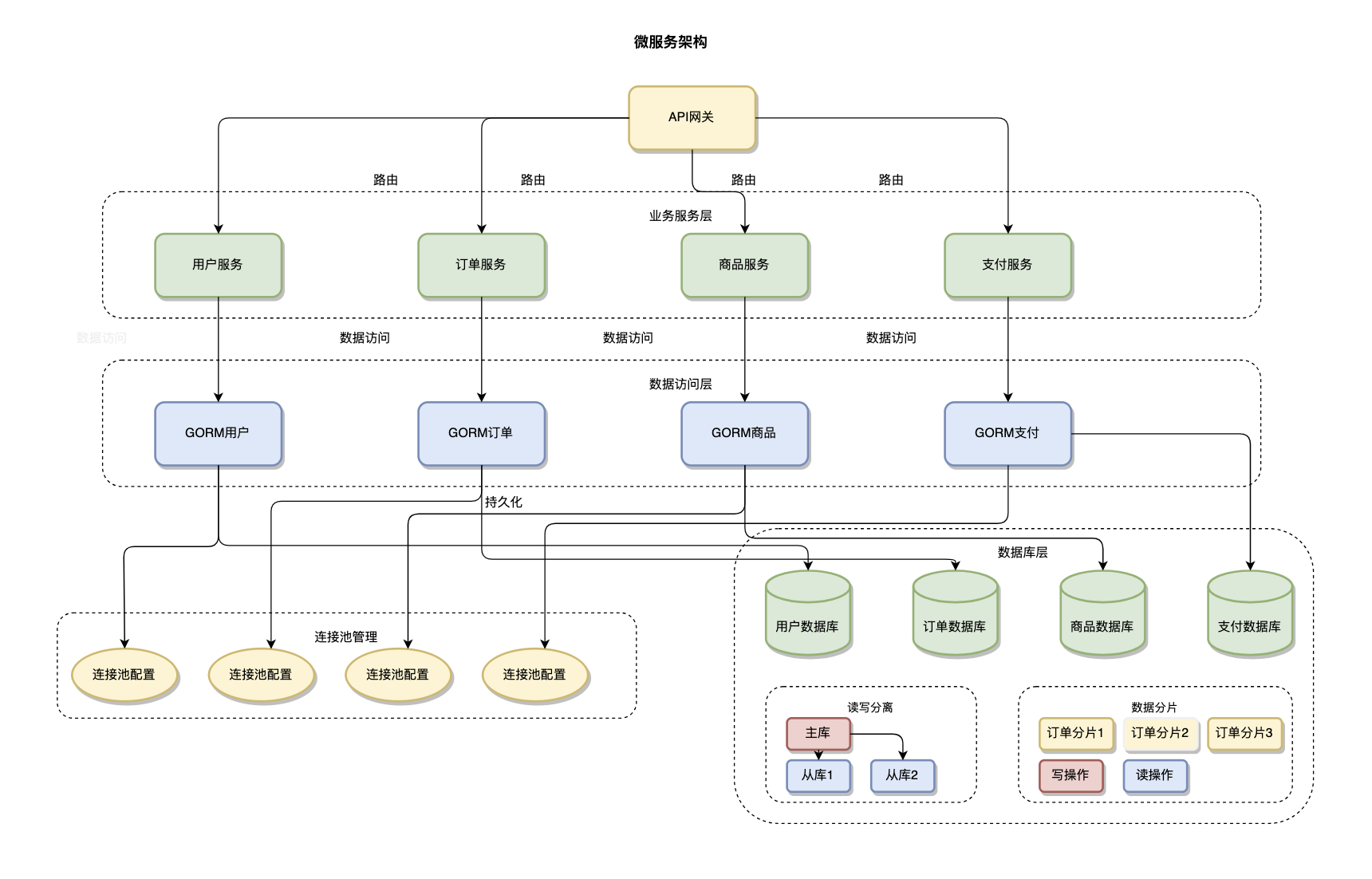
服务数据隔离设计是微服务架构中的重要原则,每个微服务应该拥有独立的数据库和数据模型。GORM通过为每个服务配置独立的数据库连接和模型定义,确保服务间的数据边界清晰。这种隔离不仅避免了数据耦合,还提高了系统的容错性和可维护性。服务间的数据共享通过API接口而非直接数据库访问实现。
连接池优化配置在微服务环境中需要根据服务的负载特征进行精细调优。不同服务的数据访问模式差异很大,读密集型服务需要更多的读连接,写密集型服务需要优化写连接配置。GORM支持为不同的服务配置独立的连接池参数,包括最大连接数、空闲连接数、连接生命周期等,实现资源的最优分配。
分布式事务处理在微服务架构中是一个复杂的挑战。GORM可以与Seata、TCC等分布式事务框架集成,实现跨服务的数据一致性。通过事务补偿机制和最终一致性策略,在保证数据完整性的同时维持系统的高可用性。对于不需要强一致性的场景,可以采用事件驱动的异步处理模式。
// 微服务GORM配置示例
func setupUserService() *gorm.DB {
// 用户服务独立数据库配置
dsn := "user:password@tcp(user-db:3306)/userdb?charset=utf8mb4&parseTime=True"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
Logger: logger.Default.LogMode(logger.Info),
})
if err != nil {
log.Fatal("用户服务数据库连接失败:", err)
}
// 配置连接池
sqlDB, _ := db.DB()
sqlDB.SetMaxOpenConns(50) // 最大连接数
sqlDB.SetMaxIdleConns(10) // 最大空闲连接数
sqlDB.SetConnMaxLifetime(time.Hour) // 连接最大生命周期
return db
}
// 订单服务配置示例
func setupOrderService() *gorm.DB {
dsn := "order:password@tcp(order-db:3306)/orderdb?charset=utf8mb4&parseTime=True"
db, _ := gorm.Open(mysql.Open(dsn), &gorm.Config{})
// 为高并发订单服务优化连接池
sqlDB, _ := db.DB()
sqlDB.SetMaxOpenConns(100) // 更多连接支持高并发
sqlDB.SetMaxIdleConns(20)
return db
}数据库分片通过分片键路由、水平分片、垂直分片实现数据分布。GORM支持通过自定义Resolver和插件机制实现分片逻辑。读写分离通过主从数据源配置、读写操作路由、连接池隔离实现,支持负载均衡、故障转移、延迟补偿等高级特性。
分片键路由策略是分片架构的核心,通过分析查询条件中的分片键来确定目标数据库。GORM支持通过自定义Resolver和插件机制实现智能路由,能够处理复杂的分片规则和动态路由调整。分片键的选择直接影响查询性能和数据分布均匀性,需要根据业务访问模式仔细设计。
水平分片与垂直分片提供了不同的数据分布策略。水平分片将同一表的数据按行分布到多个数据库实例,适用于大数据量场景。垂直分片将不同的表或字段分布到不同的数据库,适用于业务功能明确分离的场景。GORM支持两种策略的组合使用,实现更灵活的数据架构。
分片管理与扩容包括分片的动态扩容、数据迁移、负载均衡等高级功能。GORM提供了分片状态监控和健康检查功能,及时发现分片异常并进行故障转移。支持在线分片扩容,通过数据重分布实现容量的平滑扩展。分片间的数据一致性通过分布式事务或最终一致性策略保证。
// 数据库分片配置示例
type ShardResolver struct {
shards map[string]*gorm.DB
}
func (r *ShardResolver) Route(tableName string, userID int) *gorm.DB {
// 根据用户ID进行哈希分片
shardIndex := userID % 4
shardKey := fmt.Sprintf("shard_%d", shardIndex)
return r.shards[shardKey]
}
// 初始化分片数据库
func setupSharding() *ShardResolver {
resolver := &ShardResolver{
shards: make(map[string]*gorm.DB),
}
// 配置4个分片
for i := 0; i < 4; i++ {
dsn := fmt.Sprintf("user:pass@tcp(shard%d-db:3306)/orderdb", i)
db, _ := gorm.Open(mysql.Open(dsn), &gorm.Config{})
resolver.shards[fmt.Sprintf("shard_%d", i)] = db
}
return resolver
}主从数据源配置是读写分离的基础架构,通过配置主库和多个从库实现读写流量的分离。GORM支持灵活的数据源配置,可以为不同的业务场景配置不同的主从架构。主库负责所有写操作和对一致性要求高的读操作,从库专门处理查询请求,有效分担数据库压力。
读写操作路由通过智能SQL语句分析自动判断操作类型,将读操作路由到从库,写操作路由到主库。支持事务内的读写分离,确保事务一致性的同时最大化读性能。对于复杂的查询语句,提供手动指定读写库的机制,给开发者更多控制权。
连接池隔离管理为主库和从库配置独立的连接池,实现资源的精细化管理。读写分离环境下可以为读库配置更多的连接数,为写库优化连接复用策略。这种隔离机制避免了读写操作之间的资源竞争,提高了系统的并发处理能力。
负载均衡与故障转移实现多个从库间的负载分担,支持轮询、权重、最少连接等多种负载均衡算法。动态健康检查机制监控从库状态,自动剔除故障从库并在恢复后重新加入负载均衡池。主库故障时的自动切换和恢复机制,通过心跳监控和分布式锁保证数据一致性。
延迟补偿策略通过延迟检测和补偿机制处理主从同步延迟问题。对于一致性要求较高的查询,提供强制主库读取选项。延迟监控系统实时跟踪主从延迟情况,当延迟超过阈值时自动切换到主库读取。支持基于业务规则的一致性策略配置,平衡性能和一致性需求。
// 读写分离配置示例
type ReadWriteDB struct {
master *gorm.DB // 主库
slaves []*gorm.DB // 从库集群
current int // 当前从库索引
}
func (rw *ReadWriteDB) Master() *gorm.DB {
return rw.master
}
func (rw *ReadWriteDB) Slave() *gorm.DB {
// 轮询选择从库
if len(rw.slaves) == 0 {
return rw.master // 无从库时使用主库
}
rw.current = (rw.current + 1) % len(rw.slaves)
return rw.slaves[rw.current]
}
// 初始化读写分离
func setupReadWriteSplit() *ReadWriteDB {
// 主库配置
masterDSN := "user:pass@tcp(master-db:3306)/mydb"
master, _ := gorm.Open(mysql.Open(masterDSN), &gorm.Config{})
// 从库配置
slaves := make([]*gorm.DB, 0)
for i := 1; i <= 2; i++ {
slaveDSN := fmt.Sprintf("user:pass@tcp(slave%d-db:3306)/mydb", i)
slave, _ := gorm.Open(mysql.Open(slaveDSN), &gorm.Config{})
slaves = append(slaves, slave)
}
return &ReadWriteDB{
master: master,
slaves: slaves,
}
}
