
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
Redis支持五大常见数据类型:String、Hash、List、Set、ZSet。此外还包括 Bitmap、HyperLogLog、Geo 和 Stream,这些适用于更专业的统计、地理和消息队列场景。
高级类型:
这些类型的灵活组合,使 Redis 能胜任从缓存到实时计算、从唯一性校验到地理服务等多样化需求。
Redis 的高性能不仅仅来自于内存存储,更源于其底层数据结构的精心设计与动态切换:
Redis 会根据数据量和内容动态切换底层结构,实现空间与性能的最佳平衡。例如,Hash/Set/ZSet 在元素少时用 ziplist/intset,数据增多时自动升级为 hashtable/skiplist。这种"多态编码"策略,是 Redis 能兼顾极致性能与低内存消耗的关键。
在 Redis 中,SET 命令的行为不仅仅是"赋新值",更是一次彻底的 key 重建。每当你对已存在的 key 执行 SET 操作时,Redis 会直接覆盖原有数据,并且清除该 key 的过期时间(TTL),即使之前设置过 EXPIRE 或 PEXPIRE。这样做的好处是保证数据一致性,防止因过期策略遗留导致的逻辑混乱。
这点在实际开发中尤为重要,尤其是缓存更新、分布式锁等场景。如果你希望更新值的同时保留原有 TTL,应该使用 SETEX 或 SET key value EX time 这类带过期参数的命令。否则,频繁的 SET 操作可能导致缓存永不过期,进而引发内存泄漏等问题。
此外,SET 操作还会触发 Redis 的键空间通知(keyspace notifications),如果配置了相关事件监听,客户端会收到 key 被修改的通知。这种机制常用于实现缓存同步、数据一致性校验等高级功能。
Redis 的 String 类型本质上是 SDS(Simple Dynamic String),即使你存储的是浮点数,也会先将其转换为字符串再存储。例如,SET key 3.14 实际存储的是 "3.14" 这个字符串。Redis 并不关心你存的是 int、float 还是其他类型,只有在执行如 INCRBYFLOAT 这类命令时,才会将字符串解析为浮点数进行运算。
这种设计带来了极大的灵活性和兼容性,使得 String 类型可以存储任意二进制数据。但也意味着,所有数值操作都需要通过专用命令实现,不能直接对存储内容做数学运算。
浮点数的存储和计算在 Redis 中需要特别注意精度问题。由于底层是字符串,浮点运算可能受到 IEEE 754 标准限制,在涉及金融、科学计算等场景时,应谨慎处理精度误差。
Redis 对 String 类型的最大长度做了严格限制——单个 String 最大为 512MB。这个限制是出于性能和资源保护的考虑:如果允许超大 key 存储,单次读写会极大消耗内存和带宽,甚至拖垮整个 Redis 实例。
在实际应用中,建议单个 key 的内容控制在几十 KB 以内,超过 1MB 就要警惕设计是否合理。大 key 不仅影响性能,还会导致主从同步、AOF 重写等操作变慢,甚至引发阻塞和数据丢失风险。
大 key 的常见问题包括:
因此,在设计缓存结构时,应尽量避免大 key,必要时可通过分片、压缩等方式优化存储。
Redis 的 String 类型底层是 RedisObject,根据内容和长度采用三种编码:
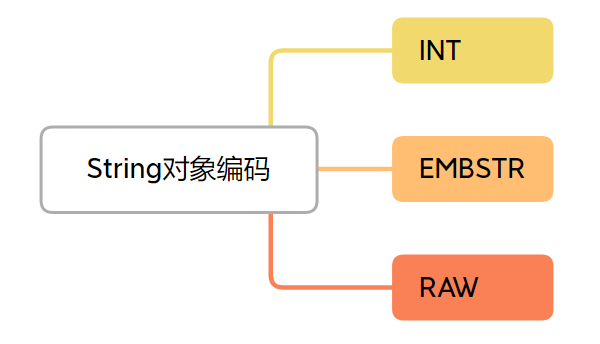
EMBSTR 的设计极大优化了小字符串的存储和访问效率,是 Redis 性能优化的典范。理解这些编码方式有助于我们在设计缓存结构时做出更优选择。
SDS 结构不仅支持 O(1) 获取长度,还具备预分配和惰性缩容机制,避免了频繁的内存重分配,提升了性能。此外,SDS 的二进制安全特性,使其能存储任意字节序列,不会被 '\0' 截断,适合存储图片、压缩数据等二进制内容。
EMBSTR 的阈值(44 字节)是根据内存分配器 jemalloc 的 64 字节对齐策略精确计算的。RedisObject 结构体占用 16 字节,SDS 管理部分占 3 字节,加上字符串结尾的 '\0',剩余空间正好 44 字节。这样可以保证 RedisObject 和 SDS 一次性分配在同一内存块中,提升内存分配和释放效率,减少碎片。
这种精细的内存管理体现了 Redis 对性能的极致追求,也说明底层实现细节对整体性能有着直接影响。EMBSTR 的设计不仅节省了内存,还提升了缓存命中率,因为小字符串在内存中更紧凑,更容易被 CPU 缓存命中。
Redis 3.2 之前,EMBSTR 阈值为 39 字节,原因在于 SDS 结构体更大。3.2 版本后引入了 sdshdr8,结构更紧凑,节省了 5 字节空间,使 EMBSTR 阈值提升到 44 字节。这一变化不仅提升了小字符串的存储效率,也反映了 Redis 持续优化内存结构、追求极致性能的工程理念。
SDS 结构的演进是 Redis 性能优化的重要案例。通过减少冗余字段、优化内存布局,Redis 在保持功能不变的前提下,显著提升了内存利用率和访问效率。这种对细节的极致追求,是 Redis 高性能的关键因素之一。
SDS(Simple Dynamic String)是 Redis 对 C 字符串的升级版,解决了 C 字符串长度获取慢、扩容低效、二进制不安全等问题。SDS 结构中包含长度、分配空间等元数据,支持 O(1) 获取长度和高效扩容,避免了频繁 realloc 带来的性能损耗。
SDS 还支持二进制安全,能存储任意字节序列(如图片、压缩数据),不会被 '\0' 截断。其预分配和惰性缩容机制,进一步提升了内存利用率和操作效率,是 Redis 高性能的基础之一。
SDS 的设计充分体现了 Redis 对性能的极致追求。通过预分配策略,SDS 减少了内存重分配的次数,提升了字符串操作的效率。惰性缩容机制则避免了频繁的内存释放,进一步优化了性能。
Redis 的 List 类型本质是双端队列(Deque),支持 LPUSH/RPUSH 和 LPOP/RPOP 操作,既能实现先进先出(队列),也能实现后进先出(栈)。这种灵活性使 List 能胜任消息队列、任务调度、历史记录等多种场景。
开发中常见的用法有:RPUSH + LPOP 实现队列,LPUSH + LPOP 实现栈。理解 List 的双端特性,有助于根据业务需求灵活选择数据结构和命令组合。
List 的双端特性使其在实现消息队列时非常灵活。例如,可以使用 RPUSH 将消息推入队列,LPOP 从队列头部取出消息,实现标准的 FIFO 队列。也可以使用 LPUSH 将消息推入队列头部,LPOP 取出最新消息,实现 LIFO 栈。
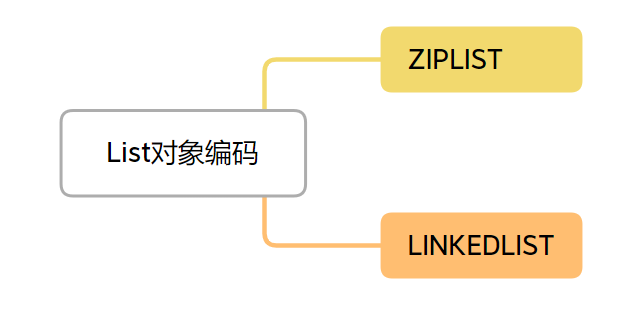
Redis 中的 List 类型底层编码经历了多个阶段的演进,随着版本的更新,底层实现不断优化,以提高空间利用率和访问效率。
在早期版本(3.2 前),Redis 使用了两种数据结构来支持 List 类型:当数据量较小时,采用 ziplist 作为底层存储,它通过紧凑的内存布局节省了空间,适合小规模数据;而当数据量增大时,Redis 则切换到 linkedlist(链表)结构,虽然链表在操作上非常灵活,但它的内存占用较大,且性能会随着数据量增加而下降。
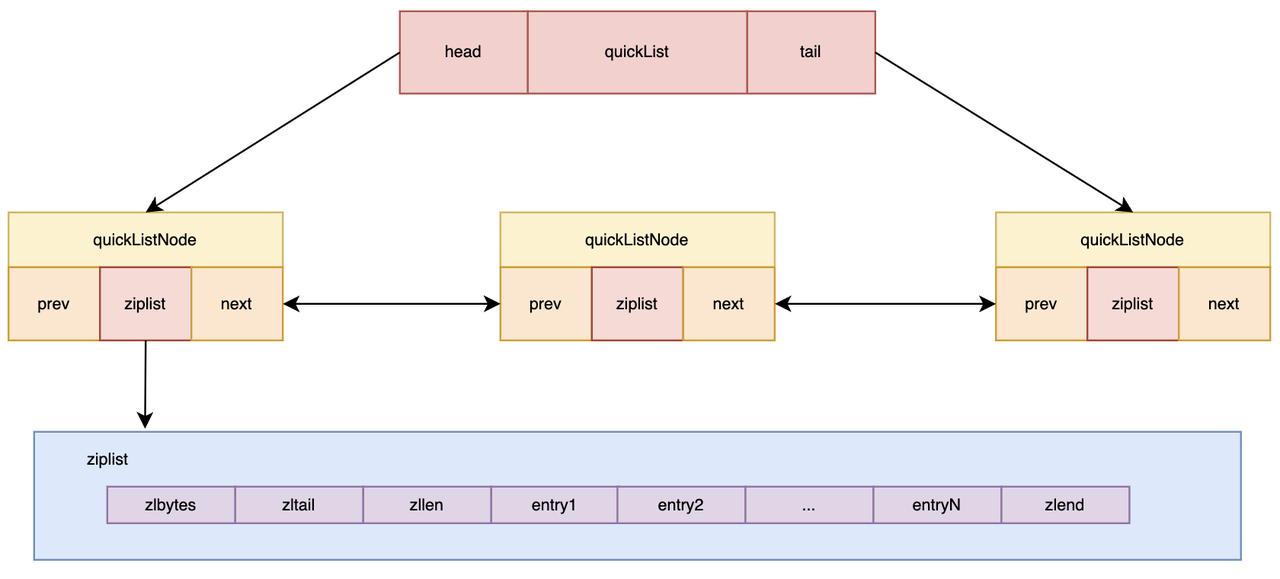
从 3.2 版本开始,Redis 统一采用了 quicklist 作为 List 类型的底层实现。quicklist 将链表和压缩列表结合起来,它通过压缩列表的紧凑性减少了内存占用,同时又能利用链表的灵活性来提升访问效率。通过这种方式,Redis 实现了空间和性能的平衡,适应了不同规模数据的需求。
而在 7.0 版本及之后,Redis 将 ziplist 进一步替换为 listpack。listpack 是一种新的紧凑型数据结构,专为优化内存使用和提升访问性能而设计。它在保证高效查询和访问速度的同时,比 ziplist 更加节省内存,因此成为了 List 类型的理想底层结构。
这些演进不仅提升了 Redis 对 List 类型操作的效率,也优化了它在不同数据规模下的内存表现。随着 Redis 不断迭代,底层编码的优化使得 List 类型能在处理大规模数据时,依然保持高效且低成本的性能。
Ziplist(压缩列表)通过将所有元素紧凑存储在一块连续内存中,极大减少了指针和内存碎片开销。每个 entry 记录前一个元素的长度(prevlen)、自身编码方式(encoding)和实际数据(data),支持高效的正反向遍历。
我们先看一下ZIPLIST,虽然已经有LISTPACK,但实际面试中聊得比较多的,还是ZIPLIST。
Redis代码注释中,非常清晰描述了ZIPLIST的结构:
* The general layout of the ziplist is as follows:
*
* <zlbytes> <zltail> <zllen> <entry> <entry> .. <entry> <zlend>比如这就是有3个节点的ziplist结构:

zlbytes:表示该ZIPLIST一共占了多少字节数,这个数字是包含zlbytes本身占据的字节的。
zltail:ZIPLIST 尾巴节点 相对于 ZIPLIST 的开头(起始指针),偏移的字节数。通过这个字段可以快速定位到尾部节点,例如现在有一个 ZIPLIST,zl 指向它的开头,如果要获取 tail 尾巴节点,即 ZIPLIST 里的最后一个节点,可以 zl + zltail的值,这样定位到它。如果没有尾节点,就定位到 zlend
zllen:表示有多少个数据节点,在本例中就有3个节点。
entry1~entry3:表示压缩列表数据节点。
zlend:一个特殊的entry节点,表示ZIPLIST的结束。这种结构适合存储小对象、短列表,能显著提升缓存命中率和内存利用率。但当元素数量或单个元素变大时,ziplist 会自动升级为更高效的数据结构(如 quicklist、hashtable),以保证性能和可扩展性。
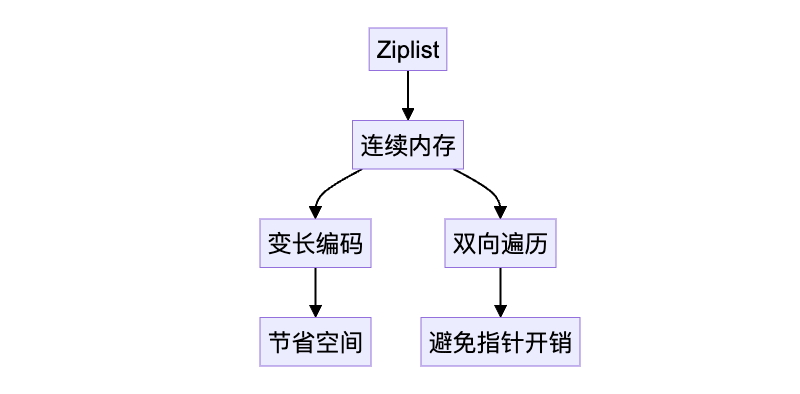
总的来说,Ziplist 的高效性在于其精妙的内存管理和数据编码方式。首先,Ziplist 采用变长编码来存储每个元素的长度,这样就能根据数据的实际大小灵活地分配空间,从而避免了浪费。这种方式显著降低了内存占用,尤其适用于存储小数据量的场景。
其次,Ziplist 通过将所有数据存储在连续的内存块中,有效减少了内存碎片的产生。连续内存的分配不仅优化了内存利用率,还使得数据访问更加高效,进一步提升了整体性能。这种连续存储的方式让 Redis 在进行频繁的读写操作时能够保持较低的内存访问延迟。
最后,Ziplist 的设计中通过 prevlen 字段实现了双向遍历功能,这意味着可以从任意一个元素开始,快速地反向遍历列表。这种方法避免了传统链表结构中需要额外指针的开销,节省了内存并提高了操作效率。
综上所述,Ziplist 的这些设计使得它在处理小规模数据时既高效又节省内存,是 Redis 内存优化中的一个典范。
这种设计使 ziplist 在存储小数据时非常高效,是 Redis 内存优化的典范。
ZIPLIST每个 entry 都记录了前一个节点的长度,通过指针减操作可以找到上一个节点的位置,实现反向遍历。
展开来说,尽管ziplist采用的是线性内存布局,但 ziplist 并不是单向链表那么“死板”。之所以能从后往前遍历,关键在于每个 entry 的结构中都包含一个字段 prevlen —— 它记录了前一个 entry 的字节长度。正是这个字段,使得 ziplist 可以在没有显式双向指针的情况下实现“向后跳跃”。
* The general layout of the ziplist is as follows:
*
* <zlbytes> <zltail> <zllen> <entry> <entry> .. <entry> <zlend>当你位于某个节点时,只需读取 prevlen,再将当前指针向前移动相应字节数,即可准确跳转至上一个节点。整个过程无需解析完整结构,也不依赖链表指针,因此非常高效。相比传统链表(每个节点需要两个指针字段),ziplist 的这种实现方式显著降低了内存开销,尤其适用于小对象场景。
但需要注意的是,虽然支持双向遍历,ziplist 的插入删除代价较高,尤其在中间插入或删除元素时需要整体内存搬移,因此在数据规模大或频繁变更场景下并不适用,会自动升级为 quicklist。整体来看,ziplist 是一种巧妙结合压缩与可遍历能力的精巧设计,体现了 Redis 对存储效率与功能性的平衡追求。

ziplist 是 Redis 为节省内存而设计的一种顺序存储结构,其头部(header)中包含一个字段 zllen,用来记录当前 ziplist 包含的 entry 数量。该字段占用 2 个字节,最大能记录 65535(即 2^16-1)个节点数。这意味着,在节点数在该范围内时,Redis 查询节点总数可以直接返回,不需遍历,时间复杂度是 O(1)。
但是,如果 ziplist 中的 entry 超过了这个上限,zllen 会被标记为一个特殊值 0xFFFF,此时 Redis 就会退化为逐个遍历 entry 来统计实际数量,复杂度为 O(n)。当然在实际业务中很少出现这种情况,因为 Redis 对 ziplist 的使用有自动切换机制 —— 一旦数据过多,它就会自动升级为更强大的结构(如 quicklist),避免退化性能。
所以这道题的核心不是算法,而是对 Redis 存储设计的理解:它并不追求绝对最优,而是在资源和性能之间做折中。 通过设定阈值优化大多数场景,个别退化时也能接受,是 Redis 高效背后的常见设计哲学。
在 Redis 早期的 List 实现中,linkedlist 是基础结构。其内部封装的是一个双向链表,每个节点都由 listNode 表示,整体链表由 list 结构体管理。而在 list 结构体中,专门定义了一个 len 字段,用于记录当前链表包含的节点数。这意味着,Redis 无需遍历链表,只需读取该字段即可得知元素总数,时间复杂度是 O(1)。
这一设计充分体现了 Redis 对高频操作做缓存优化的思路 —— 既然“查询元素个数”是常见需求,那就直接在元数据中维护一份常驻计数,这比每次遍历来得更高效、可靠。当然,这也带来了内存占用的小幅增加,因为结构体中需为 len 分配额外字段;但对于 Redis 这类强调性能的内存数据库来说,这种“以空间换时间”的权衡是完全值得的。
由于 linkedlist 自身结构较重(每个节点含两个指针、一个值指针),所以在实际应用中,当数据量少时会显得臃肿,反而不如 ziplist 紧凑,这就是为什么后来 Redis 引入 quicklist 对其做了压缩优化。
Redis 的 Set 类型是“无序集合”,底层结构的选择主要依据元素类型和数量,以实现空间和性能的折中。具体来说:
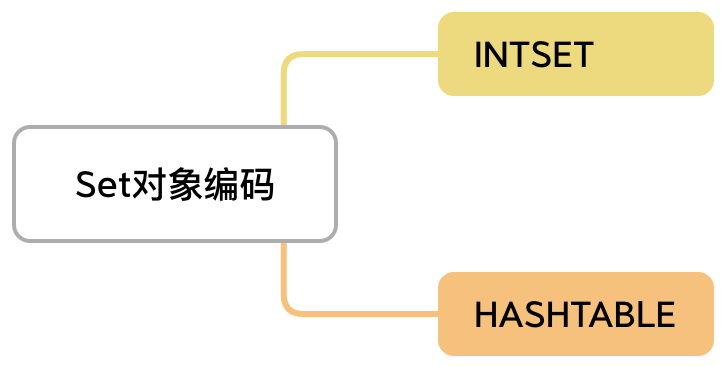
Redis 的策略是:当集合元素全是整数,且数量 ≤512(该值可配置)时,使用 intset;否则切换为 hashtable。切换是不可逆的 —— 即一旦某个元素导致结构升级为 hashtable,就不能退回 intset,即使后续删除了该元素。
这种多编码策略体现了 Redis 的核心思想:适应数据特性,动态优化底层结构。在业务设计中,如果确定 Set 是轻量整数集合,可以利用 intset 带来的极致内存效率;反之,应尽早准备好升级为 hashtable 的内存预算。
这是一个容易误导人的问题,很多面试者会误以为 Set 是有序的,因为它底层可能采用有序的数组结构,如 intset。然而,Redis 中的 Set 本质上是无序集合,即使底层使用了有序数组,也并不意味着其在 Redis 操作层面具有顺序性。
然而,Redis 的 Set 并不保证元素的顺序。因此,如果业务中对顺序有要求,应该选择使用 ZSet(有序集合),它会根据元素的 score 来自动排序。
Redis 在设计 Set 时,采用了 两种编码方式,分别是 intset 和 hashtable。这种多编码的设计使得 Redis 在面对不同规模和数据类型的集合时,能够在空间和性能之间做出合理的折中:
这种设计思想是 Redis 性能优化的一部分:根据数据特性选择合适的存储结构。intset 节省空间,而 hashtable 则更灵活且适用于更广泛的场景。
Redis 中的 Hash 类型是一个键值对集合,通常用于存储对象数据,如用户信息、配置项等。为了兼顾空间和性能,Hash 在不同的数据规模下会使用两种编码方式:
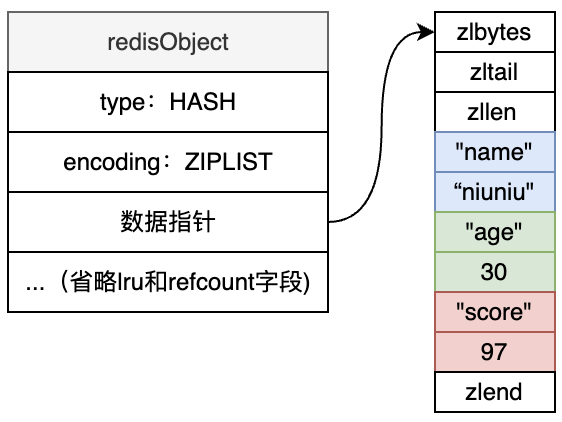
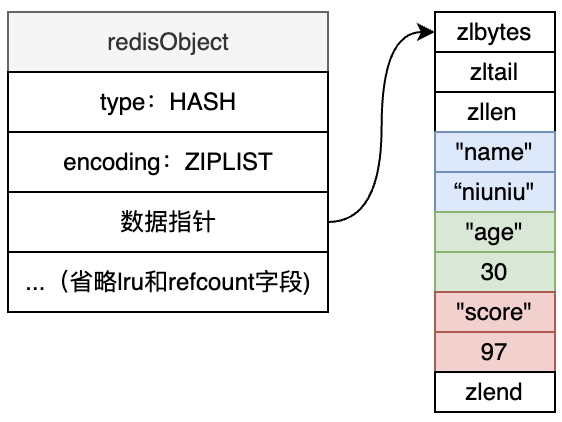
这种升级机制能让 Redis 在处理小数据时节省空间,在处理大数据时保证性能,体现了 Redis 的高效存储策略。
HASHTABLE在无序集合Set中也有应用,和Set的区别在于,在Set中value始终为NULL,但是在Hash中,是有对应的值的。
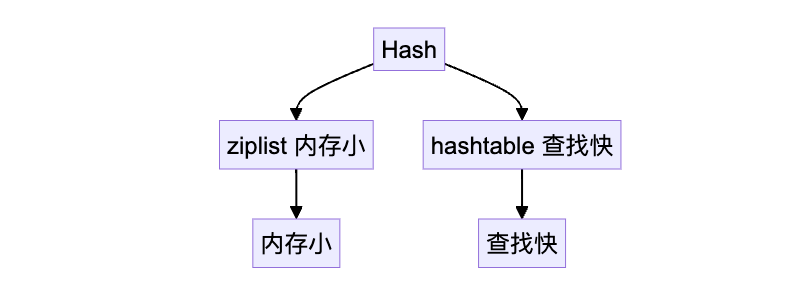
Redis 的 Hash 类型根据数据大小采用不同的编码方式,导致其查找某个 key 的时间复杂度也会有所不同:
因此,实际使用中,如果你有大量字段需要存储,建议调整参数,使 Hash 尽早从 ziplist 升级为 hashtable,以避免性能瓶颈。
在 Redis 中,Hash 类型的底层实现是哈希表,其中包含两个主要属性:
当我们查询哈希表中元素的总数时,Redis 直接返回 used 字段,而不需要遍历所有桶和元素。因此,查找元素总数的时间复杂度是 O(1),这是哈希表数据结构的天然优势。
这也是 Redis 底层设计的一个特点 —— 在保证性能的前提下,尽可能优化查询操作的效率。
Redis 使用 哈希表(Hashtable) 来存储大部分的字典类型数据。每个 key 对应的存储位置是由哈希函数计算得出的。具体来说:
// dict.h
##define dictHashKey(d, key) (d)->type->hashFunction(key)
// server.c 中字符串键的哈希函数
uint64_t dictSdsHash(const void *key) {
return dictGenHashFunction((unsigned char*)key, sdslen((char*)key));
}
// 默认哈希函数(Redis 5.0 使用 siphash)
uint64_t dictGenHashFunction(const void *key, int len) {
return siphash(key, len, dict_hash_function_seed);
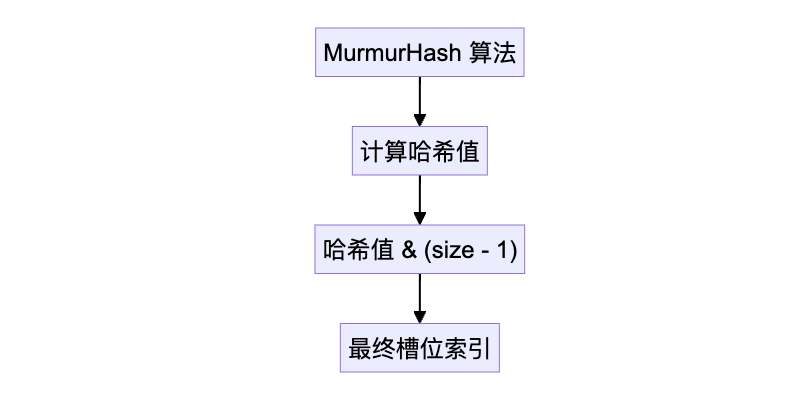
}size - 1)进行位与(&)运算。这个技巧依赖于哈希表的大小是 2 的幂次方,因此可以通过位运算来加速定位过程。这一操作将哈希值“映射”到哈希表中的某个槽位上。使用掩码操作而非求模运算,是为了提升计算效率。因为哈希表的容量一般是 2 的幂,而在计算机中,使用位运算(&)替代除法运算能够大幅提高性能。参考如下源码:// dict.c
dictEntry *dictAddRaw(dict *d, void *key) {
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 如果正在 rehash,执行一步
// 计算 key 的哈希值并获取槽位
if ((index = _dictKeyIndex(d, key)) == -1) // 计算索引
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; // 选择哈希表
entry = zmalloc(sizeof(*entry)); // 分配新 entry
entry->next = ht->table[index]; // 新 entry 指向链表头部
ht->table[index] = entry; // 将新 entry 置为链表头
ht->used++;
dictSetKey(d, entry, key); // 设置键
return entry;
}
// 计算键的槽位索引
static int _dictKeyIndex(dict *d, const void *key) {
unsigned int h, idx, table;
dictEntry *he;
if (_dictExpandIfNeeded(d) == DICT_ERR) return -1; // 必要时扩容
// 计算哈希值
h = dictHashKey(d, key);
// 在两个哈希表中查找(处理 rehash 场景)
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask; // 哈希值 & sizemask 得到槽位
he = d->ht[table].table[idx];
// 检查是否已存在相同 key
while (he) {
if (dictCompareKeys(d, key, he->key))
return -1; // key 已存在
he = he->next;
}
if (!dictIsRehashing(d)) break; // 未在 rehash 则无需检查第二个表
}
return idx; // 返回槽位索引
}综上,Redis 的哈希表能够通过哈希函数和掩码运算高效地定位存储位置,确保数据能够快速插入、查找和删除。
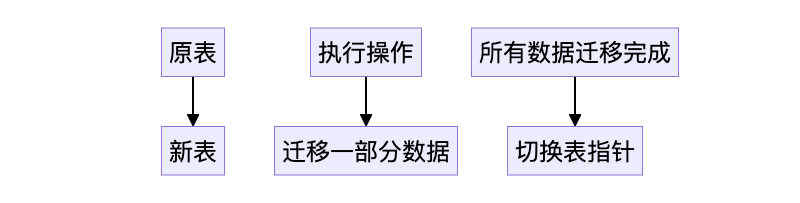
哈希表在 Redis 中是动态扩展的。当数据量逐渐增大,哈希表会出现负载因子过高的问题(即槽位过于拥挤,哈希冲突频繁)。为了解决这个问题,Redis 使用渐进式 rehash来扩容哈希表,而不是一次性扩容,这样能避免在扩容时造成系统阻塞。
具体的扩容步骤如下:
渐进式 rehash 的优点在于它不会因为扩容而阻塞主线程,也不会造成性能剧烈波动。通过这种方式,Redis 可以平滑地扩展哈希表,并保持高性能。
为了帮助大家更好理解,我们再扩展一些细节:
其实为了实现渐进式扩容,Redis中没有直接把dictht暴露给上层,而是再封装了一层:
// from Redis 5.0.5
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;可以看到dict结构里面,包含了2个dictht结构,也就是2个HASHTABLE结构。dictEntry是链表结构,也就是用拉链法解决Hash冲突,用的是头插法
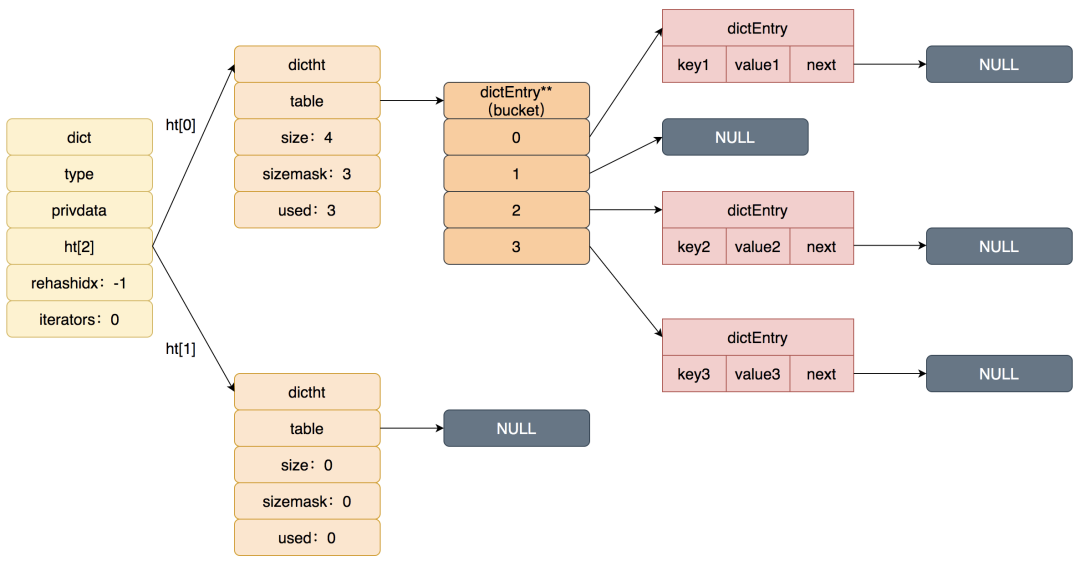
实际上平常使用的就是一个HASHTABLE,在触发扩容之后,就会两个HASHTABLE同时使用,详细过程是这样的:
当向字典添加元素时,发现需要扩容就会进行Rehash。Rehash的流程大概分成三步:
首先,为新Hash表ht[1]分配空间。新表大小为第一个大于等于原表2倍used的2次方幂。举个例子,原表如果used=500,2倍就是1000,那第一个大于1000的2次方幂则为1024。此时字典同时持有ht[0]和ht[1]两个哈希表。字典的偏移索引从静默状态-1,设置为0,表示Rehash工作正式开始。

然后,迁移ht[0]数据到ht[1]。在Rehash进行期间,每次对字典执行增删查改操作,程序会顺带迁移当前rehashidx在ht[0]上的对应的数据,并更新偏移索引。与此同时,部分情况周期函数也会进行迁移,详情见评论。这里有同学提出了一个疑问,如果rehashidx刚好在一个已删除的空位置上,是直接返回,还是尝试往下找。我们直接看dictRehash函数的片段代码:
// int empty_visits = n*10; /* Max number of empty buckets to visit. */
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}可以看到,会继续往下找,但是有个上限n*10,最多这么多次,n其实是传进来的参数,调用时候如下所示,实际是1,则最多往后找10个,防止因为连续碰到空位置导致主线程操作被阻塞。
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被Rehash至ht[1],此时再将ht[1]和ht[0]指针对象互换,同时把偏移索引的值设为-1,表示Rehash操作已完成。这个事情也是在Rehash函数做的,每次迁移完一个元素,会检查下是否完成了整个迁移:
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}总结一下,渐进式扩容的核心就是操作时顺带迁移。
尽管扩容是哈希表常见的操作,但 Redis 在一定情况下也会触发 缩容 操作,即当哈希表的负载因子过低时,Redis 会将哈希表的大小缩小。缩容的触发条件主要是负载因子过低,例如 used 元素数远小于哈希表容量时,Redis 就会考虑缩容。
与扩容类似,缩容同样采用渐进式 rehash,通过以下步骤来完成:
used 数量的最小 2 次幂。需要注意的是,缩容操作在 Redis 中较少触发,因为哈希表的扩容是更常见的行为。缩容通常发生在哈希表负载较低时(例如,当大量数据被删除时)。
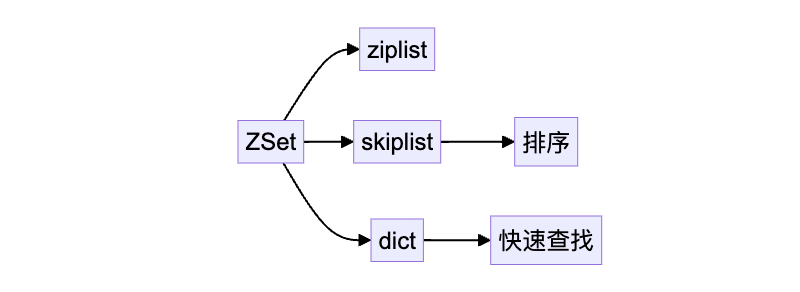
Redis 的 ZSet(有序集合)是一个支持按分值排序的集合类型,常用于实现排行榜、区间查询等功能。为了适应不同数据规模,Redis 为 ZSet 提供了两种编码方式:

SKIPLIST是一种可以快速查找的多级链表结构,通过SKIPLIST可以快速定位到数据所在。它的排名操作、范围查询性能都很高
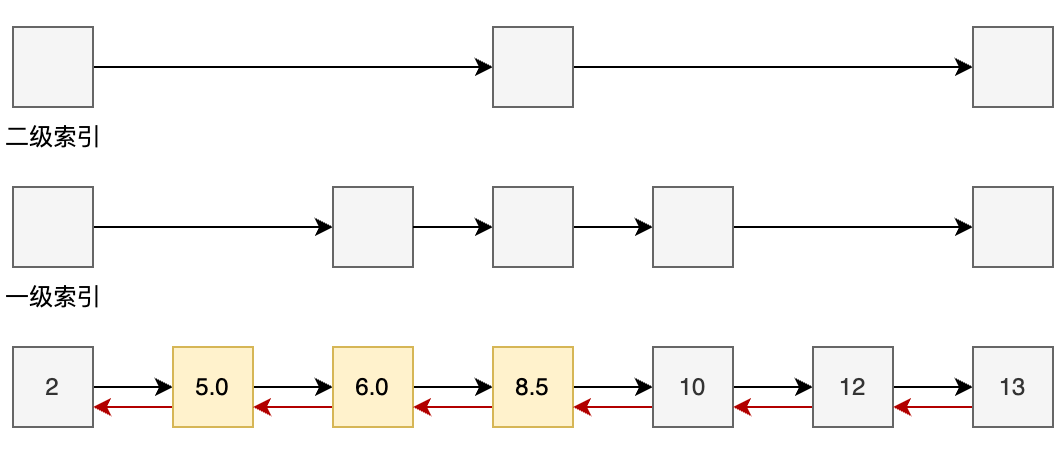
字典其实就是HashTable,这样可以在O(1)时间复杂度查到成员的分数值。
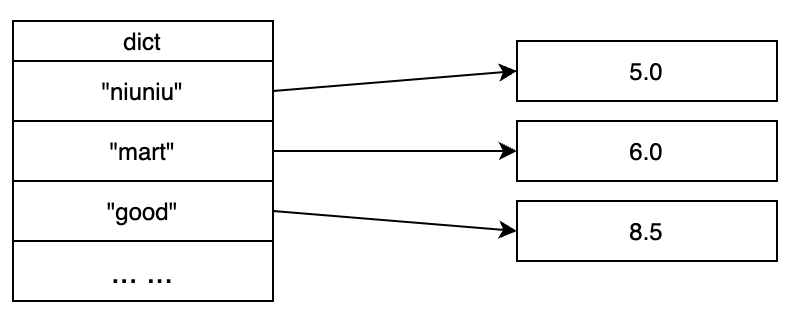
Redis 的这种编码方式为 ZSet 提供了很好的内存优化和查询性能。对于小规模的有序数据,ziplist 高效且节省空间,而对于大规模数据,skiplist + dict 提供了更高效的查询和排序能力。
跳表(skiplist)是一种高效的排序数据结构,它通过多级索引提供 O(logN) 的查找时间复杂度。跳表的头结点中有一个 length 字段,表示当前跳表中元素的总数。因此,查询跳表的节点总数是一个常数时间操作(O(1)),不需要遍历整个结构。
这一设计方式与哈希表类似,都是通过维护元数据来加速常见的查询操作。跳表的 length 字段提供了快速访问的能力,使得查询节点数量时不必遍历所有节点,从而保持高效。
回答
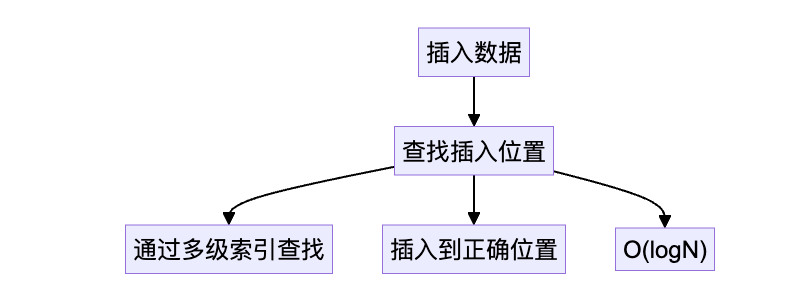
先说结论是 O(logN)。跳表结构提供多级索引,查找插入点后再调整指针,整体为对数级复杂度。
在插入新数据时,跳表首先根据目标值的大小决定其在每层的插入位置。插入操作从顶部的索引层开始,逐级向下进行,最终定位到合适的插入点。这种查找插入的过程大致类似二分查找,通过分层索引实现对数级的查找效率。
跳表的优点在于它提供了有序性的支持,并且保持了平衡性,保证了对数级别的查询和插入效率。这使得跳表成为高效实现有序集合(如 Redis 中的 ZSet)的理想选择。
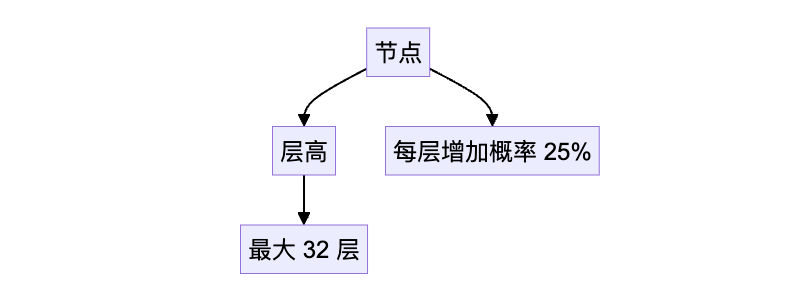
跳表是一种随机化的数据结构,通过概率机制实现平衡。跳表的每个节点都有一个与之相关联的层高,这个层高是随机决定的。
通过这种概率控制机制,跳表能够在保证查询和插入效率的同时,避免结构的过度膨胀。相比于红黑树等平衡树,跳表结构简单,易于实现,且提供了很好的查询性能。跳表的这一特性使得它在实现如 Redis 中的 ZSet 时表现出色。
先说结论,为了同时满足“快速查找”和“有序遍历”的需求。跳表按分值排序,字典按成员查找,两者互补。
在 Redis 中,ZSet(有序集合)是通过 跳表(skiplist) 和 哈希表(hashtable) 的组合实现的。跳表负责维护集合元素的顺序,而哈希表则提供了快速查找的能力。这两者的结合使得 Redis 能够高效地处理有序集合的各类操作,既能支持有序查询,又能满足快速定位。
跳表是 ZSet 的核心数据结构之一,专门用于维护集合中元素的顺序。它通过多层索引提升查找效率,使得在进行范围查询、排序或分页等操作时,能够保持 O(logN) 的查询复杂度。由于其层次化结构,跳表能够提供高效的有序查询,并能轻松应对大规模数据的排序需求。
而哈希表在 ZSet 中则用于存储元素的实际值和成员,通过哈希算法提供 O(1) 的查找速度。每个成员的分值在跳表中有对应的排序位置,而哈希表则使得我们能够高效地查找成员的值 。通过这种设计,Redis 将元素的分值和成员值分开存储,既保留了有序性,又保证了查询性能。
这两种数据结构的结合,使得 ZSet 既能快速定位某个成员,也能够高效地查询某个分值范围内的成员。例如,如果你想查询一个成员的排名,可以通过哈希表直接定位该成员;而如果你需要获取某个分值范围内的所有成员,跳表则能通过高效的范围扫描来完成。
这种结构设计思路,正是 Redis 在高性能场景下处理有序集合的核心优势之一,它能够在保证有序性的同时,提供极高的查询效率。
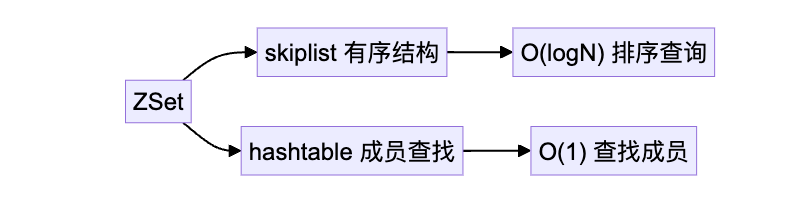
跳表结构简单、内存占用小、范围查询性能高、维护代价低,适合 Redis 的高性能定位。
跳表和红黑树(平衡树)都属于有序数据结构,它们在查找、插入和删除操作上具有相似的时间复杂度,通常为 O(logN)。然而,在 Redis 的实现中,跳表被优先选择,而非传统的红黑树。这一决策背后有多方面的考虑,首先是跳表的实现比红黑树要简单得多。跳表通过引入多级随机索引来平衡节点,这种方法避免了平衡树中需要频繁进行旋转和调整的复杂操作。相比之下,红黑树的平衡维护较为复杂,涉及多个指针操作和节点的颜色标记,这些都会增加实现的复杂性。
从内存效率角度来看,跳表的节点通常仅包含数据值和指向下一层节点的指针,这使得跳表的内存开销显著小于红黑树。红黑树的每个节点除了存储数据外,还需要存储额外的父指针、颜色标记等,这会导致额外的内存占用。因此,跳表在内存使用上更为节省,尤其是在存储大量数据时,其优势更加明显。
跳表在处理范围查询时表现尤为出色。对于 Redis 中的 ZSet 数据类型,范围查询如 ZRANGEBYSCORE 等是常见的操作,而跳表通过其层次化的结构,可以高效地进行这种类型的查询。与之相比,红黑树在执行范围查询时往往需要执行多次旋转,导致查询效率较低。跳表的设计避免了这些繁琐的操作,从而提高了查询速度。
此外,跳表的插入和删除操作相比红黑树更加简单。跳表无需像平衡树那样严格维护树的平衡,这使得跳表的维护成本低很多,尤其适用于 Redis 的单线程模型。在这个模型中,避免了多余的计算和资源消耗,保证了系统的高效性和响应速度。
综合来看,跳表的内存占用小、实现简单、查询效率高以及维护成本低等特点,使其成为 Redis 在实现 ZSet 时的理想选择,尤其在高性能的需求下,跳表能够提供更好的支持。

