
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
Redis 单机模式虽性能出色,但在生产环境中存在明显短板,主要体现在三个方面:
**可用性方面,单机模式面临单点故障风险,一旦服务器出现问题,整个服务便会不可用,且无法实现故障的自动转移,系统可用性完全依赖这一台机器。
容量方面,单机的内存容量有限,无法对数据进行分片处理,这使得系统的扩展性受到极大限制,难以应对数据量持续增长的场景。
性能方面,单机的处理能力存在上限,不能实现读写分离,在高并发场景下,性能瓶颈会十分明显。
我们可以通过一个具体操作来感受单机模式的容量局限:
// 模拟单机Redis的写入压力
redis-cli -h 127.0.0.1 -p 6379
> SET key1 "value1"
> SET key2 "value2"
> SET key3 "value3"
...
// 当写入量达到内存上限时
> SET key1000000 "value1000000"
(error) OOM command not allowed when used memory > 'maxmemory'Redis 主从模式是一种数据复制机制,它通过将一台 Redis 服务器(主节点)的数据复制到其他 Redis 服务器(从节点),从而实现数据的冗余备份和读写分离。
这种模式的核心优势显著:
在高可用性上,当主节点发生故障时,可以切换到从节点继续提供服务,能够实现故障自动转移,大幅提高了系统的整体可用性。
在读写分离上,主节点专门负责处理写操作,从节点则承担读操作,这种分工有效提高了系统的整体吞吐量。
在数据备份上,从节点保存着主节点的数据副本,实现了数据的冗余存储,进一步提高了数据的安全性。
以下架构图能直观展示主从模式的工作方式:
下面通过具体实验来演示主从模式的配置和使用:
// 创建三个Redis配置文件
mkdir redis-master-slave
cd redis-master-slave
// 主节点配置
cat > redis-master.conf << EOF
port 6379
daemonize yes
pidfile /var/run/redis-master.pid
logfile "redis-master.log"
dbfilename "dump-master.rdb"
EOF
// 从节点1配置
cat > redis-slave1.conf << EOF
port 6380
daemonize yes
pidfile /var/run/redis-slave1.pid
logfile "redis-slave1.log"
dbfilename "dump-slave1.rdb"
slaveof 127.0.0.1 6379
EOF
// 从节点2配置
cat > redis-slave2.conf << EOF
port 6381
daemonize yes
pidfile /var/run/redis-slave2.pid
logfile "redis-slave2.log"
dbfilename "dump-slave2.rdb"
slaveof 127.0.0.1 6379
EOF启动服务:
// 启动主节点
redis-server redis-master.conf
// 启动从节点
redis-server redis-slave1.conf
redis-server redis-slave2.conf测试数据同步:
// 在主节点写入数据
redis-cli -p 6379
> SET key1 "value1"
> SET key2 "value2"
// 在从节点读取数据
redis-cli -p 6380
> GET key1
"value1"
> GET key2
"value2"哨兵(Sentinel) 是Redis官方提供的高可用解决方案,由一组(通常3个及以上)哨兵进程组成,用于监控Redis主从集群的运行状态,并在主节点故障时自动将从节点晋升为新主节点,实现故障的自动转移。
简单来说,哨兵就像Redis集群的"监控与运维团队",持续关注主从节点的健康状态,一旦主节点宕机,立刻启动"应急预案",无需人工干预即可恢复集群可用性。
主从模式虽能实现数据备份和读写分离,但存在明显短板,而哨兵正是为解决这些问题而生:
| 主从模式的痛点 | 哨兵的解决方案 |
|---|---|
| 主节点故障后需手动切换 | 自动检测主节点故障,自动将从节点晋升为新主节点 |
| 无法实时监控节点状态 | 持续监控主、从节点及其他哨兵的健康状态 |
| 故障转移后需手动更新客户端配置 | 自动通知客户端新主节点的地址,无需修改客户端代码 |
| 单哨兵存在单点风险 | 多哨兵协同工作,少数服从多数原则避免单点故障 |
具体来说,哨兵的核心功能包括:
哨兵配置需基于已有的Redis主从集群,步骤可分为"准备主从环境"、"配置哨兵节点"、"启动与验证"三部分,以下是详细流程:
假设已搭建简单主从集群(1主2从),配置如下:
slaveof 127.0.0.1 6379slaveof 127.0.0.1 6379(主从配置可参考前文"主从模式实验",确保数据同步正常)
推荐部署3个哨兵节点(提高容错性),分别使用26379、26380、26381端口,配置文件如下:
## 哨兵1 配置
port 26379
daemonize yes
pidfile /var/run/redis-sentinel1.pid
logfile "sentinel1.log"
// 监控主节点:名称(自定义)、主节点地址、端口、投票阈值(至少n个哨兵认为主节点故障才触发转移)
sentinel monitor mymaster 127.0.0.1 6379 2
// 判定主节点为"主观下线"的超时时间(毫秒)
sentinel down-after-milliseconds mymaster 30000
// 故障转移时,最多有1个从节点同时对新主节点进行同步
sentinel parallel-syncs mymaster 1
// 故障转移超时时间(毫秒)
sentinel failover-timeout mymaster 180000
## 哨兵2配置
port 26380
daemonize yes
pidfile /var/run/redis-sentinel2.pid
logfile "sentinel2.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
## 哨兵3配置
port 26381
daemonize yes
pidfile /var/run/redis-sentinel3.pid
logfile "sentinel3.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000redis-sentinel sentinel1.conf
redis-sentinel sentinel2.conf
redis-sentinel sentinel3.confredis-cli -p 26379
> info sentinel
// 输出示例(显示监控的主节点、从节点数量、哨兵数量等)
// Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3也就是说,客观下线触发,才会开始故障转移。
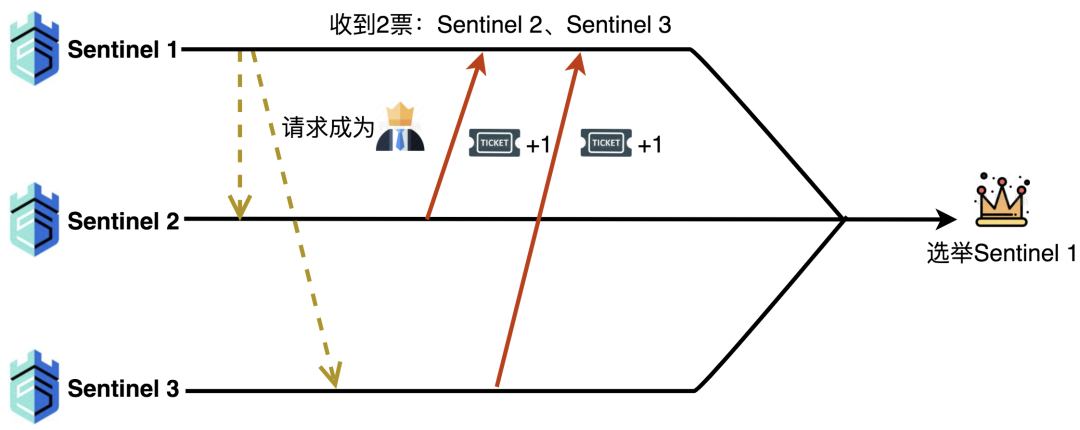
哨兵选主的完整流程,是从主节点被确认客观下线后启动的。首先要经过 领导者哨兵 的选举:哨兵如果认为主节点主观下线,就会向其他哨兵发起成为领导者的请求,收到请求的哨兵若还未投票,就会支持第一个请求它的哨兵;当某个哨兵获得超过半数(哨兵总数的 1/2 以上)的支持票时,就会成为领导者,负责执行后续的故障转移 —— 这一步用类似 Raft 算法的逻辑,避免了多个哨兵同时操作的混乱。
接下来,领导者哨兵会从所有从节点中筛选出 “合格候选人”:先排除处于离线状态、或长时间未与主节点同步数据(超过设定超时时间 10 倍)的从节点,再排除优先级(slave-priority)设为 0 的从节点(这类节点默认不参与选主)。筛选后,对剩余从节点按规则排序:首先看优先级,配置值越小优先级越高,若某节点优先级显著高于其他,直接当选;若优先级相同,则比较复制偏移量,偏移量越大说明同步主节点数据越完整,优先当选;若前两项都相同,就选择运行 ID(runid)最小的节点,确保结果唯一。
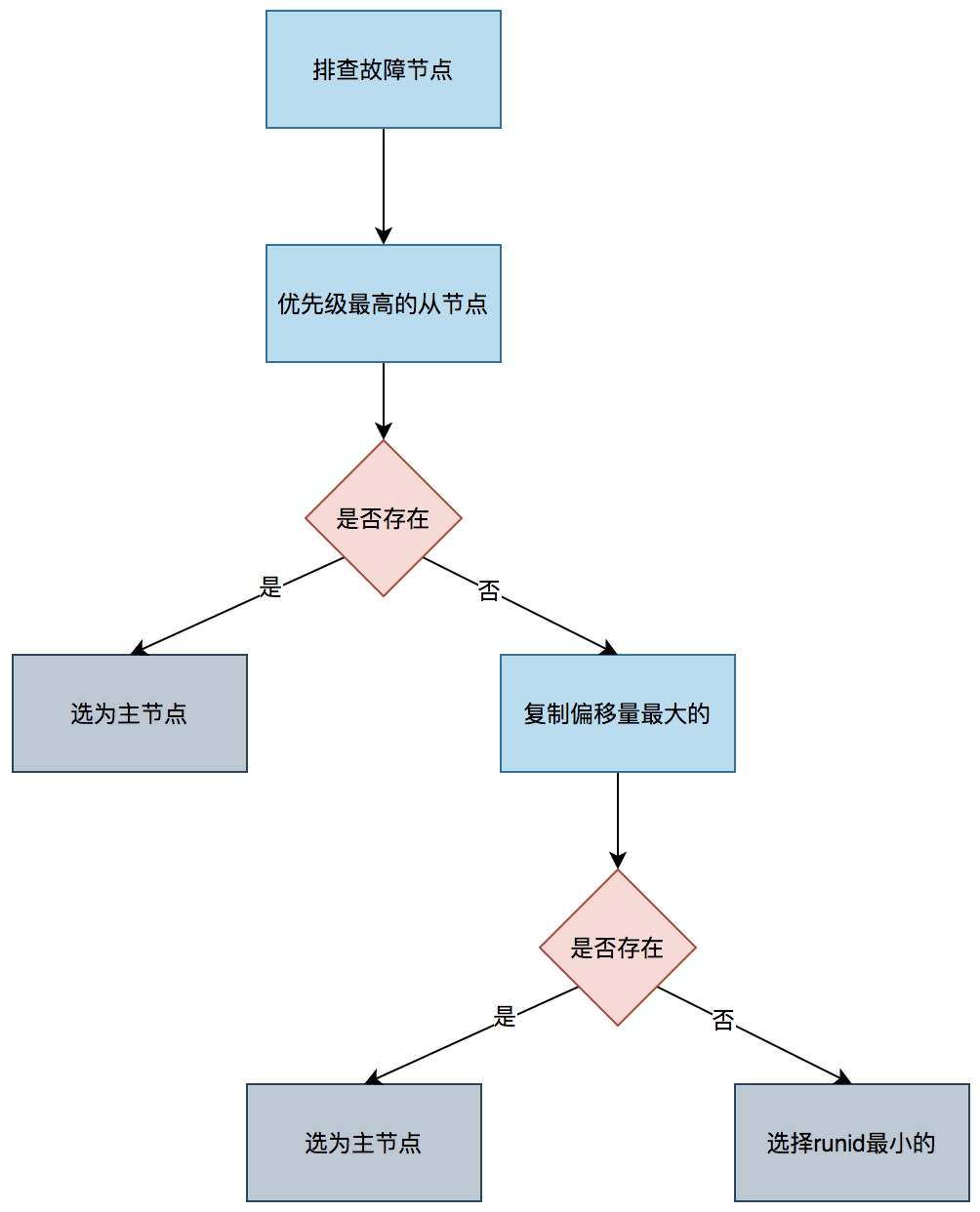
最后,领导者哨兵会向选中的从节点发送 “SLAVEOF NO ONE” 命令,将其晋升为新主节点,再让其他从节点改为复制这个新主节点,整个过程自动完成,无需人工介入,既保证了数据一致性,又能快速恢复集群的读写能力。
在Redis主从模式和哨兵模式中,虽然实现了数据复制和高可用,但在大规模部署时仍存在一些明显的局限性:
所以,我们需要Redis集群模式来应对这些场景,集群模式是一种分布式数据库解决方案,通过数据分片和主从复制实现数据的高可用和扩展性。
集群模式的核心优势:
让我们通过一个架构图来直观展示集群模式:
让我们通过一个具体的实验来演示集群模式的配置和使用:
## 创建集群配置目录
mkdir redis-cluster
cd redis-cluster
## 创建节点配置
for i in {1..6}; do
cat > redis-${i}.conf << EOF
port 700${i}
cluster-enabled yes
cluster-config-file nodes-700${i}.conf
cluster-node-timeout 5000
appendonly yes
daemonize yes
pidfile /var/run/redis-700${i}.pid
logfile "redis-700${i}.log"
dbfilename "dump-700${i}.rdb"
EOF
done## 启动6个Redis节点
for i in {1..6}; do
redis-server redis-${i}.conf
done
## 创建集群
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 \
127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 \
--cluster-replicas 1## 查看集群状态
redis-cli -p 7001
> CLUSTER INFO
## 输出示例:
## cluster_state:ok
## cluster_slots_assigned:16384
## cluster_slots_ok:16384
## cluster_slots_pfail:0
## cluster_slots_fail:0
## cluster_known_nodes:6
## cluster_size:3
## cluster_current_epoch:6
## cluster_my_epoch:1
## cluster_stats_messages_ping_sent:1234
## cluster_stats_messages_pong_sent:1234
## cluster_stats_messages_sent:2468
## cluster_stats_messages_ping_received:1234
## cluster_stats_messages_pong_received:1234
## cluster_stats_messages_received:2468
## 查看节点信息
> CLUSTER NODES
## 输出示例:
## 1a2b3c4d5e6f7g8h9i0j 127.0.0.1:7001@17001 myself,master - 0 0 1 connected 0-5460
## 2b3c4d5e6f7g8h9i0j1a 127.0.0.1:7002@17002 master - 0 0 2 connected 5461-10922
## 3c4d5e6f7g8h9i0j1a2b 127.0.0.1:7003@17003 master - 0 0 3 connected 10923-16383
## 4d5e6f7g8h9i0j1a2b3c 127.0.0.1:7004@17004 slave 1a2b3c4d5e6f7g8h9i0j 0 0 1 connected
## 5e6f7g8h9i0j1a2b3c4d 127.0.0.1:7005@17005 slave 2b3c4d5e6f7g8h9i0j1a 0 0 2 connected
## 6f7g8h9i0j1a2b3c4d5e 127.0.0.1:7006@17006 slave 3c4d5e6f7g8h9i0j1a2b 0 0 3 connected## 写入数据
redis-cli -p 7001
> SET key1 value1
> SET key2 value2
> SET key3 value3
## 查看数据分布
> CLUSTER KEYSLOT key1
## 输出示例:12539
> CLUSTER KEYSLOT key2
## 输出示例:4998
> CLUSTER KEYSLOT key3
## 输出示例:15224Redis集群使用哈希槽(Hash Slot)实现数据分片:
一个 Redis Cluster包含16384(2^14)个哈希槽,存储在Redis Cluster中的所有Key都可以通过Hash算法(CRC16 算法)算出一个Hash值,然后对16384取模,从而关联到某个槽,而每个节点负责一部分槽,Key算出来在哪个槽,就应该去负责这个槽的节点进行交互。
Redis集群使用CRC16算法计算键的哈希值,理论上可以产生65536(2的16次方)个不同的值,但实际选择了16384(2的14次方)个槽位,主要有以下几个原因:
内存和网络开销
unsigned char slots[REDIS_CLUSTER_SLOTS/8]实际需求考虑
碰撞概率分析
当客户端访问的键不在当前节点时,Redis集群会通过重定向机制引导客户端访问正确的节点:
让我们通过一个时序图来展示重定向过程:
Redis集群使用Gossip协议进行节点间通信:
让我们通过一个流程图来展示Gossip通信:

