
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
Redis 的持久化机制设计得非常巧妙,它提供了两种互补的持久化方式:RDB 和 AOF。这两种方式各有特点,能够满足不同场景的需求。
RDB(Redis Database)采用快照的方式,定期将内存中的数据以二进制格式保存到磁盘。这种方式的特点是文件体积小、恢复速度快,特别适合做冷备份和容灾恢复。但它的缺点是在两次快照之间如果发生故障,可能会丢失部分数据。
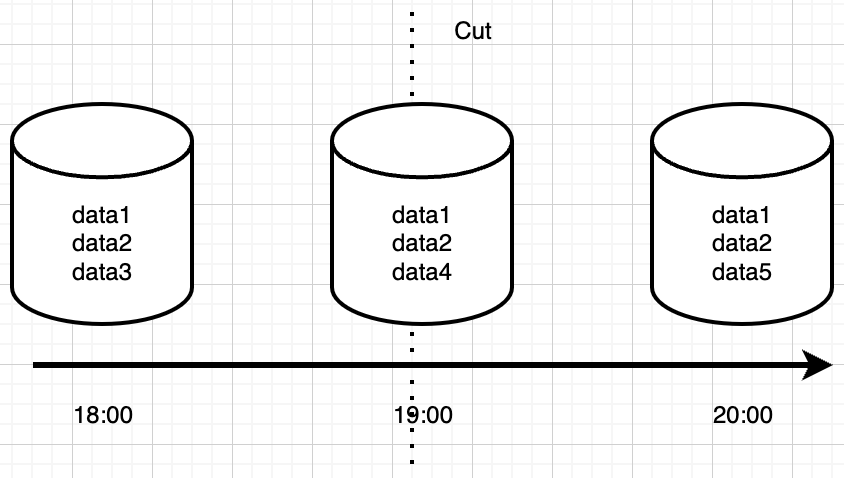
AOF(Append Only File)则采用日志的方式,记录每个写操作命令。这种方式的特点是数据安全性高,即使发生故障,最多也只会丢失 1 秒内的数据(取决于 fsync 策略)。但它的缺点是文件体积大、恢复速度慢。

在实际应用中,我通常会同时开启 RDB + AOF,这样既能保证数据完整性,又能兼顾恢复效率。RDB 作为主备份,AOF 作为增量日志,两者配合使用,既保证了数据安全,又不会对性能造成太大影响。
只要认清楚RDB是快照恢复,AOF是日志恢复的本质区别,我们甚至都不用去学习他们具体的实现,也能知道他们如有下差别:
体积方面:相同数据量下,RDB体积更小,因为RDB是记录的二进制紧凑型数据
恢复速度:RDB是数据快照,可以直接加载,而AOF文件恢复,相当于重放情况,RDB显然会更快
数据完整性:AOF记录了每条日志,RDB是间隔一段时间记录一次,用AOF恢复数据通常会更为完整。
RDB 的设计理念非常优雅,它通过二进制快照的方式,将内存中的数据以最紧凑的格式保存到磁盘。这种设计带来了几个显著的优势:
首先,RDB 文件是经过压缩的二进制格式,相比 AOF 的文本格式,文件体积要小得多。这不仅节省了磁盘空间,也减少了网络传输的开销,特别适合做数据备份和迁移。
其次,RDB 的恢复速度非常快。因为它是直接将文件读入内存,不需要像 AOF 那样重放命令,所以恢复时间与数据量成正比,而不是与命令数成正比。这对于大型数据库的恢复特别有利。
最重要的是,RDB 的生成过程是异步的。它通过 fork 子进程来完成快照的生成,主进程可以继续处理客户端请求,几乎不会阻塞 Redis 的主流程。这种设计让 RDB 特别适合在生产环境中使用。
让我们看看 RDB 保存的核心实现:
// rdb.c
int rdbSave(char *filename) {
// 创建临时文件
snprintf(tmpfile,256,"temp-%d.rdb", (int)getpid());
fp = fopen(tmpfile,"w");
// 写入 RDB 版本号
snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);
rioWrite(&rdb,magic,9);
// 遍历数据库
for (j = 0; j < server.dbnum; j++) {
// 写入数据库选择器
if (rdbSaveType(&rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;
if (rdbSaveLen(&rdb,j) == -1) goto werr;
// 保存键值对
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
initStaticStringObject(key,keystr);
if (rdbSaveKeyValuePair(&rdb,&key,o,expire) == -1) goto werr;
}
}
// 写入结束标记
if (rdbSaveType(&rdb,RDB_OPCODE_EOF) == -1) goto werr;
// 重命名临时文件
if (rename(tmpfile,filename) == -1) {
// 错误处理
}
return C_OK;
}这段代码展示了 RDB 文件生成的核心流程,包括文件创建、数据写入和文件重命名等步骤。整个过程是原子的,确保数据一致性。特别是使用临时文件的方式,避免了在写入过程中发生故障导致文件损坏的问题。
RDB 虽然有很多优点,但它也存在一些不可忽视的缺点。这些缺点主要来自其设计理念和实现机制:
最明显的问题是数据实时性。由于 RDB 是周期性触发的,在两次快照之间如果发生故障,可能会丢失最近几分钟的数据。这对于要求数据实时性的业务场景来说是不可接受的。比如在金融交易系统中,即使丢失几秒钟的数据也可能造成严重后果。
另一个重要问题是性能开销。RDB 的生成过程需要 fork 子进程,在 Linux 系统中,fork 操作会触发 Copy-on-Write 机制。当数据量很大时,这个操作会导致明显的内存压力,甚至可能引起 Redis 的短暂卡顿。特别是在大内存机器上,fork 操作可能会占用大量 CPU 资源,影响 Redis 的响应时间。
让我们看看 fork 相关的实现:
// server.c
int rdbSaveBackground(char *filename) {
pid_t childpid;
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1)
return C_ERR;
// 记录 fork 前的内存使用
server.rdb_save_time_start = time(NULL);
server.rdb_child_pid = childpid;
if (childpid == 0) {
// 子进程
closeListeningSockets(0);
redisSetProcTitle("redis-rdb-bgsave");
retval = rdbSave(filename);
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
// 父进程
server.rdb_save_time_start = time(NULL);
server.rdb_child_pid = childpid;
return C_OK;
}
}这段代码展示了 RDB 后台保存的实现,通过 fork 创建子进程来执行实际的保存操作。在大内存场景下,fork 操作可能导致明显的性能抖动。特别是在 Redis 4.0 之前,fork 操作会复制整个内存空间,这可能导致 Redis 服务暂时不可用。
回答
AOF 日志记录每次写操作,数据持久性强。支持重放机制,还可以通过 rewrite 实现文件压缩,利于恢复。
分析
AOF 的设计理念更接近传统数据库的 WAL(Write-Ahead Logging)机制,它通过记录每个写操作命令来实现数据持久化。这种设计带来了几个显著的优势:
首先,AOF 提供了更好的数据安全性。由于每个写操作都会被记录,即使发生故障,最多也只会丢失 1 秒内的数据(取决于 fsync 策略)。这种特性使得 AOF 特别适合对数据安全性要求高的场景,比如金融交易系统。
其次,AOF 文件是文本格式的,记录了 Redis 命令,这使得它具有良好的可读性。在出现问题时,可以直接查看 AOF 文件来定位问题,这对于问题排查非常有帮助。同时,AOF 文件也可以用于数据恢复和迁移。
让我们看看 AOF 写入的核心实现:
// aof.c
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
sds buf = sdsempty();
// 选择数据库
if (dictid != server.aof_selected_db) {
char seldb[64];
snprintf(seldb,sizeof(seldb),"%d",dictid);
buf = sdscatprintf(buf,"*2\r\n$6\r\nSELECT\r\n$%lu\r\n%s\r\n",
(unsigned long)strlen(seldb),seldb);
server.aof_selected_db = dictid;
}
// 将命令转换为 RESP 格式
buf = catAppendOnlyGenericCommand(buf,argc,argv);
// 追加到 AOF 缓冲区
if (server.aof_state == AOF_ON)
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
// 根据配置决定是否立即同步
if (server.aof_fsync == AOF_FSYNC_ALWAYS)
aof_fsync(server.aof_fd);
}这段代码展示了 AOF 命令追加的核心流程,包括数据库选择、命令格式化和缓冲区写入等步骤。AOF 的写入是追加式的,这保证了写入性能,同时通过缓冲区机制,可以在性能和安全性之间取得平衡。
AOF 虽然提供了更好的数据安全性,但它也带来了一些不可忽视的问题。这些问题主要来自其实现机制和设计理念:
最明显的问题是文件体积。由于 AOF 需要记录每个写操作,在写入频繁的场景下,AOF 文件会快速增长。即使有重写机制,在重写之前,文件大小可能会达到原始数据大小的数倍。这不仅占用大量磁盘空间,也会影响文件系统的性能。
另一个重要问题是性能开销。AOF 的写入是追加式的,虽然写入性能好,但频繁的 fsync 操作会影响 Redis 的响应时间。特别是在 always 模式下,每个写操作都需要等待 fsync 完成,这会导致明显的性能下降。
重写过程也是一个性能瓶颈。AOF 重写需要扫描整个数据库,生成新的 AOF 文件,这个过程会消耗大量 CPU 和 IO 资源。虽然重写是在后台进行的,但它仍然会影响 Redis 的整体性能。
让我们看看 AOF 重写的核心实现:
// aof.c
int rewriteAppendOnlyFile(char *filename) {
rio aof;
FILE *fp;
char tmpfile[256];
// 创建临时文件
snprintf(tmpfile,256,"temp-rewriteaof-%d.aof", (int)getpid());
fp = fopen(tmpfile,"w");
// 初始化 RIO 对象
rioInitWithFile(&aof,fp);
// 遍历数据库
for (j = 0; j < server.dbnum; j++) {
// 写入数据库选择器
if (rioWriteBulkCount(&aof,'*',2) == 0) goto werr;
if (rioWriteBulkString(&aof,"SELECT",6) == 0) goto werr;
if (rioWriteBulkLongLong(&aof,j) == 0) goto werr;
// 遍历键值对
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
initStaticStringObject(key,keystr);
// 写入过期时间
if (expiretime != -1) {
if (rioWriteBulkCount(&aof,'*',3) == 0) goto werr;
if (rioWriteBulkString(&aof,"PEXPIREAT",9) == 0) goto werr;
if (rioWriteBulkString(&aof,keystr,sdslen(keystr)) == 0) goto werr;
if (rioWriteBulkLongLong(&aof,expiretime) == 0) goto werr;
}
// 写入键值对
if (rioWriteBulkObject(&aof,&key) == 0) goto werr;
if (rioWriteBulkObject(&aof,o) == 0) goto werr;
}
}
// 重命名临时文件
if (rename(tmpfile,filename) == -1) {
// 错误处理
}
return C_OK;
}这段代码展示了 AOF 重写的核心流程,包括文件创建、数据遍历和命令重写等步骤。整个过程是原子的,确保数据一致性。但这个过程会消耗大量资源,特别是在数据量大的情况下。
在重写过程中,Redis不但将新的操作记录在原有的AOF缓冲区,而且还会记录在AOF重写缓冲区。一旦新AOF文件创建完毕,Redis 就会将重写缓冲区内容,追加到新的AOF文件,再用新AOF文件替换原来的AOF文件。
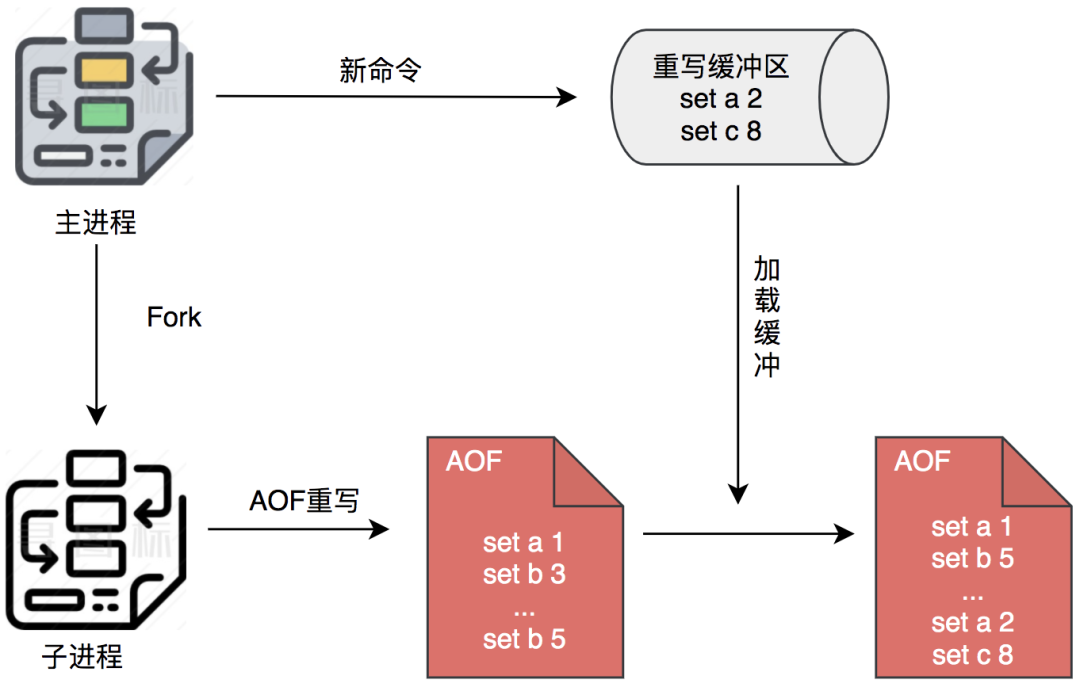
Redis 的 AOF 重写机制采用双缓冲区设计是经过精心考量的。AOF 缓冲区仅保存最近待写入的命令,而 AOF 重写缓冲区则专门记录从重写开始后的所有新命令,这样才能确保重写期间数据完整性。这两个缓冲区各司其职,缺一不可。
关于触发重写的条件,Redis 提供了两个关键配置参数:auto-aof-rewrite-percentage 表示当前 AOF 文件大小相比上次重写时增长的百分比(默认100%),auto-aof-rewrite-min-size 则设定了触发重写的最小文件大小(默认64MB)。也就是说,当 AOF 文件超过64MB且比上次重写时大一倍时,就会触发重写流程。这个检查过程由 Redis 的周期性任务 serverCron 负责执行,确保在不影响主线程性能的前提下,适时启动重写操作。这种设计既避免了频繁重写带来的性能开销,又确保了 AOF 文件不会无限膨胀。
总结一下,AOF重写可以有以下4个要点:
重写触发。AOF重写可以通过手动触发(bgrewriteaof命令)或自动触发(根据配置的AOF文件大小和增长率)。当重写触发时,主进程会fork出一个子进程来执行重写操作。
子进程重写。子进程会读取Redis DB中的数据,以字符串命令的格式写入到新的AOF文件中。这个过程不会阻塞主进程,主进程可以继续处理命令请求。
增量数据。在重写过程中,如果Redis接收到了新的写入命令,主进程会将这些命令写入到AOF重写缓冲区中。这个缓冲区用于存储重写期间的新写入命令。
数据同步。当子进程完成重写操作后,会向主进程发送一条信号。主进程收到该信号后,会调用一个信号处理函数,将AOF重写缓冲区中的所有内容追加到新的AOF文件中,使得新旧两个AOF文件所保存的数据库状态一致,这样即使数据持续写入,也不会有发生数据丢失。
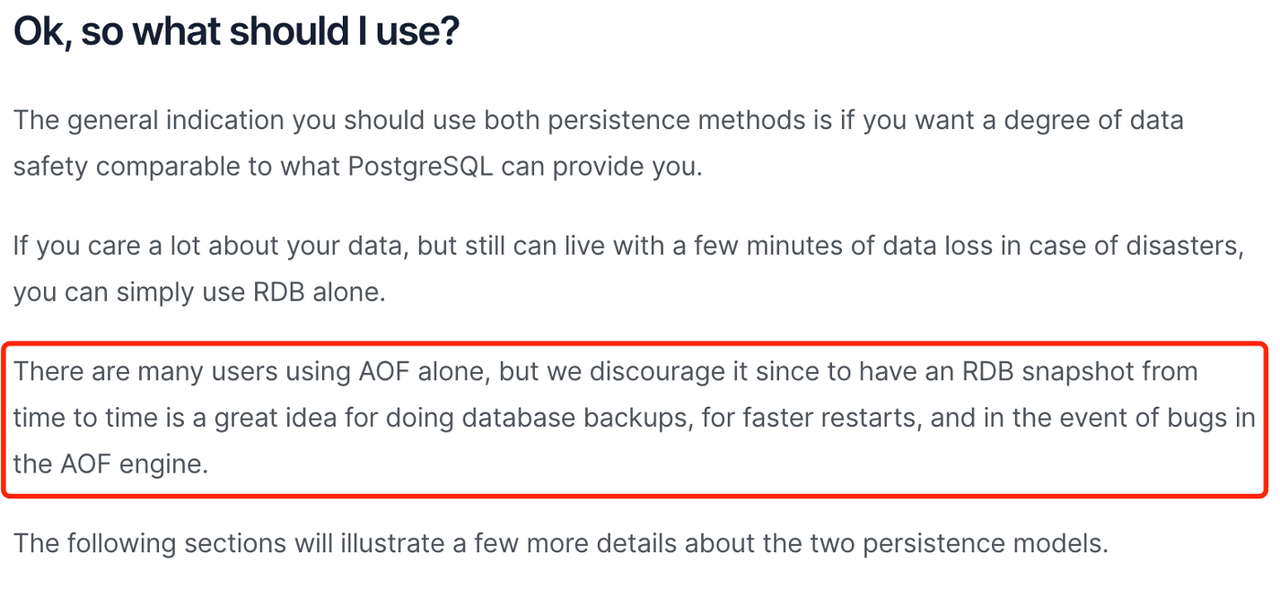
从业务需求角度来看,如果能够接受分钟级别的数据丢失,可以选择RDB;如果需要尽量保证数据安全,可以考虑混合持久化;如果只用AOF,建议选择everysec策略进行刷盘,在可靠性和性能之间取得平衡。
从持久化理念来看,始终开启快照是一个推荐的方式,这也是Redis官方默认开启RDB而不开启AOF的原因。同时,官方文档也明确不推荐只开启AOF。
Redis提供了三种刷盘策略,每种策略对应不同的数据安全级别:
1)always策略最为严格,每次写入后立即调用redis_fsync(实际上是fdatasync)进行刷盘,确保数据万无一失。这种模式虽然安全,但性能开销最大。
2)everysec策略则更加平衡,它会在满足条件时(通常是距离上次刷盘超过1秒)启动一个后台线程异步刷盘。这种设计既保证了数据安全(最多丢失1秒数据),又不会对主线程造成明显阻塞。
3)no策略则完全依赖操作系统的刷盘机制,性能最好但风险最高。
/* Perform the fsync if needed. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* redis_fsync is defined as fdatasync() for Linux in order to avoid
* flushing metadata. */
latencyStartMonitor(latency);
redis_fsync(server.aof_fd); /* Let's try to get this data on the disk */
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
server.aof_last_fsync = server.unixtime;
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.unixtime > server.aof_last_fsync)) {
if (!sync_in_progress) aof_background_fsync(server.aof_fd);
server.aof_last_fsync = server.unixtime;
}值得注意的是,这些策略的实现展现了Redis在系统设计上的精妙权衡:通过将耗时操作异步化、批量化,既保证了数据安全,又维持了高性能。特别是everysec策略的后台线程设计,巧妙地避开了磁盘I/O可能造成的性能瓶颈,这种设计思路非常值得借鉴。
简单来看,Redis AOF无非就是执行请求时,每条日志都会写入到AOF日志。
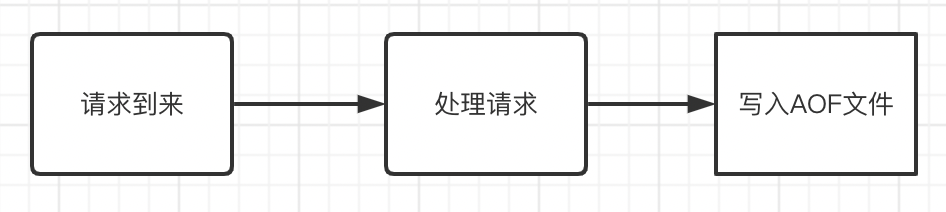
这里可能会有个疑问,为什么要先执行Redis命令,再把数据写入AOF日志,主要有如下考虑
保证正确写入。如果当前的命令语法有问题,错误的命令记录到AOF日志里后可能还会进行语法检查。先执行Redis命令,再把数据写入AOF日志可以保证写入的都是正确可执行的命令。
不阻塞当前写操作。因为当写操作命令执行成功后才会将命令记录到AOF日志,避免写入阻塞。这种方式可以提高Redis的响应性能,特别是在高并发场景下。
潜在问题。这种机制也存在一些缺陷。由于执行写操作命令和记录日志是两个过程,如果Redis还没来得及将命令写入到硬盘时发生宕机,数据会有丢失的风险。同时,AOF日志的写入操作也是在主线程中执行,当Redis把日志文件写入磁盘的时候,还是会阻塞后续的操作无法执行。
回答
可以。执行bgsave过程中,Redis依然可以继续处理操作命令的。
这一点得益于写时复制机制,当主线程要修改共享数据里的某一块数据,就会发生写时复制,数据的物理内存就会被复制一份,主线程在这个数据副本进行修改操作。与此同时,子进程可以继续把原来的数据写入到RDB文件。这种机制保证了数据的一致性,同时也避免了阻塞主线程。
我们也要注意性能影响,虽然写时复制机制允许在RDB快照过程中修改数据,但如果在这个期间有大量的写入操作,会导致主进程多拷贝一份数据,消耗大量额外的内存。因此,在RDB快照过程中,应该尽量避免大量的写入操作。
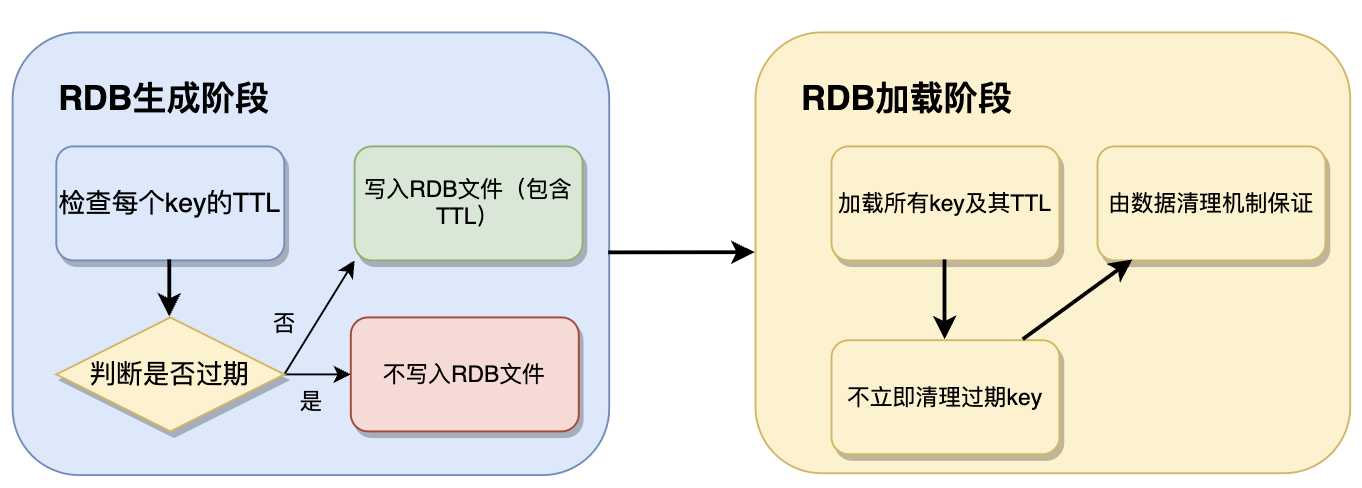
生成阶段处理。在Redis使用RDB持久化时,过期键的处理方式取决于RDB生成和恢复的阶段。Redis在生成RDB快照时,不会直接删除过期的键,而是检查每个key的TTL,如果某个key已经过期,则不会写入RDB文件;如果key未过期,则会连同其TTL一起写入RDB。这样,生成的RDB文件中不会包含已过期的键,避免存储无用数据。
加载阶段处理。当Redis重启并加载RDB文件时,Redis会正常加载所有key及其TTL,但不会立即清理所有过期key,而是由数据清理机制来保证。在客户端访问key时,Redis发现key已过期,则立即删除。Redis运行时的定期清理机制可能也会被触发,主动删除过期key。
在 Redis 主从架构中,过期键的处理机制是由主节点统一控制的,从节点的行为与主节点有着本质区别。主节点会通过惰性删除和定期删除两种方式主动清理过期键,在生成 RDB 文件时也会自动跳过所有过期键,只持久化未过期的键。
而从节点则完全采取被动策略,即使检测到某个键已过期也不会自行删除,而是等待主节点同步 DEL 命令。这种差异在多个场景下都有体现:从节点加载 RDB 文件时会保留所有键,包括已过期的;处理读请求时也会如实返回已过期键的值,不会主动过滤。
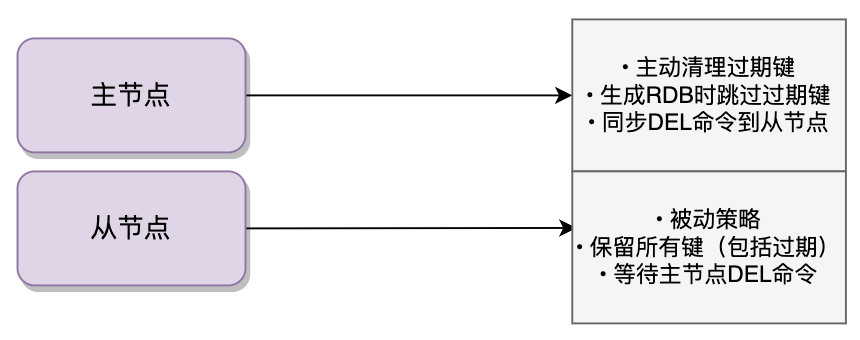
这种设计主要是为了保证数据一致性,避免从节点因时钟偏差或网络问题导致误删:
主节点在删除过期键后会立即向所有从节点发送 DEL 命令,但由于网络延迟等因素,从节点可能会短暂保留已过期的键,这就导致了主从架构中经典的过期数据读取问题,也就是客户端在从节点查询时可能会读到已过期的数据,需要依赖主从同步的最终一致性来保证数据的正确性。
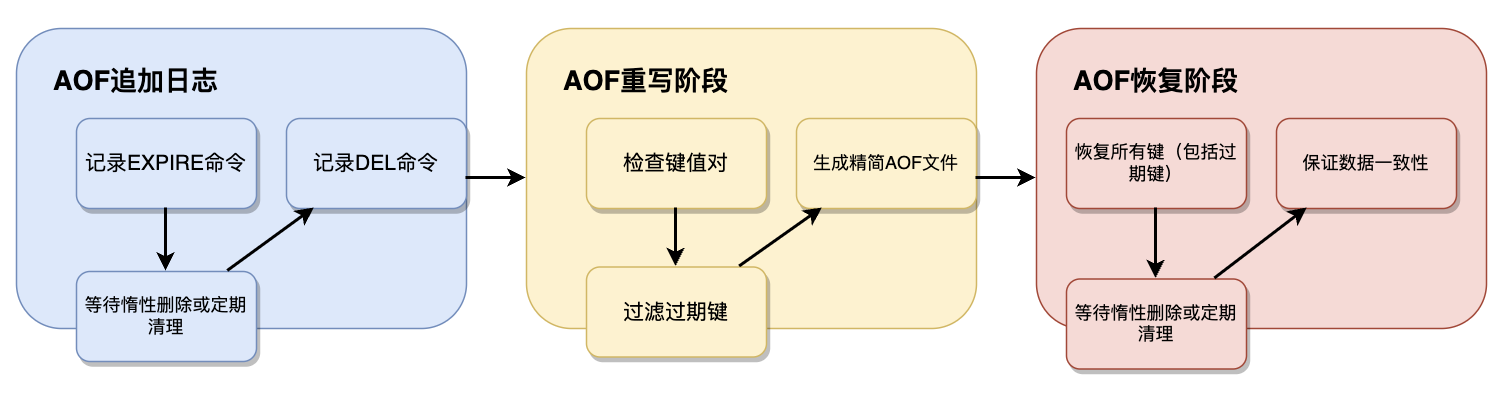
AOF追加日志。在AOF持久化模式下,Redis会记录EXPIRE命令,过期后不自动删除,只有触发惰性删除或定期清理时才写入DEL命令。这种方式保证了AOF文件记录了完整的键生命周期。
AOF重写。在AOF重写阶段,Redis会对键值对进行检查,过滤掉已过期的key,生成更精简的AOF文件。这样可以减少AOF文件的大小,提高恢复效率。
AOF恢复。在加载AOF时,Redis会恢复所有key,包括过期的key。这些过期的key需要等待惰性删除或定期清理机制来处理。这种机制确保了数据的一致性,同时也避免了在恢复过程中丢失数据。
回答
从库不会进行过期扫描,从库的过期键处理依靠主服务器控制,主库在key到期时,会在AOF文件里增加一条del指令,同步到所有的从库,从库通过执行这条del指令来删除过期的key。
如果主从同步发生意外,原本主库的key过期了,但是del指令没有同步给从库成功,导致从库内存中存在已经过期但没有删除的key,这时候有客户端访问从库时,即使key还是内存的,但是从库发现key是过期的,就不会返回key的数据给客户端了。
回答
主要有这么几个地方,一个是调用save或者bgsave命令,一个是根据我们配置周期进行,一个是Redis关闭之前,这三个是比较常见的,其它边缘一点的还有主从全量复制发送RDB文件等。
分析
命令触发。RDB持久化可以通过save或bgsave命令手动触发。save命令会阻塞主线程,直到RDB文件创建完毕;bgsave命令会创建一个子进程来执行RDB持久化,不会阻塞主线程。
配置触发。Redis会根据配置文件中的save配置项自动触发RDB持久化。例如,如果配置了"save 900 1",表示在900秒内有1个修改,就会触发RDB持久化。
关闭触发。当Redis关闭时,会自动执行一次RDB持久化,确保数据不会丢失。
其他触发。在主从复制过程中,主节点会生成RDB文件发送给从节点,这时也会触发RDB持久化。此外,当执行FLUSHALL命令清空数据库时,也会触发RDB持久化。
回答
AOF触发流程主要有3个,一个是Redis关闭的时候,另一个是每一次事件循环钩子函数beforeSleep(),最后一个是每一次事件循环函数servercron里面。
分析
Redis关闭。当Redis关闭时,会执行一次AOF刷盘操作,确保数据不会丢失。
事件循环钩子。在每一次事件循环的beforeSleep()钩子函数中,Redis会根据配置的appendfsync策略决定是否进行AOF刷盘。always策略会在每个事件循环都进行刷盘,everysec策略会每秒进行一次刷盘,no策略则不会主动进行刷盘。
时间事件。在每一次事件循环的servercron()函数中,Redis会检查是否需要执行AOF刷盘。这个函数会定期执行,确保AOF文件能够及时写入磁盘。
刷盘策略。根据配置的appendfsync策略,AOF刷盘的行为会有所不同。always策略提供了最高的数据安全性,但性能最差;everysec策略在性能和安全性之间取得了平衡;no策略提供了最好的性能,但数据安全性最低。
回答
当执行阻塞式持久化的时候,由主进程进行RDB快照保存,会阻塞主进程。当执行后台持久化时,由fork出的子进程来进行RDB快照保存。如果数据量比较大的时候,会导致fork子进程这个操作比较耗时,从而阻塞主进程。由于采用了写时复制技术,如果在进行RDB快照保存的时候,有大量的写入操作执行,会导致主进程多拷贝一份数据,消耗大量额外的内存。
分析
阻塞式持久化。当执行save命令时,Redis会阻塞主进程,直到RDB文件创建完毕。这种方式会严重影响Redis的性能,特别是在数据量较大的情况下。
后台持久化。当执行bgsave命令时,Redis会创建一个子进程来执行RDB持久化,不会阻塞主进程。但是,fork子进程的过程可能会比较耗时,特别是在数据量较大的情况下,这会导致主进程短暂阻塞。
写时复制。在RDB快照过程中,如果主进程有大量的写入操作,会导致写时复制,主进程需要多拷贝一份数据,这会消耗大量的内存。因此,在RDB快照过程中,应该尽量避免大量的写入操作。
回答
当appendfsync使用always,如果AOF写入日志压力过大会导致主进程处理其他请求很慢。当appendfsync使用everysec,如果后台线程上一轮的fsync没有完成,会导致我们本轮主线程执行write被阻塞(直到fsync完成)。当AOF重写发生时,如果数据量比较大,会导致fork子进程这个操作比较耗时,从而阻塞主进程。
分析
always策略。在always策略下,Redis会在每个事件循环都将aof_buf缓冲区里的所有内容通过write写入AOF文件描述符,并且调用fsync同步它。这种方式在主线程中进行同步刷盘,会阻塞主线程,影响Redis的性能。
everysec策略。在everysec策略下,Redis会在每个事件循环都将aof_buf缓冲区的所有内容通过write写入到AOF文件描述符,并且每隔超过一秒就要在子线程中对AOF文件进行一次fsync同步。如果后台线程上一轮的fsync没有完成,主线程的write操作会被阻塞,直到fsync完成。
AOF重写。在AOF重写过程中,Redis会fork一个子进程来执行重写操作。如果数据量比较大,fork子进程的过程可能会比较耗时,导致主进程短暂阻塞。此外,在重写过程中,主进程需要将新的写入命令写入到AOF重写缓冲区,这也会消耗一定的CPU和内存资源。
混合持久化原理:AOF混合持久化是在AOF重写的基础上做了一些改动。在重写开始时,Redis会先使用RDB持久化函数将当前内存数据写入到新的AOF文件中,这部分数据以RDB格式存储。然后,在重写过程中,新的写入命令会以AOF格式追加到新的AOF文件中。这样,新的AOF文件就包含了RDB格式和AOF格式的数据。
优势:混合持久化结合了RDB和AOF的优点。RDB格式的数据提供了较快的恢复速度,而AOF格式的数据提供了更好的数据安全性。这种方式既保证了数据的安全性,又提供了较快的恢复速度。
使用场景:混合持久化特别适合需要快速恢复且对数据安全性要求较高的场景。例如,在系统重启后,Redis可以快速恢复RDB格式的数据,然后通过AOF格式的数据来保证数据的完整性。
回答
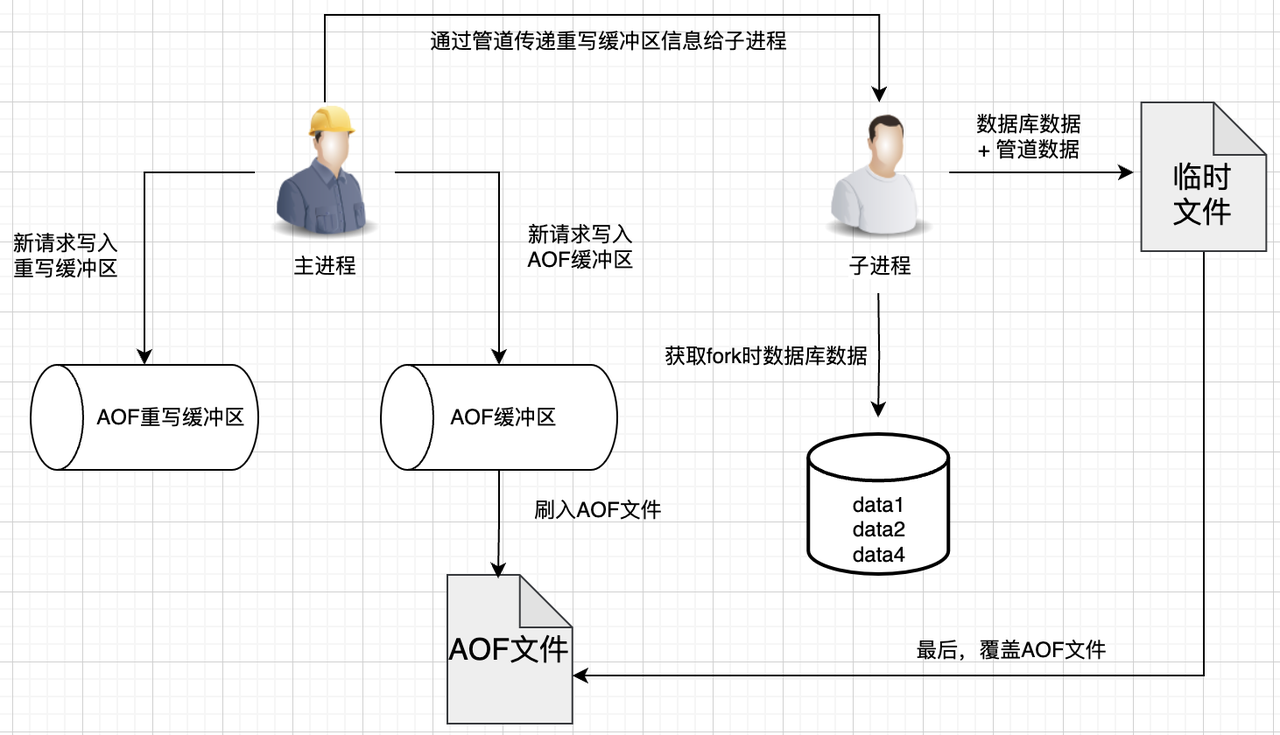
当aof重写触发那一刻,主进程就会fork出一个子进程,然后这个子进程读取Redis DB中的数据,以字符串命令的格式写入到新AOF文件中。
如果这个时候Redis接收到了新的写入命令,那么主进程会将这些 增量数据 写入到AOF重写缓冲区中。在子进程将数据都写入到新AOF文件后,主进程会通过管道将AOF重写缓冲区里面的数据发送给子进程,子进程再将这一份数据追加到新AOF文件中,保证新AOF文件的完整性。
问题主要是三点
CPU开销。在AOF重写过程中,主进程需要将新的写入命令写入到AOF重写缓冲区,然后通过管道将数据发送给子进程,子进程还需要将这些数据写入到新的AOF文件中。这些操作都会消耗CPU资源,特别是在高并发场景下。
内存开销。在重写过程中,AOF缓冲区和AOF重写缓冲区中存储的是相同的数据,这导致了内存的浪费。特别是在数据量较大的情况下,这种浪费会更加明显。
磁盘开销。在重写过程中,AOF缓冲区需要将数据写入到旧的AOF文件,AOF重写缓冲区需要将数据写入到新的AOF文件,这导致了磁盘空间的浪费。特别是在AOF文件较大的情况下,这种浪费会更加明显。
问题的本质是有两个不太合理的设计:
这两个是问题的本质,理清楚了本质,优化起来并不难,Redis在7.0版本引入了MP-AOF方案
Redis 7.0 引入的 MP-AOF(Multi Part AOF)机制彻底改变了传统的单文件 AOF 持久化方式,采用了一种更现代化、更可靠的多文件协同方案。这种创新设计完美解决了传统 AOF 重写时的性能瓶颈和数据一致性问题。
MP-AOF 的核心思想是将数据持久化工作分解到两个相互配合的文件中:
BASE AOF 文件相当于数据快照,包含了某个时间点前所有操作的最终状态
INCR AOF 文件则负责记录 BASE 文件生成期间新增的操作命令
这种双文件架构带来了革命性的改进:当需要执行 AOF 重写时,Redis 不再需要暂停服务。主进程可以继续处理请求并将新命令写入 INCR AOF 文件,而子进程则基于 fork 时的数据快照生成新的 BASE 文件。这两个文件通过一个智能的 manifest 清单文件进行管理,这个清单文件就像一位称职的图书管理员,始终记录着当前有效的 BASE 和 INCR 文件版本。
整个工作流程堪称精妙:当新的 BASE 文件生成完成后,Redis 只需简单地更新 manifest 文件中的指针,就能实现无缝切换。之前的旧文件会被标记为 HISTORY 状态,由后台线程负责清理。这种设计不仅确保了数据安全,还大幅提升了系统可用性 - 即使在重写过程中发生崩溃,系统也能通过检查 manifest 文件快速恢复到最近的一致状态
为了更好理解,我们用一张图来讲述:
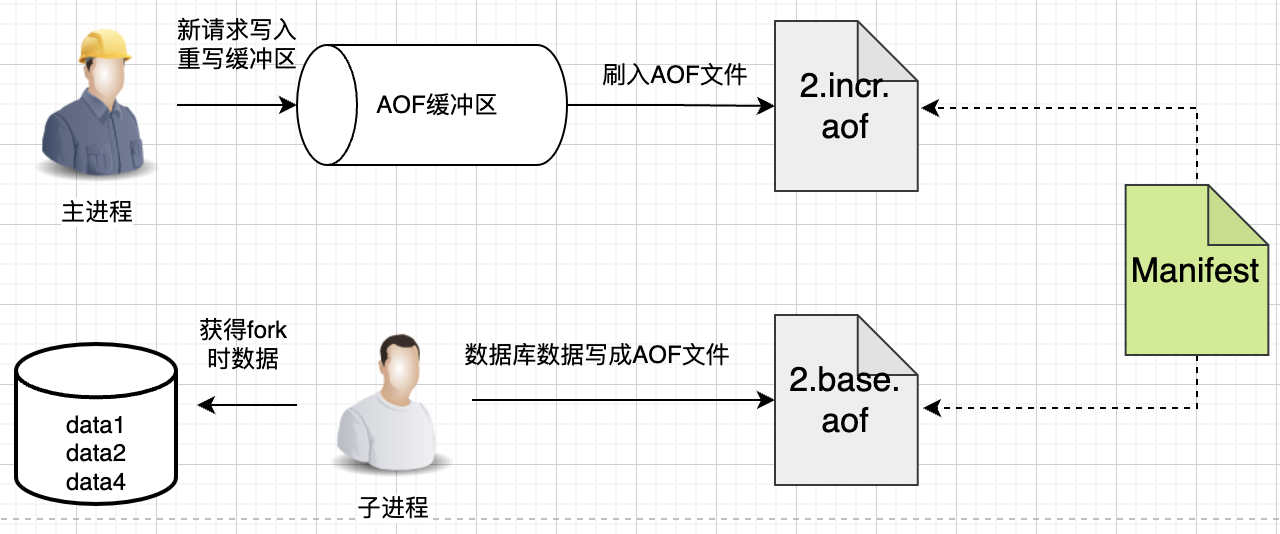
可以看到,现在重写阶段,在主进程中写AOF缓冲区即可,AOF缓冲区的数据最终落入新打开的2.INCR AOF文件,至于子进程,就根据fork时数据库的数据,重写并生成新的一个2.BASE.AOF文件。
新生成的2.BASE AOF和新打开的2.INCR AOF就代表了当前时刻Redis的全部数据。
写完之后呢,也不是覆盖原有的1.BASE.AOF 和 1.INCR.AOF,而只需要更新manifest文件,manifest是文件清单,描述了当前有效的BASE AOF、INCR AOF是哪个,这里可以简单理解为manifest就是一个配置。
那之前旧的1.BASE AOF、1.INCR.AOF文件怎么办呢?Redis是将它们标记为HISTORY AOF,这些HISTORY AOF会被Redis异步删除掉。

