
关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
Redis管道(Pipeline)是一种优化客户端与Redis服务器之间通信的机制,主要用于减少网络往返时间(RTT,Round-Trip Time),从而提升性能。管道技术的核心在于批量处理,它允许客户端将多个命令打包后一次性发送给服务器,服务器执行完所有命令后再一次性返回结果。
管道的工作原理主要涉及三个层面:客户端层面负责将多个命令缓存到本地,当缓存达到一定数量或显式调用EXEC时,才会一次性将所有命令发送到服务器;服务器层面则按照接收到的顺序依次执行所有命令,执行完成后将所有结果一次性返回;结果处理层面由客户端接收所有命令的执行结果,并按顺序进行处理。
这种机制特别适用于以下场景:批量写入(如初始化缓存、批量插入数据)、批量读取(如批量获取多个用户信息)、高并发场景(减少通信次数,降低系统负载)以及事务优化(避免多次网络往返)。
示例代码:
# 不使用管道
for i in range(1000):
redis.set(f'key{i}', f'value{i}') # 1000次网络往返
# 使用管道
with redis.pipeline() as pipe:
for i in range(1000):
pipe.set(f'key{i}', f'value{i}')
pipe.execute() # 只有1次网络往返在分布式缓存系统中,热Key是一个常见但危险的问题。当某些Key的访问频率远高于其他Key时,会导致系统资源分配不均,进而影响整体性能。这个问题在电商、社交、游戏等高频访问场景中尤为突出。
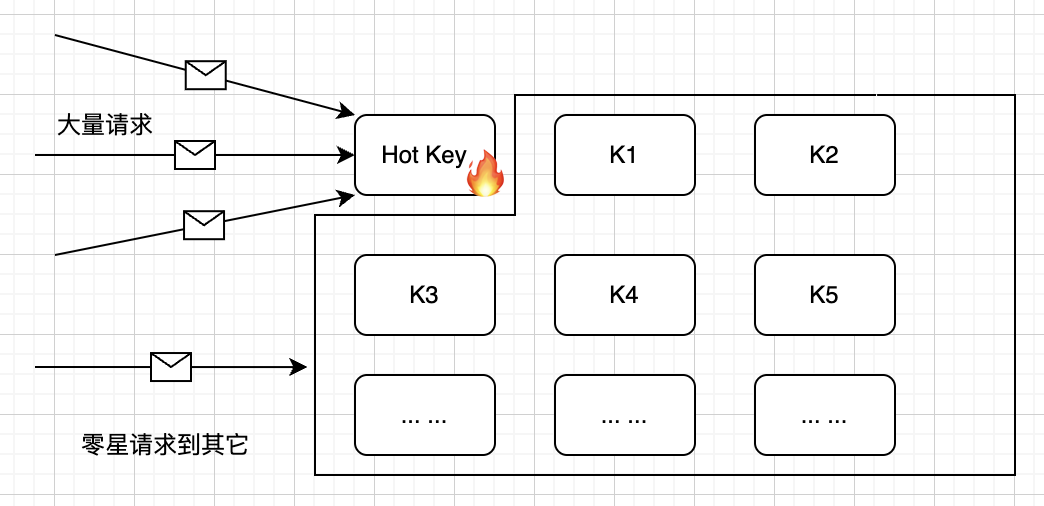
热Key带来的主要问题体现在三个方面。首先是资源集中消耗,大量请求集中在少数几个Key上,会导致某个节点负载过高,影响系统的整体性能。其次是单点瓶颈,在分布式缓存系统中,如果热Key集中在某一个节点上,会形成性能瓶颈,甚至导致节点崩溃。最后是网络带宽压力,频繁访问热Key会占用较多的网络带宽,可能引发网络拥塞。
在实际业务中,热Key经常出现在以下场景:电商促销活动中的秒杀商品库存信息、社交平台中爆款帖子的点赞数或评论数、游戏领域中排行榜Top玩家的分数等。这些场景都需要特别关注热Key的处理。
监控手段主要包括三个方面:
## 使用redis-cli的hotkeys参数(Redis 4.0+)
redis-cli --hotkeys
## 使用monitor命令临时监控(生产环境慎用)
redis-cli monitor | grep -E "GET|SET"其次是业务层埋点,通过在代码中添加统计逻辑,可以更精确地识别热Key,同时设置监控告警,设置Key访问频率阈值告警
因为热Key会很可能带来慢查询,还可以通过慢查询日志。
## 查看慢查询日志
redis-cli slowlog get多级缓存思路,通过本地缓存来减少对Redis的访问。即在应用层对热Key进行本地缓存,减少对Redis的直接访问。
负载均衡思路,将单个热Key拆分为多个子Key,分散压力。
## 原始热Key
product:123:info
##拆分为多个Key
product:123:info:part1
product:123:info:part2
product:123:info:part3读写分离
读写分离思路,通过增加从节点来分担读请求的压力。
其它思路
工程实践上,还有很多其它思路,比如对热Key访问实施限流、比如选择更合适的Redis数据结构等等
在 Redis 中,大 Key 是影响性能的 “隐形杀手”,需要重点关注。所谓大 Key,并没有绝对的标准,但行业内通常认为:当 String 类型的值大小超过 10KB(比如存储一篇包含多段文字和图片链接的 JSON 文章,或一个包含上千个字段的配置信息),或者 Hash、List、Set、ZSet 等集合类型的元素数量超过 5000 个(比如一个 Hash 存储某用户 3 年的订单记录,累计 6000 条字段),就可以判定为大 Key。这些看似普通的 Key,会在实际运行中引发一系列性能问题。
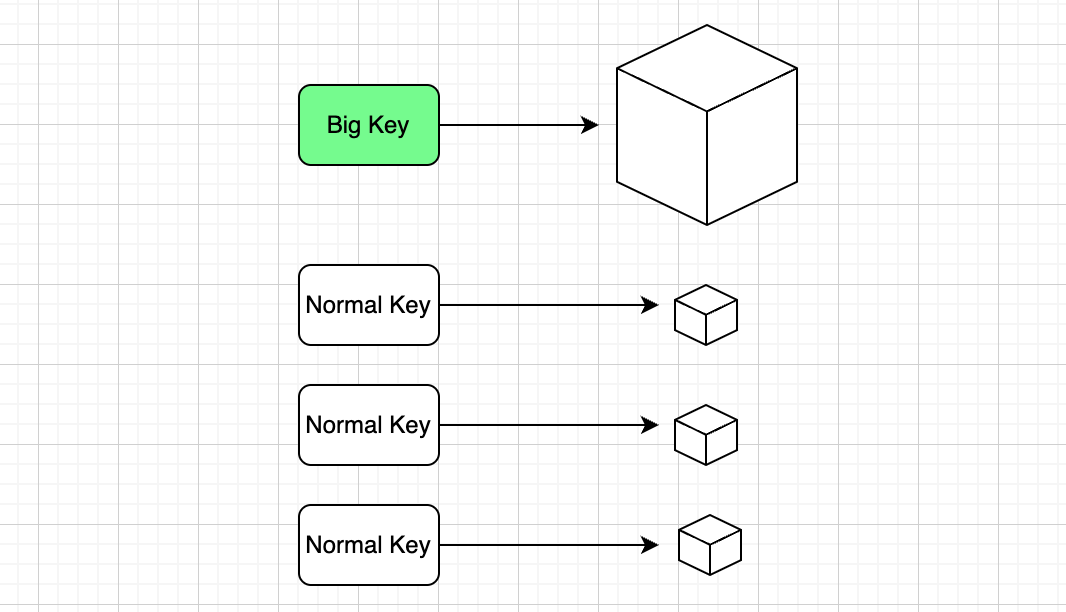
大 Key 的影响体现在四个关键维度,每一个都可能成为系统瓶颈:
大 Key 的产生往往与业务场景密切相关,常见的 “重灾区” 包括:
粉丝 / 关注列表:明星账号的粉丝 ZSet 可能存储 1000 万 + 用户 ID,元素数量远超 5000,每次更新或查询都需遍历大量数据;
用户行为记录:某电商平台将用户一年的浏览记录存在一个 List 中,按每天 100 条计算,一年就有 3.6 万条,远超阈值,查询历史记录时极易引发延迟;
缓存大对象:将商品详情(包含多图 URL、规格参数、评价摘要等)以 String 类型缓存,JSON 字符串可能达到 20KB 以上,每次读取都会占用大量网络和内存资源。
要解决大 Key 问题,需先精准排查,常用排查手段有三种:
解决大 Key 的核心思路是 “拆分、清理、优化”,具体方案需结合业务场景:
通过针对性的排查和优化,可有效规避大 Key 带来的性能风险,让 Redis 始终保持高效稳定的运行状态。
Redis的事务机制与关系型数据库的事务有很大不同。在Redis中,事务更像是一个命令打包执行的机制,而不是传统意义上的事务。Redis的事务主要保证的是命令的原子性执行,而不是ACID特性。
Redis事务的特点主要体现在三个方面。首先是命令的原子性,事务中的所有命令要么全部执行,要么全部不执行。其次是命令的顺序性,事务中的命令按照入队顺序执行,不会被其他客户端的命令打断。最后是隔离性,事务执行过程中,其他客户端提交的命令不会插入到事务执行队列中。
Redis不支持回滚的原因主要有两点。第一,Redis的设计理念是简单高效,回滚机制会增加系统的复杂度。第二,Redis认为命令错误通常是由于编程错误导致的,这类错误应该在开发阶段就被发现和修复,而不是依赖回滚机制。
延迟队列是一种特殊的消息队列,它允许消息在指定的时间之后才被消费。在实际业务中,延迟队列有着广泛的应用场景,比如订单超时自动取消、定时任务调度、消息重试等。
Redis实现延迟队列的核心在于ZSet的特性。ZSet是一个有序集合,每个元素都有一个分数(Score),这个分数可以用来表示延迟时间。当我们需要添加一个延迟任务时,将任务的执行时间作为Score,任务内容作为Value存入ZSet。然后通过定时任务,定期扫描ZSet中Score小于当前时间的元素,这些就是需要执行的任务。
实现延迟队列需要注意以下几点。首先是时间精度,Redis的ZSet使用浮点数作为Score,可以精确到毫秒级别。其次是任务执行,需要确保任务被正确执行,可以考虑使用分布式锁来避免任务重复执行。最后是性能优化,可以通过批量处理来提高效率。
示例代码:
public class RedisDelayQueue {
private final RedisTemplate<String, String> redisTemplate;
private final String queueKey = "delay:queue";
// 添加延迟任务
public void addTask(String taskId, String taskData, long delaySeconds) {
double score = System.currentTimeMillis() + delaySeconds * 1000;
redisTemplate.opsForZSet().add(queueKey, taskData, score);
}
// 处理延迟任务
public void processDelayTasks() {
long now = System.currentTimeMillis();
// 获取所有到期的任务
Set<String> tasks = redisTemplate.opsForZSet()
.rangeByScore(queueKey, 0, now);
if (tasks != null && !tasks.isEmpty()) {
// 处理任务
for (String task : tasks) {
try {
processTask(task);
// 从队列中移除已处理的任务
redisTemplate.opsForZSet().remove(queueKey, task);
} catch (Exception e) {
// 处理失败,可以考虑重试或记录日志
log.error("处理延迟任务失败: " + task, e);
}
}
}
}
private void processTask(String task) {
// 实现具体的任务处理逻辑
}
}List是Redis中最基础的数据结构之一,它通过LPUSH和RPOP命令实现了一个简单的消息队列。以我的经验,这种方式特别适合那些对消息可靠性要求不是特别高的场景。
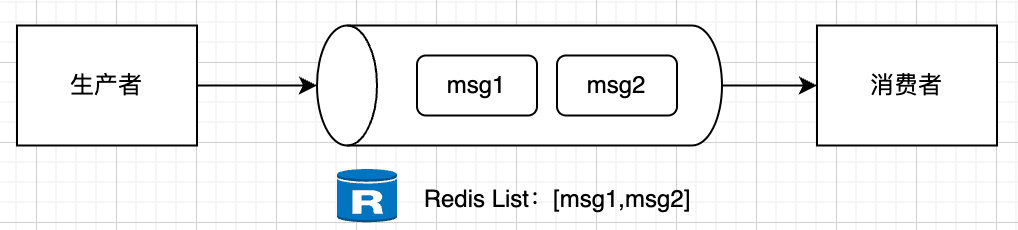
Redis命令示例:
## 生产者:将消息推入队列
LPUSH myqueue "message1"
LPUSH myqueue "message2"
## 消费者:从队列中获取消息
RPOP myqueue # 返回 "message1"
RPOP myqueue # 返回 "message2"
## 查看队列长度
LLEN myqueue
## 查看队列内容
LRANGE myqueue 0 -1命令说明:
// 生产者代码
public void produce(String message) {
// 将消息推入队列
redis.lpush("queue", message);
}
// 消费者代码
public void consume() {
while (true) {
// 从队列中获取消息
String message = redis.rpop("queue");
if (message != null) {
// 处理消息
processMessage(message);
}
}
}List实现消息队列的优点是实现简单,性能好。但缺点也很明显:。在实际项目中,我通常只在一些简单的场景下使用这种方式,比如日志收集、简单的任务队列等。
Pub/Sub是Redis提供的发布订阅模式,它允许消息的发送者和接收者完全解耦。这种模式特别适合那些需要实时消息通知的场景,比如系统监控、实时数据推送等。
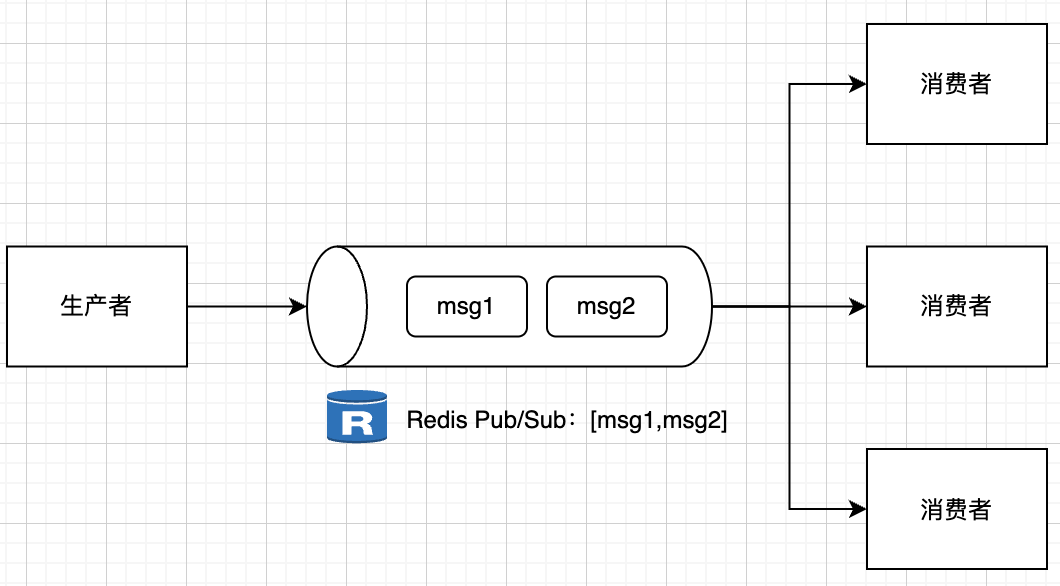
Redis命令示例:
## 订阅者1:订阅频道
SUBSCRIBE news
## 订阅者2:订阅频道
SUBSCRIBE news
## 发布者:发布消息
PUBLISH news "Hello World"
## 订阅者1和订阅者2都会收到消息:
## 1) "message"
## 2) "news"
## 3) "Hello World"
## 取消订阅
UNSUBSCRIBE news
## 模式订阅(支持通配符)
PSUBSCRIBE news.*命令说明:
// 发布者代码
public void publish(String channel, String message) {
// 发布消息
redis.publish(channel, message);
}
// 订阅者代码
public void subscribe(String channel) {
// 订阅频道
redis.subscribe(new JedisPubSub() {
@Override
public void onMessage(String channel, String message) {
// 处理消息
processMessage(message);
}
}, channel);
}Pub/Sub模式的优点是。但它的缺点也很明显:消息不持久化、不支持消息确认、不支持消息重试。在实际项目中,我通常用它来实现一些实时性要求高,但对消息可靠性要求不高的场景。
Stream是Redis 5.0引入的新特性,它提供了一个完整的消息队列实现。Stream不仅支持消息持久化,还支持消费者组、消息确认等高级特性。以我的经验,这是目前Redis中最强大的消息队列实现。
不过需要特别说明的是,虽然Stream功能最全,但相比专业的消息队列中间件(如Kafka、RocketMQ等),在可靠性方面还是存在明显差距。主要原因是。在实际项目中,如果对消息的可靠性要求极高,我建议还是使用专业的消息中间件。
Redis命令示例:
## 生产者:添加消息到Stream
XADD mystream * sensor-id 1234 temperature 19.8 humidity 80
XADD mystream * sensor-id 1234 temperature 20.1 humidity 81
## 查看Stream中的消息
XRANGE mystream - + # 查看所有消息
XRANGE mystream - + COUNT 2 # 限制返回数量
## 创建消费者组
XGROUP CREATE mystream mygroup 0
## 消费者:从Stream中读取消息
XREADGROUP GROUP mygroup consumer1 COUNT 1 STREAMS mystream >
## 返回:
## 1) 1) "mystream"
## 2) 1) 1) "1609459200000-0"
## 2) 1) "sensor-id"
## 2) "1234"
## 3) "temperature"
## 4) "19.8"
## 5) "humidity"
## 6) "80"
## 确认消息已处理
XACK mystream mygroup 1609459200000-0
## 查看未确认的消息
XPENDING mystream mygroup命令说明:
// 生产者代码
public void produce(String stream, Map<String, String> message) {
// 添加消息到Stream
redis.xadd(stream, StreamEntryID.NEW_ENTRY, message);
}
// 消费者代码
public void consume(String stream, String group, String consumer) {
// 创建消费者组
try {
redis.xgroupCreate(stream, group, StreamEntryID.LAST_ENTRY, true);
} catch (Exception e) {
// 组已存在
}
while (true) {
// 从Stream中读取消息
List<StreamEntry> entries = redis.xreadGroup(
group, consumer, 1, 0, false,
new StreamEntryID(stream, ">")
);
for (StreamEntry entry : entries) {
try {
// 处理消息
processMessage(entry);
// 确认消息
redis.xack(stream, group, entry.getID());
} catch (Exception e) {
// 处理失败,消息会自动重试
}
}
}
}Stream的优点是。它提供了消费者组、消息确认、消息重试等高级特性,能够满足大多数消息队列场景的需求。在实际项目中,我通常用它来实现一些对消息可靠性要求不是特别高的场景,比如系统通知、数据同步等。但对于订单处理、支付通知等对可靠性要求极高的场景,我建议使用Kafka等专业的消息中间件。
Redis 的原子性操作原理是其作为分布式锁实现的基础,这个特性主要来自 Redis 的设计架构。Redis 采用单线程模型处理命令请求,所有命令都是串行执行的,不存在并发问题,单条命令的执行过程不会被其他命令打断。
Redis 提供了很多原子命令,如 INCR、HSET、LPUSH 等,这些命令本身是不可分割的,要么完全执行,要么完全不执行,不需要额外的同步机制就能保证原子性。虽然 Redis 也提供了 MULTI/EXEC 事务机制来保证一组命令的原子性,但在实际应用中较少使用,因为事务性太弱了,用起来还比较复杂。Redis应用中更多使用 Lua 脚本来实现复杂操作的原子性。
Lua 脚本在 Redis 中的执行是原子的,脚本执行过程中不会被其他命令打断,这使得它非常适合实现复杂的原子操作。让我们看看 Redis 中原子操作的核心实现:
// server.c
void processCommand(client *c) {
// 命令执行前的检查
if (c->flags & CLIENT_MULTI) {
// 事务处理
queueMultiCommand(c);
return;
}
// 执行命令
call(c,CMD_CALL_FULL);
// 命令执行后的处理
if (c->flags & CLIENT_DIRTY_EXEC) {
// 事务执行失败处理
discardTransaction(c);
}
}这段代码展示了 Redis 命令执行的核心流程,包括事务处理和命令执行。整个过程是原子的,确保了数据一致性。
Lua 脚本在 Redis 中的原子性是一个需要深入理解的概念。Redis 使用单线程模型处理命令,这意味着 Lua 脚本执行时不会被其他命令打断,从而保证了脚本执行的原子性。这种设计使得 Lua 脚本非常适合实现复杂的原子操作。
Lua 脚本在 Redis 中的执行是作为一个整体进行的,执行过程中不会被中断,这为脚本提供了良好的原子性保证。
但是,lua并不能保证绝对原子性,他本质还是依赖于Redis单线程特性,只是说LUA脚本作为一条执行命令,是不会被打断的。
但如果脚本执行到一半时 Redis 服务崩溃(如进程被杀、服务器断电),已执行的命令可能被持久化,未执行的部分则会丢失,导致原子性破坏。

