关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
这个问题是典型的海量场景问题,下面我们直接以三种思路,来进行解答。
第一种思路是使用位图(BitMap)的一个比特(bit)来表示一个 QQ 号是否存在。逐个读取QQ号,并将该QQ号对应的位设置为1。例如,QQ号12345678会对应位图中的第12345678个位置。当再次读取到一个已经存在于位图中的号码时,其对应的位已经是1,无需进行任何操作,这样就完成了重复号码的自动忽略。处理完所有QQ号后,遍历位图,将所有标记为1的位所对应的QQ号输出,即可得到去重后的结果。
假设 QQ 号的范围是 1 到 40 亿,40 亿个 bit 即 5 亿个字节,需要 500MB 内存空间。如果使用 roaring bitmap 等压缩算法,则所需的内存可以更小。
如果数据量更大或者内存更小导致内存无法容纳 bitmap, 则需要bitmap 结合分块思想。假设我们只有 100MB 内存,则可以按照 QQ 号最高的 3 位将 40 亿数据分成 8 份,每份只需要 62.5 MB 的内存空间。
日常工作中我们也可以使用 sort 命令对数据进行外部排序后再进行去重,外部排序采用分治的思想先将大文件分割成小块,每个小块排序后存储到磁盘上,最后对磁盘上的所有有序块进行多路归并得到最终结果,从而实现对远大于内存的数据进行排序。
布隆过滤器也可能用于去重,但由于其存在假阳性问题会导致去重结果中丢失部分 QQ 号,因此需要谨慎使用。
下面我们针对这些方法做详细的分析。
位图(BitMap)去重的核心思路是利用 1 个二进制位(bit)标记 1 个 QQ 号的存在状态: 0 = 不存在,1 = 存在),避免存储完整 QQ 号本身。
假设 QQ 号的范围是 1 到 40 亿,则需为 40 亿个整数分配 bit 位。1 字节(Byte)= 8 比特(bit),因此总内存 = 40 亿 bit / 8 = 500 MB(刚好在 1GB 内存限制内)。
首先,在内存中开辟一块 500MB 的连续空间(或者使用 roaring bitmap 等压缩算法),初始所有 bit 位设为 0。
然后,读取每一个待处理的 QQ 号(记为id);计算id对应的 bit 位置,将其设为 1 标记此 QQ 号已存在。比如 QQ 号为 12345678 那么我们就将第 12345678 位设为 1:

参考代码如下:
# 1. 计算 QQ 号 对应的字节索引(在bitmap中的第几个字节)
byte_index = qq_id // 8
# 2. 计算该偏移在字节中的位偏移(0-7,表示字节中的第几个bit)
bit_offset = offset % 8
# 3. 生成位掩码:只有bit_offset位置为1,其余为0。例如:bit_offset=3 -> 0b00001000(十进制8)
mask = 1 << bit_offset
# 4. 按位或运算:将bitmap中对应字节的bit_offset位设为1(其他位不变)
bitmap[byte_index] |= mask最后,直接遍历位图,凡 bit 位为 1 的 offset 即为去重后的唯一 QQ 号。
可以注意到,bitmap 所需的内存取决于 QQ 号的范围(即最大值与最小值之差),而不是 QQ 号的数量。
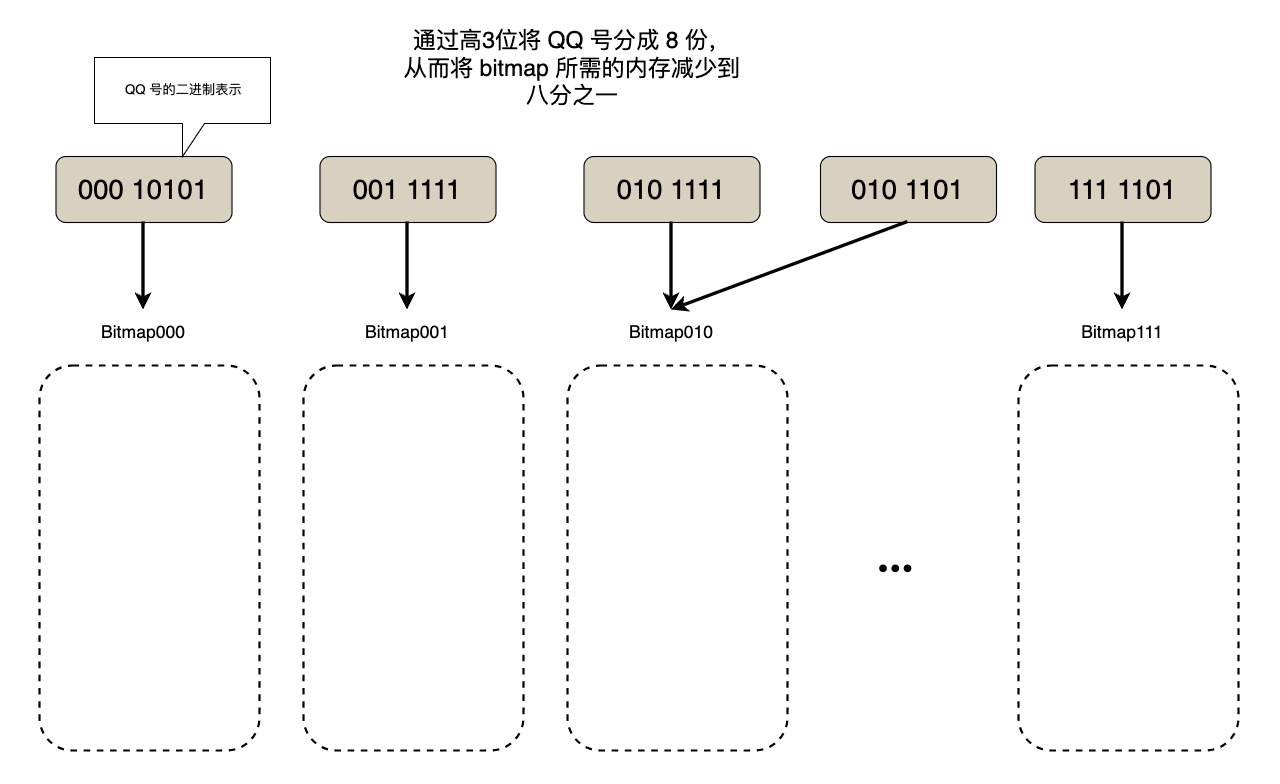
当内存更小(如仅 100MB),无法容纳完整位图时,用 “分治思想” 将海量数据拆成内存可容纳的小块,逐块处理。
以 100MB 内存为例, 选择 QQ 号的最高 3 位作为分块依据, 3 位二进制可表示 0~7 共 8 个区间,刚好将 40 亿数据平均分成 8 块,每块数据量约 5 亿,对应位图大小 = 5 亿 bit = 62.5 MB ≤ 100MB。
首先根据 QQ 号的最高 3 位将其分组,分别存放在 8 个文件中。然后读取每个分片文件,使用位图进行去重。最后,将 8 个分片的结果拼接起来即可。
我们可以使用 sort -un qq.txt 命令进行外部排序然后去重,其中 -n 表示按数值排序,-u 去重。
外部排序采用 “分治 + 多路归并” 的方式,先排序再去重(排序后重复数据会相邻,便于删除),可以对远大于内存空间的大文件进行去重。
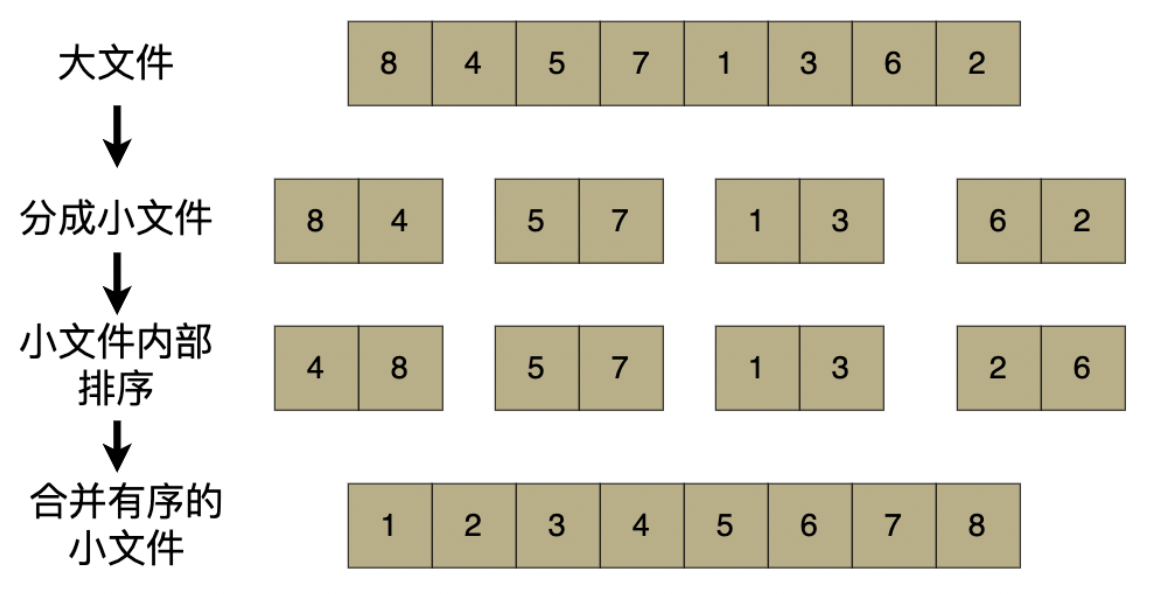
具体步骤:
分块:假设内存仅能容纳 100MB 数据,将 40 亿 QQ 号的大文件(约 32GB,按每个 QQ 号 8 字节算)按 100MB 为单位拆分成 320 个小文件(块);逐个读取小文件到内存,用快速排序 / 归并排序等算法对其内部的 QQ 号排序,得到 “有序小文件”(称为 “顺串”),将排序后的顺串写入磁盘。
多路归并(合并所有有序顺串):同时读取所有 320 个有序顺串的 “首元素”,放入内存中的 “优先队列(堆)”;
每次从堆中取出 “最小的 QQ 号” 写入最终大文件,然后从该 QQ 号所属的顺串中读取下一个元素补充到堆中;
重复此过程,直到所有顺串的元素都被取出,最终得到一个 “全局有序” 的 QQ 号大文件(所有 QQ 号按升序 / 降序排列)。
去重:遍历全局有序文件,记录 “上一个读取的 QQ 号”;若当前读取的 QQ 号与 “上一个” 相同,则跳过;若不同,则保留当前 QQ 号并更新 “上一个” 的值;遍历结束后,保留的 QQ 号即为去重结果。

