在 Feed 流设计中,有两种经典模型:推模型 (Push/Fan-out on Write) 和 拉模型 (Pull/Fan-in on Read)。我先分析它们的优缺点。
推模型 (Push Model):
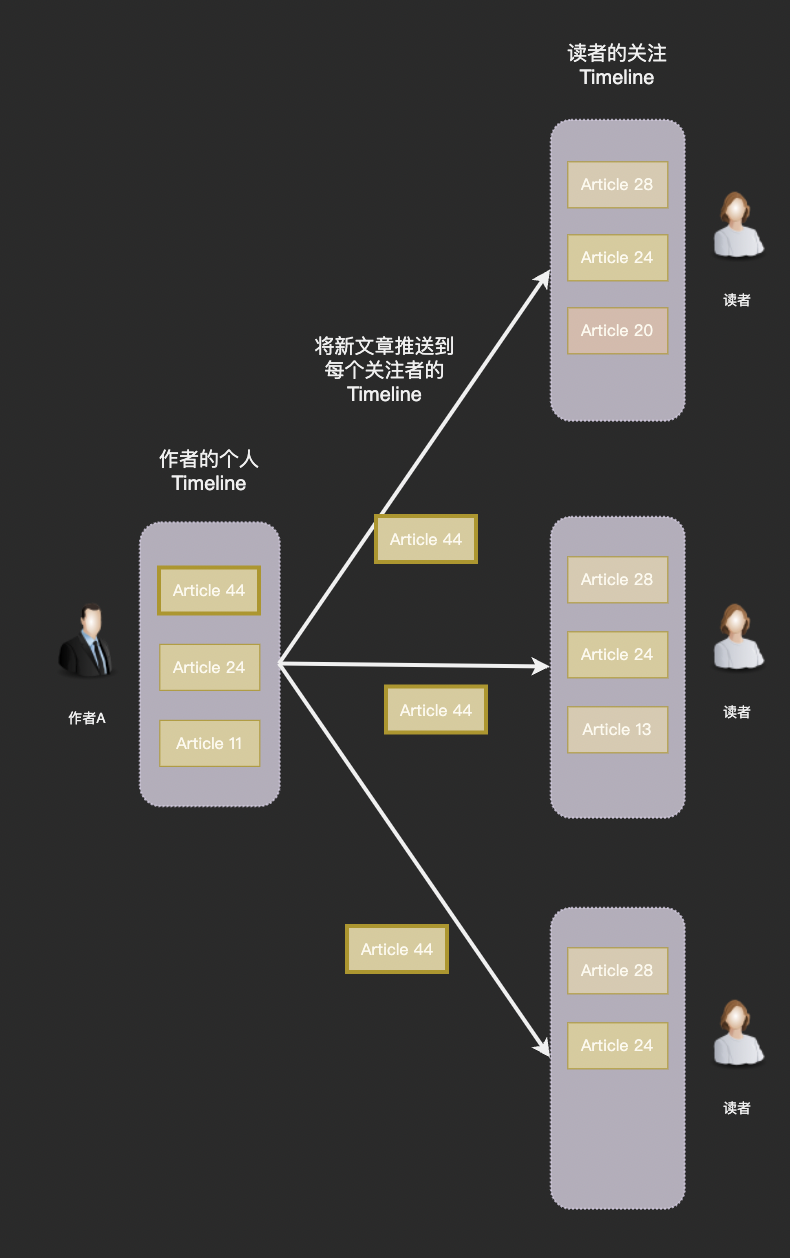
- 原理:当用户 A 发布一条帖子时,系统立即将这条帖子“推送”到所有关注 A 的粉丝(Followers)的个人 Feed 列表中。通常用一个 per-user 的 Feed 列表(例如 Redis List 或数据库表)存储每个用户的 Feed 项(帖子 ID + 元数据)。
- 优点:
- 实时性高:用户上线后直接从自己的 Feed 列表读取,延迟低(毫秒级)。
- 读操作简单:O(1) 或 O(k) 时间,其中 k 是分页大小。
- 缺点:
- 写放大严重:如果 A 有 100 万粉丝,每发帖需写 100 万次,消耗大,尤其对明星用户(高粉丝量)。
- 存储冗余:同一帖子在多个粉丝的 Feed 中重复存储。
- 不适合离线用户:推送时如果粉丝离线,系统仍需处理所有粉丝,导致无谓开销。
在实现过程中通常使用消息队列解耦发帖事件,比如当一个有 10 万粉丝的用户发帖时,我们将他的 100 个粉丝打包到一条消息中,交给一个 worker 去执行推送。这种方式可以有效利用多机的计算能力,并且在遇到错误时更容易重试。
拉模型 (Pull Model):
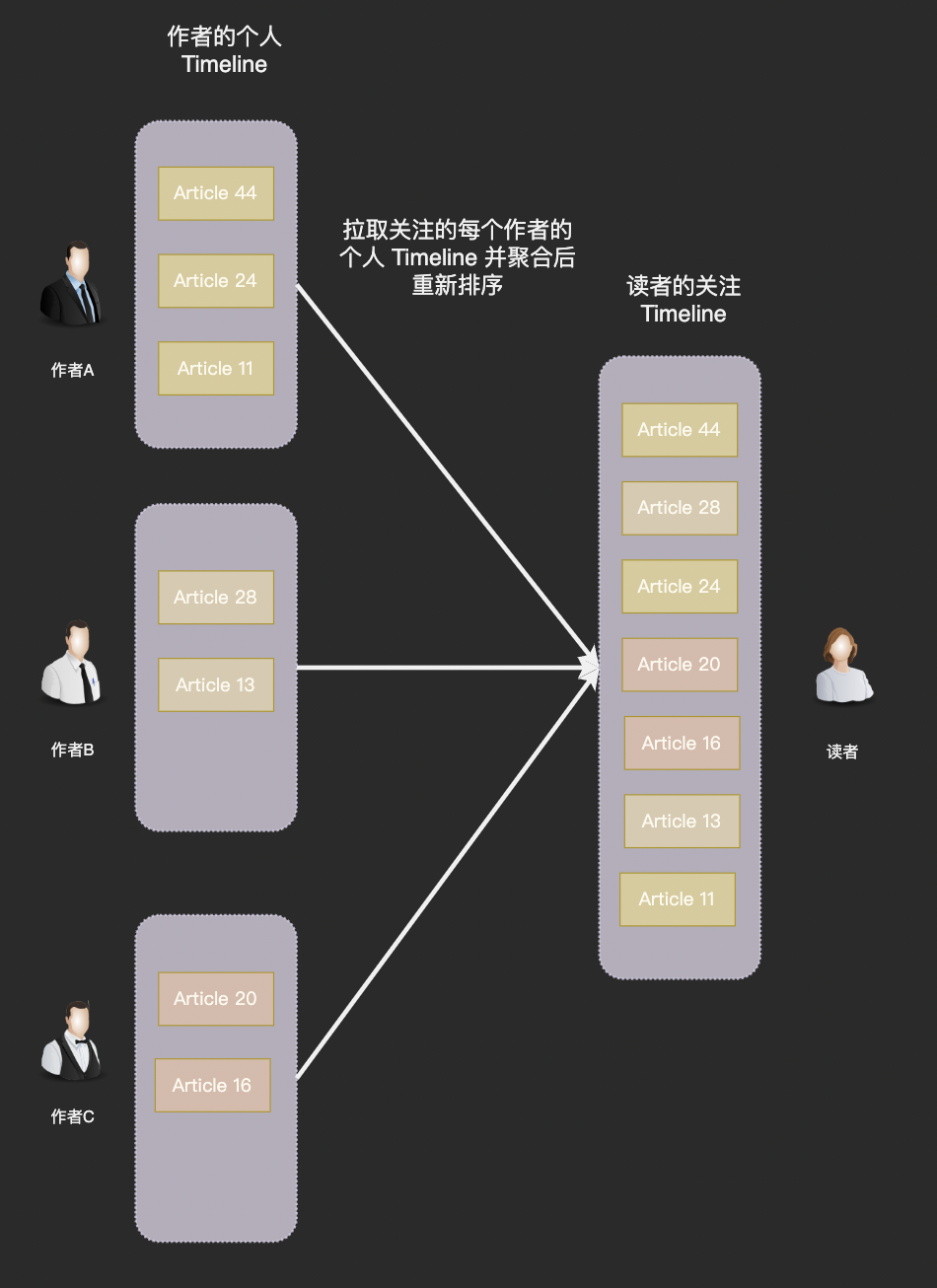
- 原理:用户 B 上线查看 Feed 时,系统从 B 关注的所有人(Followings)的帖子列表中“拉取”最近的帖子,然后合并排序(按时间降序)。
- 优点:
- 写操作简单:发帖只写一次到发布者的帖子列表中,无写放大。
- 存储高效:帖子只存一份,无冗余。
- 适合离线用户:只在用户请求时计算,避免无效计算。
- 缺点:
- 实时性差:如果 B 关注 1000 人,每次读需查询 1000 个列表并合并,延迟高(可能秒级)。
- 读放大严重:高峰期并发请求多,数据库压力大。
- 复杂排序:需处理时间戳合并,可能引入缓存失效问题。
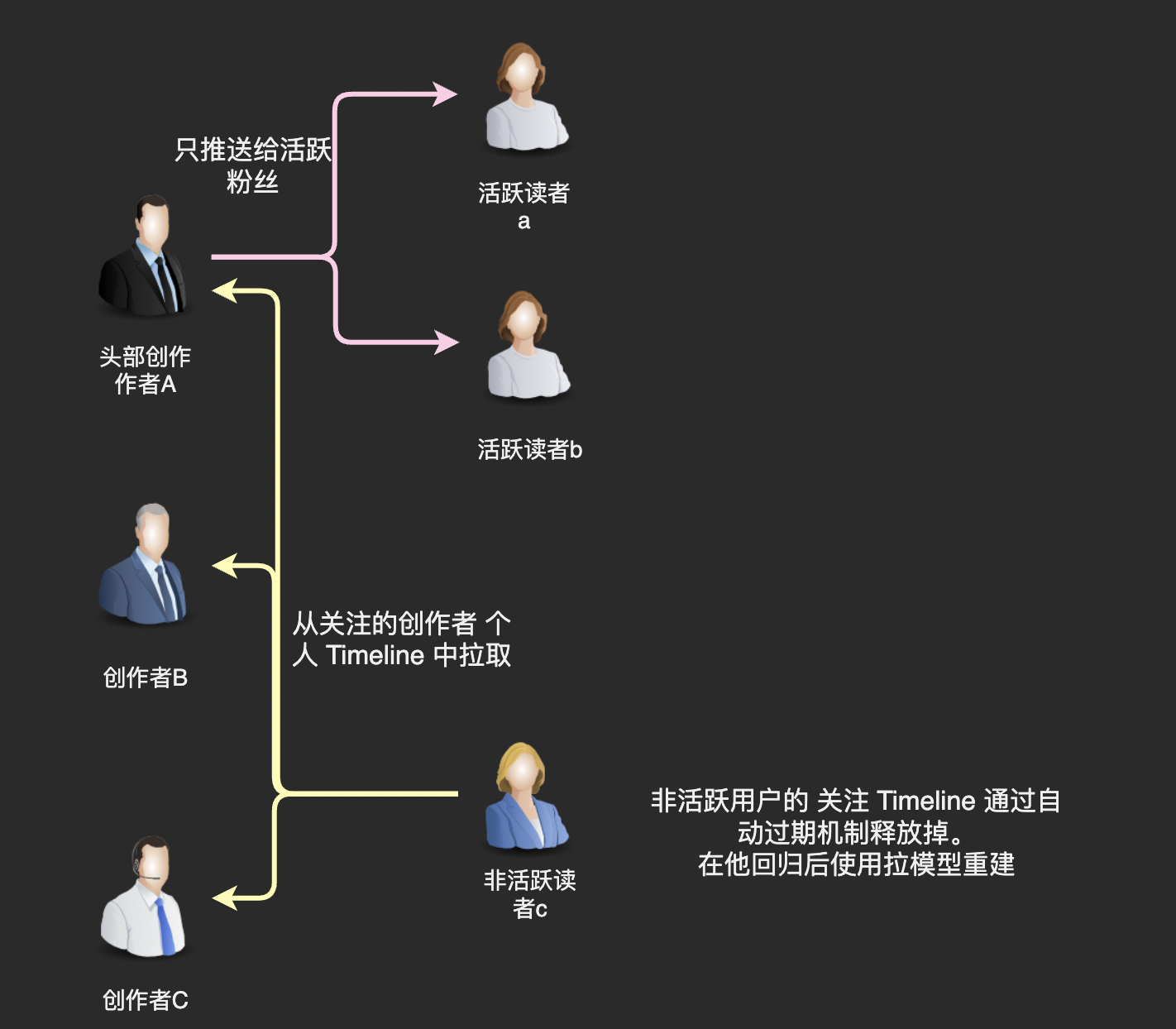
为了平衡优缺点,建议采用混合模型:在线用户推,离线用户拉。这是一种常见的优化策略(如 Twitter/Facebook 的早期设计)。
核心思路:
- 在线用户(Active Users):使用推模型。假设用户在线(通过 WebSocket/长轮询检测),当关注的人发帖时,实时推送给在线粉丝的 Feed。这样确保活跃用户看到实时更新。
- 离线用户(Inactive Users):使用拉模型。用户上线时,从关注列表拉取最近帖子,合并生成 Feed,并缓存起来。后续如果用户保持在线,再切换到推模式。
- 阈值切换:为每个发帖用户设置粉丝阈值(e.g., 如果粉丝 > 1000,用拉模型;否则用推)。但重点是基于用户在线状态动态切换。
- 为什么这样结合?
- 减少写放大:只推给在线粉丝(通常远少于总粉丝)。
- 提升实时性:在线用户即时看到更新。
- 节省资源:离线用户不消耗推送资源,上线时一次性拉取。
- 扩展性:高峰期在线用户有限,拉模型处理离线用户峰值。
流程示例:
- 用户 A 发帖:存储到 A's 帖子表。
- 查询 A's 在线粉丝列表(用 Redis 维护在线状态)。
- 对在线粉丝:推模型 - 将帖子 ID 推入每个粉丝的个人 Feed List (Redis)。
- 用户 B 上线:如果 Feed 缓存失效,用拉模型 - 从 B 的关注列表拉取每个关注者的最近 N 条帖子,合并排序,生成 Feed 并缓存。
- B 保持在线:后续切换到推模式,监听推送。
使用Redis作为高速缓存层,使用 Cassandra 等分布式数据库作为第二层缓存,结合 MySQL 作为持久层,设计多层缓存。
Redis SortedSet 一级缓存
- 用途:存储在线用户的 Timeline(Feed 流)。
- 结构:
- Key:
timeline:user_id(每个用户一个 SortedSet)。 - Score:Feed 的时间戳(或自增 ID),用于按时间倒序排序。
- Member:Feed ID(动态唯一标识)。
- 过期机制:
- 设置 TTL(例如 7 天),不活跃用户缓存自动清除。
- 每次用户活跃(发布动态、查看 Feed)刷新 TTL。
- 容量管理:
- 限制 SortedSet 大小(例如 1000 条),老数据移除或迁移至 Cassandra。
Cassandra 二级缓存
- 用途:存储月活跃用户的 Timeline 数据,扩展 Redis 容量。
- 表设计:
CREATE TABLE user_timeline (
user_id bigint,
feed_id bigint,
timestamp bigint,
PRIMARY KEY (user_id, timestamp)
) WITH CLUSTERING ORDER BY (timestamp DESC);
- 特点:
- 高吞吐量,适合写密集场景。
- 按时间倒序存储,便于分页查询。
- 使用场景:
- Redis 缓存不足时,将不活跃用户的 Timeline 迁移至 Cassandra。
- 离线用户访问时,从 Cassandra 或数据库拉取数据。
数据库(例如 MySQL/PostgreSQL)
- 用途:持久化存储所有动态数据和关注关系。
- 表结构:
feeds:存储动态(feed_id, user_id, content, timestamp)。follows:存储关注关系(follower_id, followee_id)。
- 用途:
- 拉模型时查询关注对象的动态。
- 冷数据存储(不活跃用户的动态)。

