关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
分布式锁是分布式系统中一个非常重要的基础组件,它的设计理念源于单机环境下的互斥锁,但需要解决分布式环境下的特殊问题。
在分布式系统中,由于服务部署在多台机器上,传统的单机锁机制无法满足需求。分布式锁需要解决的核心问题包括互斥性、防死锁、高性能和高可用性。互斥性确保在任何时刻,只能有一个客户端持有锁;防死锁机制确保即使持有锁的客户端崩溃,锁也能被释放;高性能要求锁的获取和释放操作要足够快;高可用性则要求锁服务本身不能成为单点故障。
Redis 实现分布式锁的核心原理是利用其单线程特性和原子操作。通过 SET 命令的 NX 选项,我们可以实现互斥性;通过设置过期时间,我们可以防止死锁;通过 Redis 的高性能特性,我们可以保证锁操作的效率。
下面,让我们可以一步一步用Redis来实现一个相对完备的分布式锁。
Redis的SETNX命令是实现分布式锁最简单直接的方式。其基本语法为:SETNX key value,执行时:
当key不存在时,设置键值并返回1(加锁成功)
当key已存在时,不做任何操作并返回0(加锁失败)
利用这个特性,我们可以实现基本的加锁逻辑:
通过SETNX尝试获取锁(设置唯一标识)
业务处理期间,其他服务无法重复获取锁
业务完成后,使用DEL命令释放锁
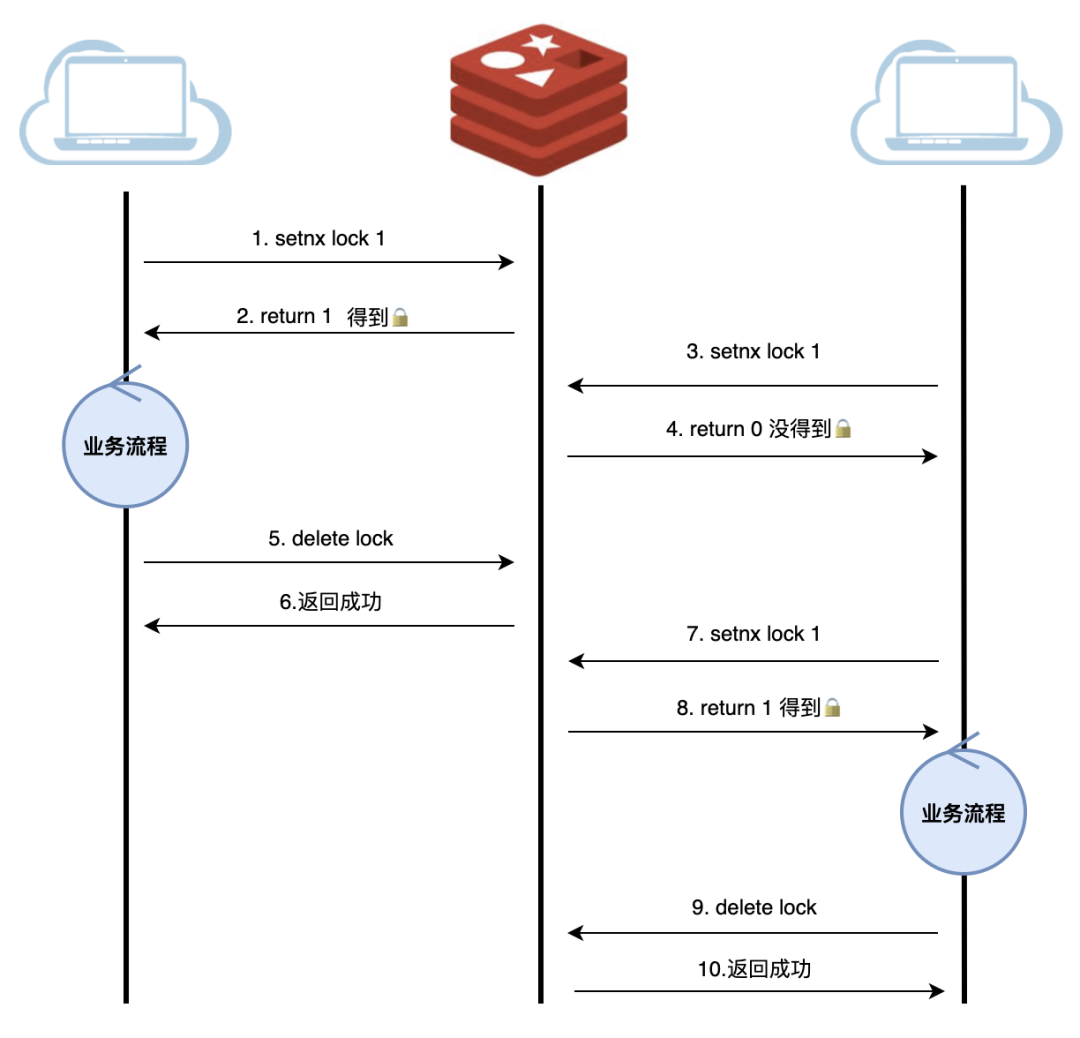
最简实现存在一个致命缺陷:如果服务在获取锁后突然崩溃,这把锁就会永远无法释放,就像沉入大海的石头,再也找不回来了。
为了解决这个问题,我们需要引入超时机制。Redis提供了EXPIRE命令来设置键的过期时间。但问题在于,SETNX和EXPIRE是两个独立操作,如果在SETNX成功后服务崩溃,EXPIRE还没来得及执行,这把锁依然会永久存在。
很自然地,我们会思考:是否存在一个原子操作,能同时完成设置值和过期时间?
答案是肯定的。Redis早已考虑到这种使用场景,提供了更完善的命令语法:
SET key value NX EX seconds其中:1.NX表示"不存在才设置"(即SETNX的特性)2.EX表示设置过期时间(单位为秒)3.seconds就是具体的过期时长。 这个原子操作完美解决了我们面临的问题。
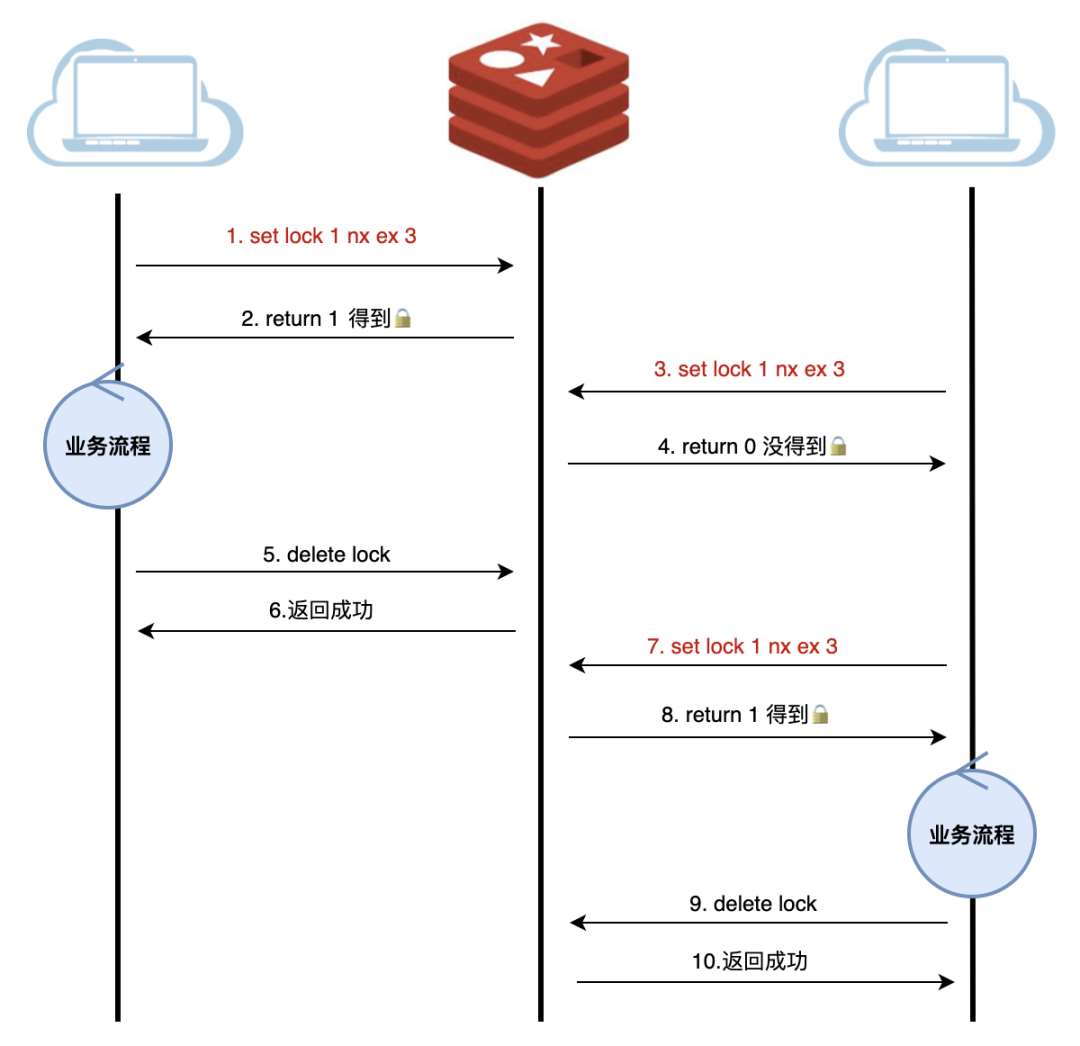
我们来试想一下如下场景:服务A获取了锁,由于业务流程比较长,或者网络延迟、GC卡顿等原因,导致锁过期,而业务还会继续进行。这时候,业务B已经拿到了锁,准备去执行,这个时候服务A恢复过来并做完了业务,就会释放锁,而B却还在继续执行。
在真实的分布式环境中,往往存在数十个服务实例同时竞争同一把锁的情况。此时若不加防范,上述锁误释放的问题发生概率将大幅提升,导致多个竞争者可能同时访问临界资源,使得分布式锁完全失去了其应有的互斥作用。
深入分析这个问题,我们会发现核心症结在于:当前的锁实现允许竞争者释放其他进程持有的锁。这种设计在异常情况下会带来严重的数据一致性问题。因此,我们需要确立一个基本原则:分布式锁必须严格遵循**"谁申请谁释放"**的机制,确保锁具有明确的归属关系。
这就引出了分布式锁的一个重要特性:锁必须携带持有者标识。每个服务实例在获取锁时,需要将自己的唯一标识(如UUID、实例ID等)作为value存入锁中。在释放锁时,必须验证当前实例确实是锁的持有者,从而避免误删其他实例持有的锁。这种机制不仅能解决锁的安全释放问题,也为锁的可观测性提供了基础。
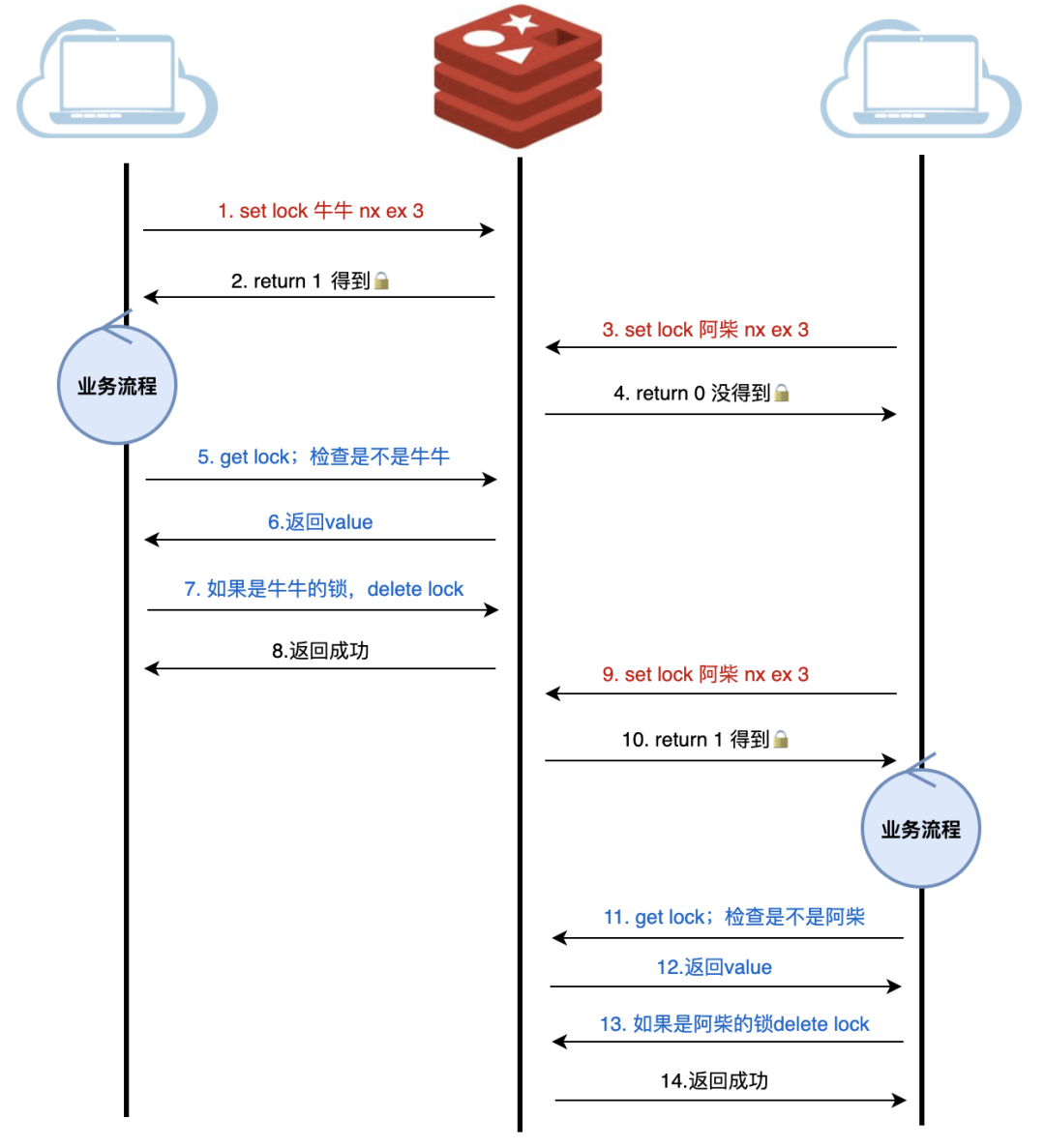
加入 owner 机制的版本看似完善,实则仍暗藏隐患。让我们仔细审视完整的加锁-释放流程:获取锁 → 执行业务 → 验证锁归属 → 释放锁。问题恰恰出在最后的验证和释放环节——这两个操作并非原子性执行。
想象这样一个场景:当服务完成业务逻辑后,虽然验证时锁仍归属自己,但在执行删除操作的瞬间,锁可能已因过期被其他竞争者获取。这种极端情况下,就会导致误删他人持有的锁。
Redis 原生确实没有提供这种复合操作的原子性保证。但别急,Redis 提供了一个绝佳的解决方案——Lua 脚本。通过将验证和删除操作封装在 Lua 脚本中执行,我们就能确保这两个操作的原子性,完美解决这个潜在的竞态条件问题。
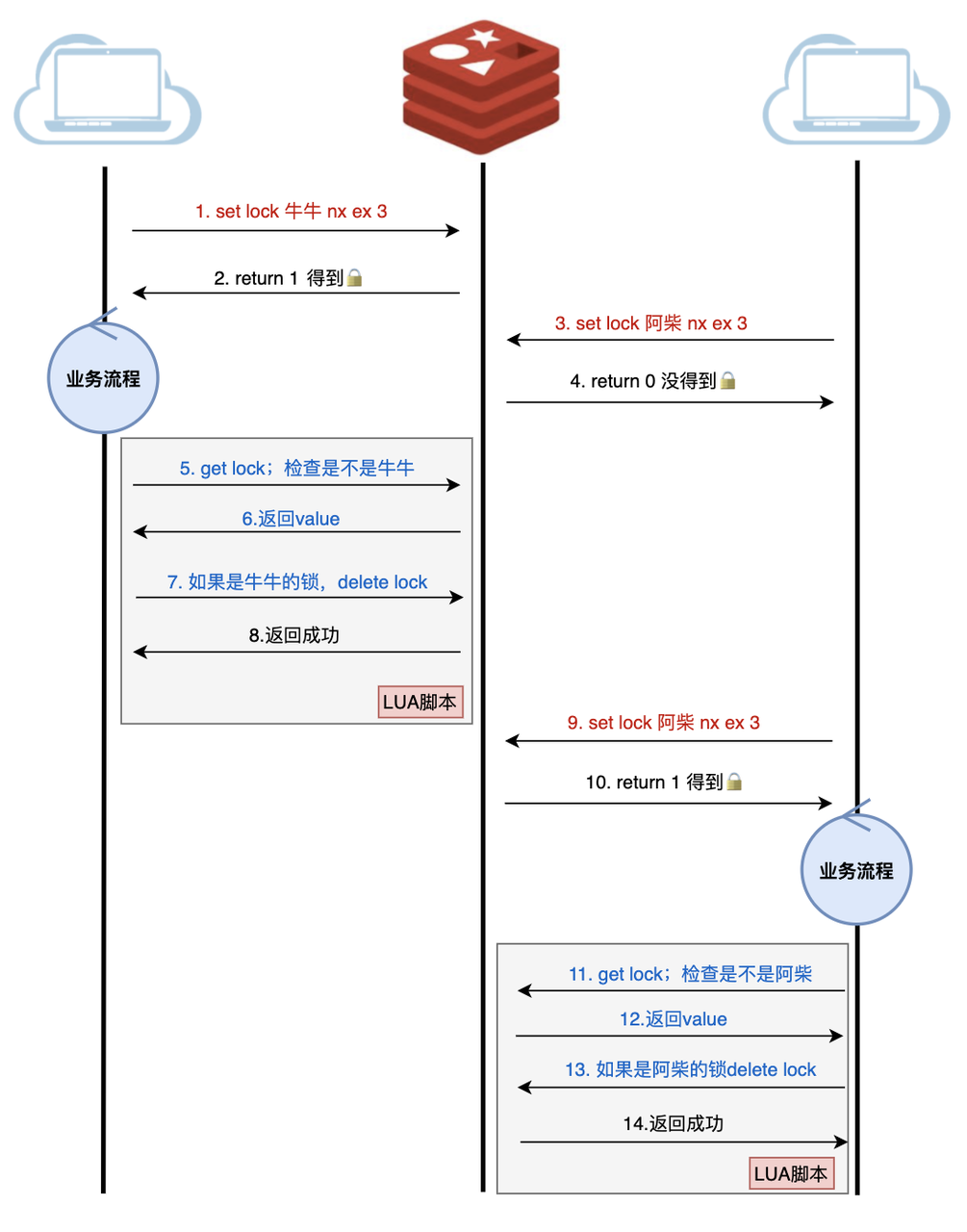
最后让我们看看具体的示例lua实现,这段代码展示了加锁和解锁的核心实现,包括互斥性检查和原子性保证。
-- 加锁时设置 owner
if redis.call("set", KEYS[1], ARGV[1], "NX", "PX", ARGV[2]) then
-- 设置 owner 信息
redis.call("hset", KEYS[1] .. ":owner", "id", ARGV[1])
redis.call("hset", KEYS[1] .. ":owner", "time", ARGV[2])
return 1
else
return 0
end
-- 解锁时验证 owner
if redis.call("get", KEYS[1]) == ARGV[1] then
-- 验证 owner 信息
local owner = redis.call("hgetall", KEYS[1] .. ":owner")
if owner and owner.id == ARGV[1] then
redis.call("del", KEYS[1])
redis.call("del", KEYS[1] .. ":owner")
return 1
end
end
return 0Redis 分布式锁的优势非常突出。首先,Redis 采用内存操作,响应速度极快,单线程模型也避免了锁竞争,非常适合对性能要求高的系统。其次,Redis 的命令简单易用,支持多种客户端,集成和维护都很方便,开发成本也较低。再者,Redis 在业界有着广泛的应用,社区支持丰富,实践经验充足,遇到问题时也有很多成熟的解决方案。除此之外,Redis 分布式锁还支持自动过期、锁的续期、分布式部署和高可用等功能,能够满足大多数业务场景的需求。
Redis 分布式锁的缺点需要从多个维度来分析。首先,在一致性方面存在明显问题,由于主从复制机制可能导致数据不一致,在网络分区的情况下甚至可能出现多个客户端同时持有锁的情况,这对于要求强一致性的业务场景来说是不可接受的。
其次,Redis 分布式锁的可用性完全依赖于 Redis 服务本身。一旦 Redis 出现故障,锁服务就会不可用,虽然可以通过主从复制和哨兵机制来提高可用性,但这也增加了系统的复杂度和维护成本。此外,Redis 分布式锁在功能上也有一定限制,比如不支持公平锁,锁的续期需要额外实现,也不支持锁的优先级等高级特性。
在运维方面,使用 Redis 分布式锁需要维护 Redis 集群,需要监控锁的状态,需要处理各种异常情况,这些都会带来额外的运维成本。特别是在大规模集群中,这些问题会更加突出。
设置合理的超时时间是 Redis 分布式锁实现中的一个关键问题。首先需要从业务角度进行评估。
包括识别业务逻辑中最耗时的操作、计算业务最坏情况下的处理时间、以及必要的缓冲时间。这些因素直接影响到锁的超时时间设置,如果设置过短可能导致业务被中断,设置过长则可能影响其他业务的执行。典型例子:简单查询:500ms-1s;复杂交易:3-5s;批量处理:10-30s
其次,网络因素也是必须考虑的重要方面。在实际部署中,我们需要考虑网络延迟、网络抖动、跨机房延迟等因素,这些都会影响到锁的实际可用时间。特别是在分布式系统中,网络状况往往不稳定,需要预留足够的缓冲时间。比如:同机房(1-2ms),跨机房(10-50ms),跨地域(100-300ms),并做2-3倍预留。
系统因素同样不可忽视。在高负载情况下,系统响应时间可能会变长,GC 暂停也会影响业务执行时间,资源竞争也会导致处理延迟。这些因素都需要在设置超时时间时考虑进去。
最后,安全因素也是必须考虑的。我们需要为异常情况、故障恢复、数据一致性等问题预留足够的缓冲时间,确保系统在各种情况下都能正常运行。
让我们可以用一段示例代码,来理解超时时间的计算:
// 超时时间计算
int calculateTimeout(LockConfig *config) {
// 业务执行时间
int business_time = config->business_time;
// 网络延迟
int network_delay = config->network_delay;
// 系统缓冲
int system_buffer = config->system_buffer;
// 安全缓冲
int safety_buffer = config->safety_buffer;
// 计算总超时时间
return business_time + network_delay + system_buffer + safety_buffer;
}可重入锁的实现需要考虑多个方面。首先,我们需要维护一个计数器来记录锁的重入次数。在加锁时,如果锁不存在,我们就创建锁并设置计数为1;如果锁已存在且属于当前客户端,我们就增加计数;如果锁属于其他客户端,则加锁失败。在解锁时,我们需要减少计数,当计数为0时才真正释放锁。
为了保证操作的原子性,我们需要使用 Lua 脚本。加锁和解锁操作必须是原子的,计数器的操作也必须是原子的,这样才能避免并发问题。在实现过程中,我们还需要考虑锁的续期问题,特别是对于长时间运行的任务,需要确保锁不会因为过期而被其他客户端获取。
异常处理也是实现可重入锁时需要考虑的重要问题。我们需要处理加锁失败、解锁失败、计数器异常等各种情况,确保数据的一致性。同时,我们还需要考虑锁的监控和维护,方便问题排查和系统维护。
让我们看看可重入锁的具体实现:
-- 加锁脚本
if redis.call("set", KEYS[1], ARGV[1], "NX", "PX", ARGV[2]) then
-- 设置重入计数
redis.call("hset", KEYS[1] .. ":count", ARGV[1], 1)
return 1
elseif redis.call("get", KEYS[1]) == ARGV[1] then
-- 增加重入计数
redis.call("hincrby", KEYS[1] .. ":count", ARGV[1], 1)
return 1
else
return 0
end
-- 解锁脚本
if redis.call("get", KEYS[1]) == ARGV[1] then
-- 减少重入计数
local count = redis.call("hincrby", KEYS[1] .. ":count", ARGV[1], -1)
if count == 0 then
-- 释放锁
redis.call("del", KEYS[1])
redis.call("del", KEYS[1] .. ":count")
end
return 1
else
return 0
end这段代码展示了可重入锁的核心实现,包括加锁和解锁操作,我们来解析一下:
核心参数设计
该分布式锁实现需要三个关键参数:锁键名(KEYS[1])作为分布式锁的唯一标识,通常采用业务前缀+资源ID的命名方式;锁值(ARGV[1])使用客户端唯一标识,建议采用UUID+线程ID的组合形式;锁过期时间(ARGV[2])以毫秒为单位设置,需要根据业务操作耗时合理设定,既不能过短导致业务未完成就自动释放,也不宜过长影响系统可用性。
加锁执行流程
首次加锁时,采用SET命令配合NX和PX参数实现原子性操作,NX确保只有锁不存在时才能设置成功,PX设置自动过期时间防止死锁。加锁成功后,会在附属的哈希表中初始化重入计数器为1。当同一客户端再次请求加锁时,系统会检查锁持有人身份,确认一致后通过HINCRBY命令递增重入计数,实现可重入功能。若锁已被其他客户端持有,则立即返回加锁失败。
解锁执行机制
解锁时需要严格验证锁持有人身份,只有匹配的客户端才能执行解锁操作。每次解锁会将重入计数器减1,当计数器归零时才真正释放锁资源,同时清理计数器哈希表。这种设计确保了锁的安全释放,避免出现误删他人持有的锁的情况。整个过程保持原子性执行,有效解决了并发环境下的竞态条件问题。
关键特性保障
该实现方案具有多重保障机制:通过NX参数和Lua脚本保证操作的原子性;设置合理的过期时间预防死锁;采用客户端唯一标识确保锁的安全持有;通过重入计数器支持同一客户端的多次加锁需求。这些特性共同构成了一个健壮的分布式锁实现,能够满足大多数分布式场景下的并发控制需求。实际使用时需要注意合理设置过期时间,对于长时间任务建议配合看门狗机制实现锁的自动续期。
分布式锁的实现方案有很多,每种方案都有其特点和适用场景。
基于数据库的分布式锁方案主要通过两种技术路径实现:一种是利用唯一索引约束特性,通过插入特定记录来竞争锁;另一种是采用乐观锁机制,基于版本号或条件更新实现锁状态变更。这类方案最突出的优势在于其"开箱即用"的特性——无需引入Redis、ZooKeeper等额外中间件,直接复用现有数据库基础设施即可快速实现分布式锁功能。同时,由于数据库本身具备完整的ACID事务特性,这种方案天然就能提供强一致性保证,特别适合对数据一致性要求严格的场景。
然而,数据库方案的局限性也十分明显。在性能方面,受限于数据库的行级锁机制和事务开销,其吞吐量存在明显天花板,在高并发场景下QPS很难突破2000。更严重的是,长时间持有锁会导致数据库连接持续占用,极易造成连接池耗尽,进而引发系统级联故障。此外,如果缺乏完善的超时管理机制,一旦出现客户端异常退出等情况,很容易导致死锁问题,需要额外的监控和清理策略来应对。
正因如此,基于数据库的分布式锁方案通常仅推荐在特定场景下使用:一类是低频的管理类操作,如系统配置变更、定时任务触发等;另一类是对性能要求不高但需要强一致性的内部系统,如某些后台批处理系统。在这些场景中,数据库方案能够以最小的架构变更成本,提供可靠的分布式锁服务。但对于高并发、低延迟的业务场景,如电商秒杀、实时交易等,则需要考虑性能更高的替代方案。
Redis分布式锁方案主要基于其原生的SETNX命令配合EXPIRE实现,通过将这两个命令封装为原子操作来确保锁的安全获取,通过LUA脚本再来安全解锁。这种实现方式能够充分发挥Redis内存数据库的特性,提供惊人的性能表现——在单节点部署下,QPS轻松突破10万大关,完全能够满足最严苛的高并发场景需求。同时,得益于Redis在业界的广泛应用,围绕分布式锁已经形成了成熟的客户端库生态,比如Java中的Redisson、Python中的redis-py等,这些库都提供了开箱即用的高级特性支持。
不过,Redis方案也存在一些固有的局限性。首先是对系统时钟的强依赖,如果服务器时间出现不同步,可能导致锁提前失效或延迟释放。更严重的是脑裂问题,在主从切换场景下,新的主节点可能丢失部分未同步的锁信息,导致多个客户端同时持有同一把锁。为了应对这些问题,通常需要实现复杂的看门狗机制来定期续约锁,增加了实现的复杂度。
正是由于这些特性,Redis分布式锁特别适合两类业务场景:一类是电商秒杀、票务抢购等瞬时高并发场景,这类业务对性能要求极高,且可以容忍极短时间内的数据不一致;另一类是对响应延迟极为敏感的业务系统,比如实时竞价、游戏匹配等,这些场景下毫秒级的延迟都可能影响用户体验。在这些业务中,Redis分布式锁能够在性能与一致性之间取得最佳平衡。
ZooKeeper作为分布式协调服务的标杆,其分布式锁实现基于临时顺序节点和Watch通知机制,通过创建EPHEMERAL_SEQUENTIAL节点实现锁的获取,利用Watch机制监听前序节点的删除事件来实现锁的等待和获取。这种设计天然具备强一致性保障,完全遵循ZAB协议的顺序一致性模型,确保所有节点看到的锁状态完全一致。
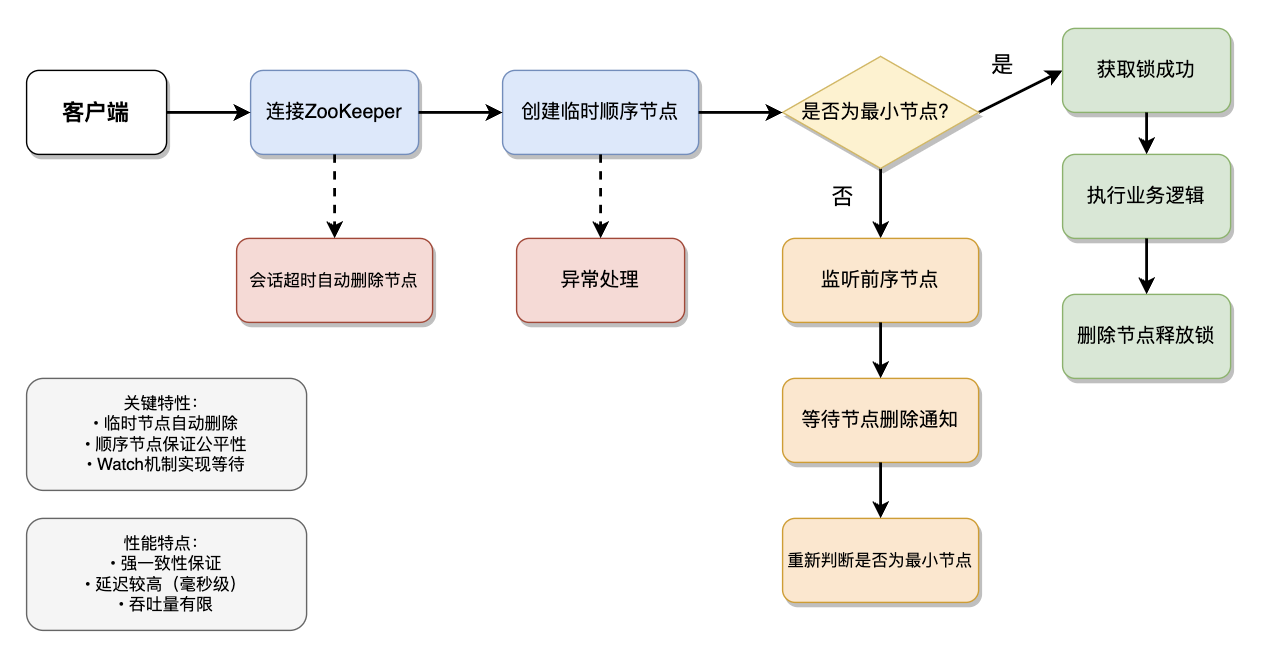
其独特优势在于会话断开时的自动释放机制,客户端与ZK服务器连接中断后,其创建的临时节点会自动删除,避免了死锁风险。同时,顺序节点的特性保证了锁获取的公平性,严格遵循先来先服务原则。然而这些优势的代价是性能受限,由于需要维持强一致性和顺序性,写操作需要集群多数节点确认,导致吞吐量通常不超过5000 QPS,平均延迟在毫秒级别,且随着集群规模扩大而增加。
此外,ZK集群需要专门的运维团队进行管理,包括磁盘I/O优化、JVM调优和定期维护等。这使得它特别适合金融领域的支付清算、证券交易等对一致性要求极高的场景,以及已经深度使用ZK作为协调服务的系统架构。
Etcd作为CNCF毕业项目,其分布式锁实现基于KV存储配合Lease租约机制,通过Put操作配合Lease实现锁的自动过期,利用事务CAS操作保证原子性。
底层依赖Raft共识算法在保证强一致性的同时,相比ZK具有更好的性能表现,典型吞吐可达30K QPS,延迟控制在毫秒级。
其接口采用高效的gRPC协议,支持长连接和流式传输,特别适合云原生环境。Etcd的Lease机制设计精巧,客户端可以定期刷新租约实现锁续期,同时服务端会主动检测客户端存活状态,在客户端失联时自动释放锁资源。但Etcd的部署运维复杂度较高,生产环境需要至少3节点集群部署,对网络分区敏感,需要专业的监控系统跟踪Raft指标、存储性能和节点健康状态。这使得它成为Kubernetes控制平面、服务网格(如Istio)配置中心等云原生基础设施的首选,也是需要强一致性又对性能有一定要求的分布式系统的理想选择。
Consul的分布式锁实现基于其KV存储和Session会话机制,其最大特点是深度集成了服务发现和健康检查功能,锁可以与服务实例的生命周期自动绑定,当服务实例故障时,关联的Session会自动失效从而释放锁资源。Consul原生支持多数据中心部署,锁信息可以通过WAN Gossip协议跨数据中心同步,非常适合全球化部署的业务系统。
在性能方面,Consul采用Raft协议但优化了提交过程,典型吞吐在3000-5000 QPS之间,默认配置下保证最终一致性,也可以通过强一致性读模式提升一致性级别。不过Consul的锁API相对简单,缺乏原生可重入等高级特性。这使得它特别适合已经采用Consul作为服务注册中心的微服务架构,以及需要跨地域协同的分布式系统,如多活部署的订单系统、全球配置管理等场景。
选型需综合考量性能、一致性、部署复杂度等因素,高频场景推荐Redis,强一致需求选择ZooKeeper或Etcd,多数据中心考虑Consul。实践中可采用混合策略,关键事务用强一致锁,高频读用Redis乐观锁。
| 维度 | 数据库 | Redis | ZooKeeper | Etcd | Consul |
|---|---|---|---|---|---|
| 性能(QPS) | 低(2k) | 高(100k) | 低(5k) | 中(30k) | 低(5k) |
| 一致性 | 强 | 最终一致性 | 强 | 强 | 最终一致性 |
| 部署复杂度 | 低 | 中 | 高 | 高 | 中 |
| 功能扩展性 | 弱 | 强 | 中 | 中 | 强 |
| 适用场景 | 低频 | 高频 | 强一致 | 云原生 | 多DC |

