关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
本地缓存库的核心是一个读多写少的线程安全的 Map 结构。除了基本的增删改查操作之外,还需要实现过期策略、容量控制和淘汰策略。
首先,为实现并发安全的 map,可以采用分段锁的方式。将缓存分成多个分片,每个分片使用独立的读写锁。这样可以降低锁竞争,提高并发性能。相比全局锁,分段锁能让不同分片的读写操作并行执行,适合高并发场景。
此外,还需要考虑缓存的过期机制。可以通过记录每个键的过期时间,结合惰性删除和定期清理来管理过期数据。惰性删除在访问键时检查是否过期,定期清理则通过后台协程扫描部分分片,删除过期键值对,以平衡性能和内存使用。
对于缓存淘汰策略,LRU(最近最少使用)是一个常见选择。参考 Redis 的思路,可以避免使用传统链表实现 LRU 时需要加锁的问题。Redis 使用近似 LRU 算法,通过随机采样和时间戳比较来决定淘汰哪些键值对。这种方法无需维护复杂的数据结构,减少锁开销,同时在大多数场景下能提供接近 LRU 的效果,兼顾性能和准确性。
如果使用 Go 语言实现,还需要考虑 GC 效率问题。包含指针的大 map 会导致垃圾回收性能下降。参考 bigcache 的设计,可以通过将数据存储为字节数组(byte slices)而不是直接使用指针来减少 GC 压力。
下面我们详细展开来讲解。
分段锁的核心思路是将缓存数据分成多个分片(shards),每个分片使用独立的读写锁(sync.RWMutex)管理,降低锁竞争,提高并发性能。每个分片存储一部分键值对,键通过哈希函数映射到对应的分片。
设计思路:
RLock),允许多个 goroutine 并发读取;写操作使用写锁(Lock),确保同一分片的写操作互斥。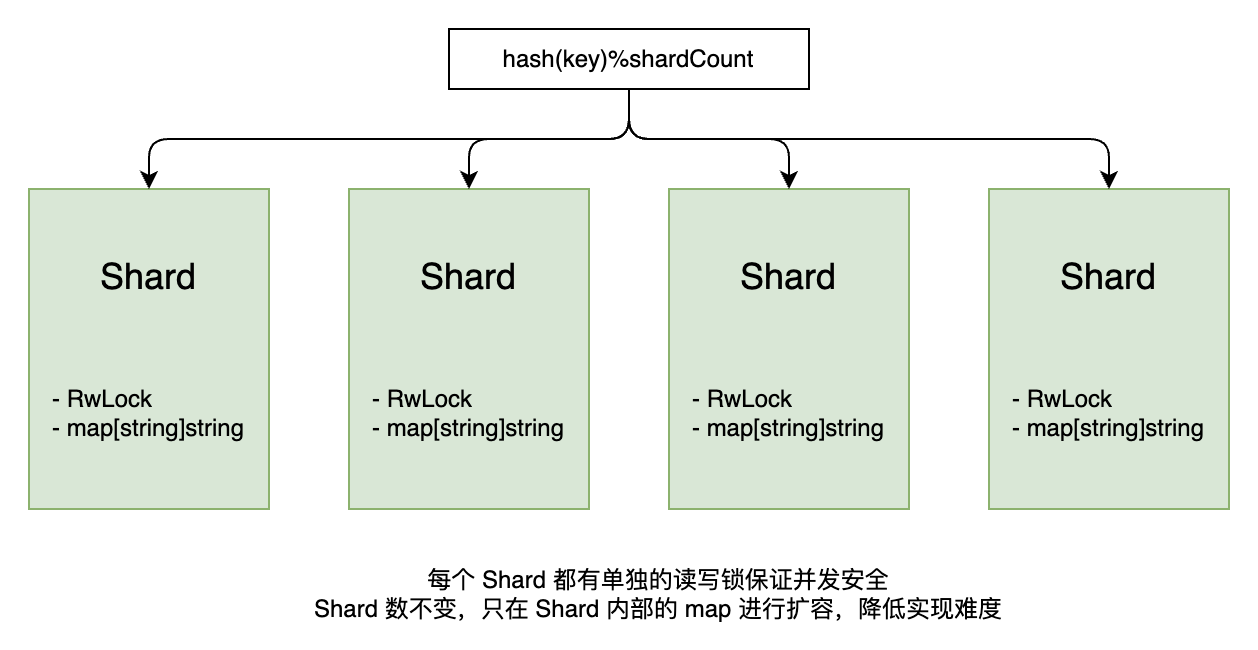
// Shard 代表一个分片,包含 map 和读写锁
type Shard struct {
sync.RWMutex
data map[string]interface{}
}
// Cache 缓存结构,包含多个分片
type Cache struct {
shards []*Shard
shardCount uint32
}
// NewCache 创建缓存,初始化分片
func NewCache(shardCount uint32) *Cache {
cache := &Cache{
shards: make([]*Shard, shardCount),
shardCount: shardCount,
}
for i := uint32(0); i < shardCount; i++ {
cache.shards[i] = &Shard{
data: make(map[string]interface{}),
}
}
return cache
}
// getShard 根据键计算分片索引
func (c *Cache) getShard(key string) *Shard {
hasher := fnv.New32()
hasher.Write([]byte(key))
return c.shards[hasher.Sum32()%c.shardCount]
}
// Set 写入键值对
func (c *Cache) Set(key string, value interface{}) {
shard := c.getShard(key)
shard.Lock()
defer shard.Unlock()
shard.data[key] = value
}设计思路:
// Get 读取键值对,包含惰性删除
func (c *Cache) Get(key string) (interface{}, bool) {
shard := c.getShard(key)
shard.Lock() // 使用写锁以便删除过期键
defer shard.Unlock()
item, exists := shard.data[key]
if !exists {
return nil, false
}
// 惰性删除:检查是否过期
if item.ttl > 0 && time.Since(item.createdAt) > item.ttl {
delete(shard.data, key)
return nil, false
}
return item.value, true
}
// cleanup 定期清理过期数据
func (c *Cache) cleanup() {
// 随机选择一个分片
shardIndex := rand.Intn(int(c.shardCount))
shard := c.shards[shardIndex]
const maxKeysToCheck = 1000 // 每次清理最多检查的键数
shard.Lock()
defer shard.Unlock()
// 收集需要检查的键
keys := make([]string, 0, maxKeysToCheck)
for key := range shard.data {
keys = append(keys, key)
if len(keys) >= maxKeysToCheck {
break
}
}
// 检查并删除过期键
for _, key := range keys {
item, exists := shard.data[key]
if exists && item.ttl > 0 && time.Since(item.createdAt) > item.ttl {
delete(shard.data, key)
}
}
}我们熟悉的 LRU 算法实现是通过 HashMap + 链表 实现的,在本地缓存库中每次 Get/Put 操作都需要对这个全局链表加互斥锁,极大的拖累了性能。所以在生产环境中使用的缓存更多的采用近似 LRU 算法。
以 Redis 为例,每个键对应的 redisObject 结构体(存储键值对元数据)都包含一个lru字段,用于记录键的 “最后一次访问时间”。当键被访问(如GET、SET等操作)时,Redis 会更新该键redisObject中的lru字段,这个更新是O (1) 操作,无需维护链表或其他复杂结构,开销极低。
当 Redis 内存达到maxmemory配置时,会触发淘汰逻辑。Redis 会从符合条件的键(如volatile-lru只选带expire的键)中随机采样 N 个键(N 由maxmemory-samples配置,默认 5 个,可调整)加入候选淘汰池。然后对比候选池中所有键的lru字段,找到最旧的键将其作为本轮淘汰的目标。
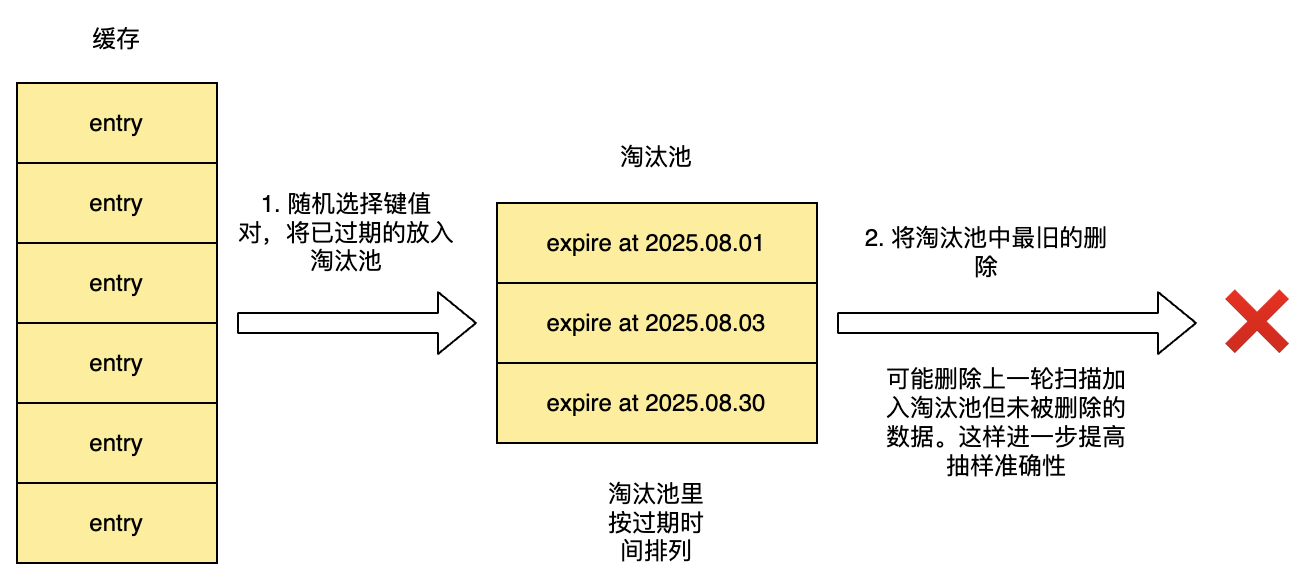
在没有淘汰池的早期版本(Redis 3.0 之前),Redis 会直接随机采样N个键,并从这N个键中淘汰最旧的一个。这种方式存在明显缺陷:单次采样可能漏掉全局最旧的键,导致淘汰的并非真正最该被淘汰的键。
淘汰池的引入解决了这个问题:它记住了历史采样中发现的旧键,避免单次采样的随机性导致漏掉全局最旧的键。例如:第一次采样可能没抽到最旧的键,但第二次采样抽到后,会被存入淘汰池,后续淘汰时就有机会被选中。
// 在 cleanup 函数最后加入这段淘汰逻辑即可:
func (c *Cache) lruEvict(shard *Shard) {
if len(shard.data) > maxItems {
// 随机采样
sampleKeys := make([]string, 0, sampleSize)
if len(keys) > sampleSize {
rand.Shuffle(len(keys), func(i, j int) { keys[i], keys[j] = keys[j], keys[i] })
sampleKeys = keys[:min(sampleSize, len(keys))]
} else {
sampleKeys = keys
}
// 找到采样中最旧的键
var oldestKey string
var oldestTime time.Time
for _, key := range sampleKeys {
item, exists := shard.data[key]
if exists && (oldestKey == "" || item.lastAccess.Before(oldestTime)) {
oldestKey = key
oldestTime = item.lastAccess
}
}
// 删除最旧的键
if oldestKey != "" {
delete(shard.data, oldestKey)
}
}
}当使用一个包含大量指针的大 map 时(例如map[string]*MyStruct),会触发两个关键问题:
这会导致 GC 性能急剧下降
这种情况对于一个需要维护大量对象的本地缓存而言是致命的。bigcache 采用的思路是使用二进制数据代替对象指针来减少 GC 压力,并通过手动维护内存池的方法来减少内存分配的压力。
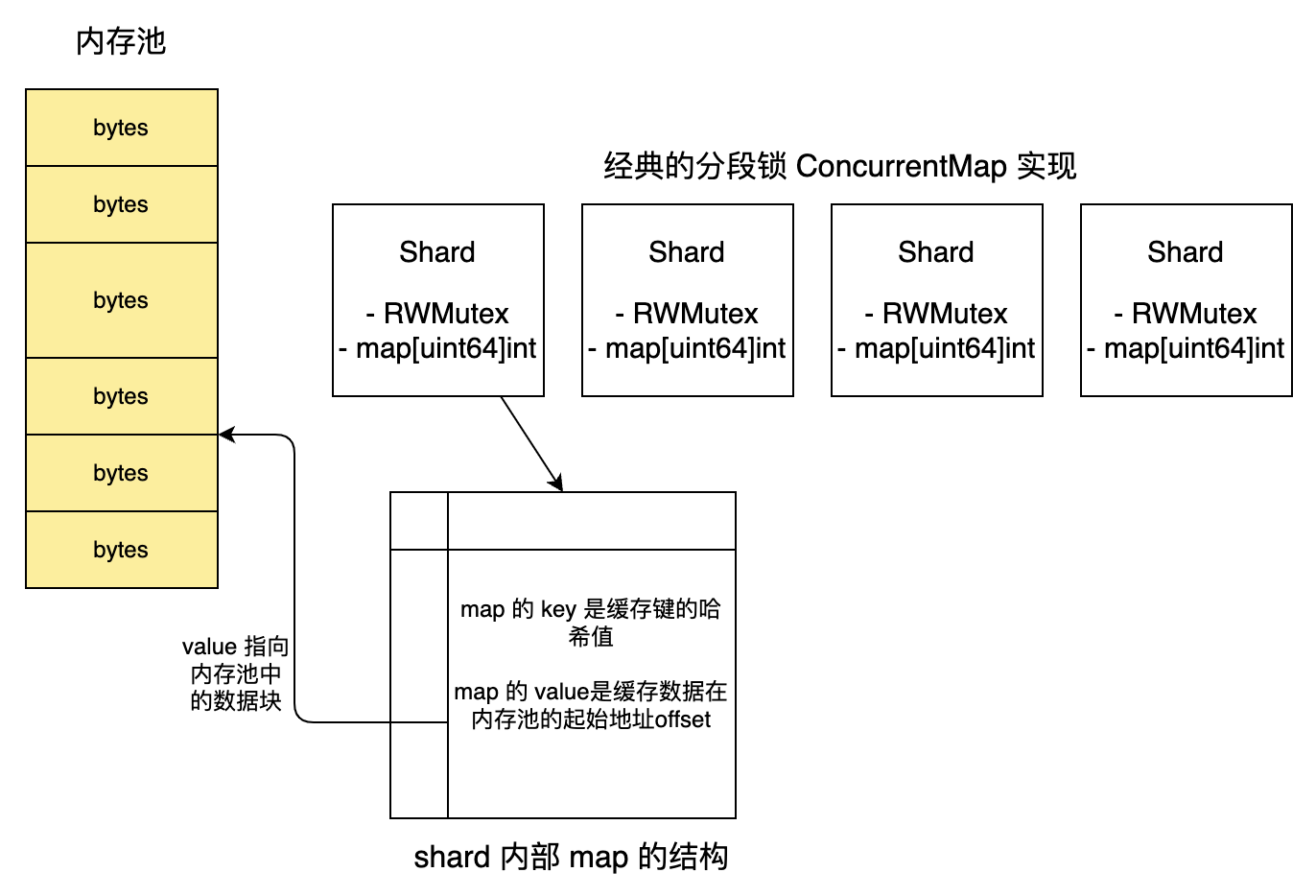
这种方法的局限性在于可能需要频繁进行序列化 / 反序列化操作,反而可能导致性能更低。

