关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
设计分布式ID生成算法,需要结合分布式系统的特性(如多节点、高并发、网络分区等)和业务需求(如ID有序性、携带业务信息等),核心是满足以下关键特性:
唯一性:在整个分布式系统中绝对不重复,这是最基础的要求。
有序性:部分业务需要ID具备递增性(如用于数据库索引、排序场景),至少保证“趋势递增”。
高性能:生成ID的过程不能成为系统瓶颈,需支持高并发(每秒数万级甚至更高)。
高可用:生成ID的服务不能单点故障,需保证分布式环境下的可用性。
安全性:避免ID泄露业务敏感信息(如用户量、订单量),或被轻易猜测(如纯自增ID)。
可扩展性:支持集群节点扩容,新增节点后仍能正常生成ID。
下面,我们来看几种常见方案,并对它们做优缺点分析。
1位符号位(固定0,保证正数) + 41位时间戳(毫秒级,可用约69年) + 10位机器ID(支持1024个节点) + 12位序列号(每毫秒最多生成4096个ID)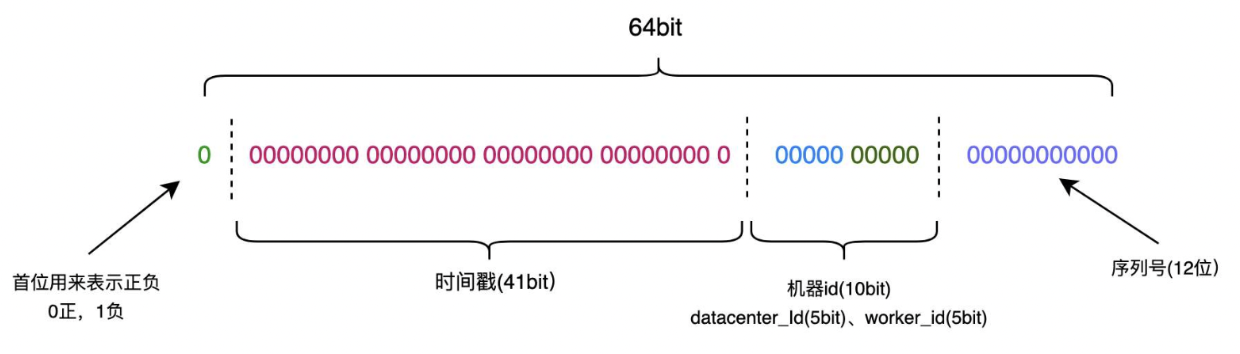
该算法的优点十分鲜明:一是趋势有序—— 基于时间戳递增生成 ID,虽非严格连续,但整体呈时序趋势,能适配数据库索引优化,减少索引碎片,提升查询性能;二是高性能—— 完全在本地生成 ID,无需网络请求或依赖外部服务,避免网络开销,单节点每秒可生成数十万级 ID,满足高并发场景;三是灵活性强—— 可根据业务需求调整各字段位数,比如业务节点较少时缩减机器 ID 位数,将节省的位数分配给序列号,提升单毫秒 ID 生成量。
不过雪花算法也存在明显局限:首先是强依赖机器时钟—— 若机器时钟发生回拨(如 NTP 时间同步时,系统时钟从 12:02 回退到 12:00),可能会生成与回拨前重复的 ID,影响数据唯一性;其次是机器 ID 管理成本—— 机器 ID 需提前规划分配,若节点动态扩容,需手动协调新增节点的 ID,避免冲突,增加运维复杂度。
针对这些问题,可采用对应的优化方案:在时钟回拨处理上,系统检测到时钟回拨时,可暂停 ID 生成,等待时钟自然追平至回拨前的时间,或临时切换到备用生成策略(如结合 Redis 临时生成 ID),避免重复;在机器 ID 管理上,可借助 ZooKeeper、etcd 等分布式协调服务,实现机器 ID 的自动分配与回收,支持节点动态扩容,减少人工干预。
在分布式系统或数据标识场景中,UUID(通用唯一识别码)与 GUID(全局唯一标识符,多为微软实现)是常用的唯一标识方案,其核心逻辑与特性可从原理、优缺点及适用场景三方面深入分析。
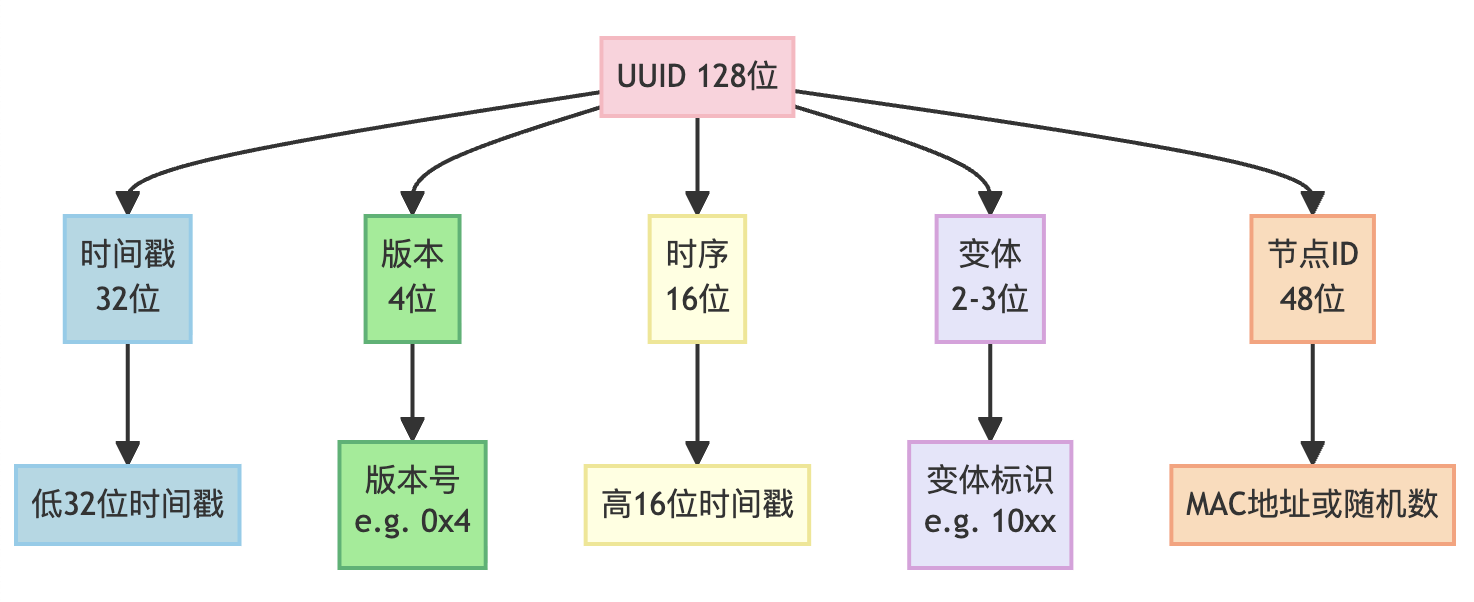
从原理来看,UUID/GUID 通过本地算法生成 128 位的二进制唯一标识,无需依赖外部系统交互。具体生成逻辑会融合多种具有唯一性的元素:例如早期版本(如 UUID v1)会结合设备的 MAC 地址(确保设备级唯一)、精确到毫秒甚至更细粒度的时间戳(避免同一设备不同时间生成重复 ID),再搭配随机数(进一步降低碰撞概率);而后续版本(如 UUID v4)则更侧重高强度随机数生成,减少对硬件信息的依赖。这种本地生成机制意味着标识创建过程无需网络请求或中心化服务响应,从根源上简化了生成流程。
本地生成的特性带来两大核心优势:一是无网络开销,高性能—— 由于无需与外部服务(如数据库、分布式 ID 生成器)通信,ID 生成速度极快,单台设备每秒可生成数十万甚至数百万个 UUID/GUID,能满足高并发场景(如高频日志生成、瞬时大量临时数据标识)的需求;二是无需中心化服务,高可用—— 避免了因中心化服务宕机、网络中断导致的 ID 生成失败问题,即便在分布式集群的部分节点离线时,剩余节点仍能独立生成唯一标识,大幅提升系统的稳定性与容错能力。
不过,UUID/GUID 也存在明显的局限性:首先是无序性—— 其生成规则不包含递增或有序逻辑,生成的 ID 在数值上无规律可循,若作为数据库主键或索引字段,会导致索引页频繁分裂、碎片增多,显著降低数据库的查询与写入性能,尤其在大规模数据场景下影响更为突出;
其次是存储与传输成本高——128 位的二进制标识若转换为十六进制字符串(常见存储形式),会占用 36 个字符(含分隔符),相比 4 字节的 int 型或 8 字节的 long 型标识,存储空间占用大幅增加,同时在网络传输中也会消耗更多带宽资源;此外,早期版本存在隐私风险—— 如 UUID v1 因直接嵌入设备 MAC 地址,若将此类 UUID/GUID 公开(如用于日志上报、外部接口标识),可能泄露设备硬件信息,存在安全隐患,虽后续版本通过随机数优化规避了这一问题,但仍需注意旧版本的兼容性风险。
从适用场景来看,UUID/GUID 更适合对 ID 有序性无要求、仅需确保全局唯一性的场景:例如日志系统中的每条日志 ID(仅需区分不同日志条目,无需按 ID 排序)、分布式缓存中的临时键值对标识(缓存数据生命周期短,无需长期有序存储)、跨系统数据同步时的临时唯一标识(避免不同系统数据冲突,无需关联数据库索引)等。而对于需要 ID 有序(如按创建时间排序的订单 ID)、存储成本敏感(如大规模用户表主键)的场景,则需选择其他标识方案(如雪花算法、数据库自增 ID)。
在数据标识场景中,自增 ID 是一种传统且广泛应用的唯一标识方案,其核心逻辑围绕 “按序生成唯一数值” 展开,常见实现方式分为单库单表模式与多库分段模式,可从原理、优缺点及适用场景三方面深入分析。
从原理来看,自增 ID 的生成逻辑分为两种典型场景:在单库单表架构下,直接依赖数据库自带的AUTO_INCREMENT机制(如 MySQL、MariaDB 等关系型数据库均支持该特性),每当有新数据写入表中时,数据库会自动为该条数据分配一个比上一条记录大 1 的数值作为 ID,例如第一条数据 ID 为 1,第二条为 2,以此类推,全程无需人工干预,生成规则简单直接。这里给个大概的流程例子:
而在多库多表的分布式架构下,为避免不同数据库实例生成重复 ID,会采用 “分段自增” 策略 —— 预先为每个数据库实例分配独立的 “ID 段”,约定不同库的自增步长与起始值。比如将集群中的 3 个数据库实例按 “步长 3” 分段,库 1 仅生成尾号为 1、4、7... 的 ID,库 2 生成尾号为 2、5、8... 的 ID,库 3 生成尾号为 3、6、9... 的 ID,通过提前划分 “数值区间” 确保多库生成的 ID 全局唯一,同时保持自增特性。
自增 ID 的核心优势集中在 “易用性” 与 “适配性” 上:一是实现简单—— 无论是单库的AUTO_INCREMENT还是多库的分段策略,均无需复杂的算法设计或第三方服务支持,开发人员只需配置数据库参数或简单的分段规则即可启用,降低了技术实现门槛;二是天然有序—— 生成的 ID 按时间顺序递增,能直接反映数据的创建先后顺序,这对需要按时间排序的业务场景(如订单记录查询、日志时序分析)极为友好;三是适配数据库场景—— 有序的数值型 ID 作为数据库主键时,能有效减少索引页分裂,降低索引碎片,提升数据库的查询、插入性能,同时数值型存储(如 int、bigint)占用空间小,远低于 UUID/GUID 的字符串存储成本,更适合长期存储大量数据。
不过,自增 ID 也存在明显的局限性,尤其在高并发、大规模分布式场景下问题更为突出:首先是单库单点风险与性能瓶颈—— 单库单表依赖的AUTO_INCREMENT机制完全绑定单个数据库实例,若该实例宕机,将直接导致 ID 生成功能失效,存在单点故障风险;
同时,单库的自增 ID 生成能力有限,受数据库写入性能限制,每秒仅能生成千级别的 ID(远低于 UUID/GUID 的数十万级),无法满足高并发业务(如秒杀、峰值订单处理)的需求;
其次是多库分段的协调与扩容难题—— 多库分段需提前规划步长与各库的 ID 段,若后续业务扩容需要新增数据库实例,需重新调整所有现有库的分段规则,避免与新库的 ID 段冲突,操作复杂且易引发数据风险,同时步长设置过大会导致 ID 浪费,设置过小则可能频繁触发分段调整;此外,自增 ID 易泄露业务敏感信息—— 由于 ID 按顺序递增,外部攻击者可通过连续获取 ID(如访问商品详情页、订单接口)推测出业务量(如某时段内的订单总数),甚至通过 ID 差值分析业务峰值,存在信息泄露风险。
从适用场景来看,自增 ID 更适合小流量、低并发的简单分布式系统,例如中小型企业的内部管理系统(如员工信息管理、库存台账)、低访问量的个人博客或小型电商网站等。
在分布式场景中,基于 Redis 的自增 ID 方案是对数据库自增机制的优化升级,其核心逻辑与特性可从原理、优缺点及适用场景展开分析。
从原理来看,该方案直接借助 Redis 的INCR或INCRBY命令实现 ID 生成:INCR命令可对指定键的数值原子性加 1,每次调用即生成一个新的自增 ID;若需自定义步长(如一次生成多个连续 ID),则使用INCRBY命令指定增量值。为避免单点故障,通常会采用 Redis 集群部署(搭配主从复制与哨兵机制),当主节点故障时,哨兵可自动将从节点提升为主节点,确保 ID 生成服务持续可用,同时通过集群分片进一步提升并发处理能力。
在优点层面,Redis 自增 ID 的优势较为突出:一是性能优于数据库——Redis 作为内存数据库,INCR系列命令执行速度极快,每秒可支持万级别的 ID 生成,远超传统数据库单库千级的性能上限,能应对更高并发场景;二是原生支持分布式—— 通过集群部署可轻松扩展至多节点,无需像数据库分段自增那样复杂的协调逻辑,即可实现全局唯一 ID 生成;三是保持 ID 有序性—— 生成的 ID 按调用顺序递增,能满足业务对时序排序的需求(如订单创建时间排序、消息队列消费顺序),同时数值型 ID 也适配数据库索引优化,减少存储与传输成本。
不过该方案也存在明显局限:首先是强依赖 Redis 可用性—— 若 Redis 集群出现整体故障(如主从同步中断且哨兵失效),将直接导致 ID 生成服务瘫痪,因此必须通过主从复制 + 哨兵 / 集群模式保障高可用,增加了部署与维护成本;其次是重启后计数器恢复风险—— 若 Redis 未开启持久化(或持久化文件损坏),重启后计数器会重置为初始值,可能生成重复 ID,即便开启持久化,从 RDB/AOF 文件恢复数据也需一定时间,期间可能影响服务稳定性;此外,仍存在业务信息泄露问题—— 与数据库自增 ID 类似,有序递增的 ID 易被外部通过连续获取推测业务量(如通过订单 ID 差值判断峰值订单量),无法规避信息泄露风险。
从适用场景来看,该方案更适合中等并发、对 ID 有序性有要求且能接受 Redis 依赖的业务:例如中小型电商的订单 ID 生成(每秒并发数在万级以内)、内容平台的文章 / 视频标识(需按发布时间排序)等场景。这类场景下,既需要高于数据库的性能支撑,又依赖 ID 的有序性,同时团队具备 Redis 运维能力,可接受其部署成本与依赖风险;而对于超大规模并发(每秒十万级以上)或无法容忍 Redis 依赖的核心业务(如金融交易),则需考虑更复杂的分布式 ID 生成方案(如雪花算法结合分布式缓存)。
美团 Leaf 是基于数据库号段的分布式 ID 生成方案,其核心原理是:节点从数据库批量申请连续 ID 号段(例如一次获取 [1000, 2000] 区间的 ID),将号段缓存到本地后,按递增顺序逐个分配使用;当本地缓存的号段剩余量达到阈值时,自动向数据库申请下一段新号段,避免频繁交互。
该方案的优点显著:一是通过批量获取号段大幅减少数据库访问次数,本地分配 ID 无网络开销,性能可达每秒数万级,远超单库自增;二是生成的 ID 天然有序,适配数据库索引优化,满足时序排序需求;三是支持多节点独立申请号段,各节点无资源竞争,搭配数据库主从架构可实现高可用。
缺点在于:若节点意外宕机,本地缓存中未分配的号段会直接浪费(如节点拿到 [1000,2000],仅用至 1500 就宕机,剩余 500 个 ID 作废);需额外设计号段回收机制(如定期检测失效节点的未用号段并回收),否则高并发下节点频繁上下线会导致较多 ID 浪费。
其适用场景集中在对 ID 有序性要求高、同时需降低数据库压力的业务,例如美团外卖的订单 ID、商家商品 ID 等场景 —— 这类业务既需要 ID 反映数据创建时序,又需支撑高并发,Leaf 的批量号段机制能很好平衡性能与有序性需求。
Seata 新版雪花算法核心做出两大改变:

可以查看 官方文档-关于新版雪花算法的答疑 来深度了解
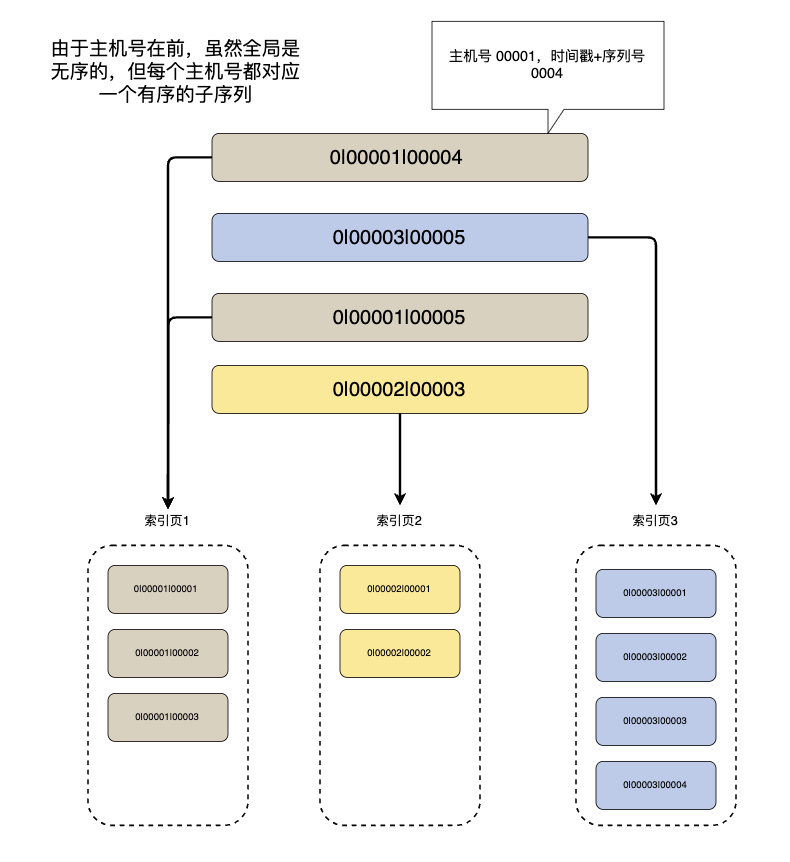
新算法虽不具备全局单调递增性,但能划分出最多1024 个(由 10 位节点 ID 决定)单调递增的子序列,在 MySQL InnoDB 数据库中经过有限次页分裂后会达到稳态,后续 ID 仅在所属子序列尾部增长,可有效减少页分裂。
InnoDB 使用 B + 树索引,主键索引叶子节点存储完整数据行,且以双向链表串联,物理存储为数据页(单页最多存 N 条记录,N 与行大小成反比)。当插入的 ID 需放入已存满的中间数据页时触发页分裂,需新建数据页、拷贝旧数据,属于 IO 密集操作,应尽量避免。
Seata 的新算法全局 ID 无序,但每个节点 ID(workerId)对应 1 个单调递增的子序列,最多可划分 1024 个子序列。前期各子序列的 ID 混插入数据库,可能触发有限次页分裂。经过有限次分裂后,各子序列会在数据库中形成独立的 数据块,后续该子序列的 ID仅在自身数据块尾部增长,不会触发其他子序列的页分裂