关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
大家好,我是牛哥。
在日常工作中,想必大家都遇到过数据库的突发状况 — 可能是流量洪峰引发的卡顿崩溃,也可能是硬件故障导致的突然停摆。
一旦出现这些状况,核心数据往往面临丢失风险,而这时候,redo log 总能挺身而出,将那些没写完的事务成功找回来。
redo log 的这神奇的救场能力究竟从何而来?
今天牛哥就从基础开始,一步步拆解 redo log 的工作逻辑,搞懂它如何在数据库崩溃时,守住数据安全的最后一道防线。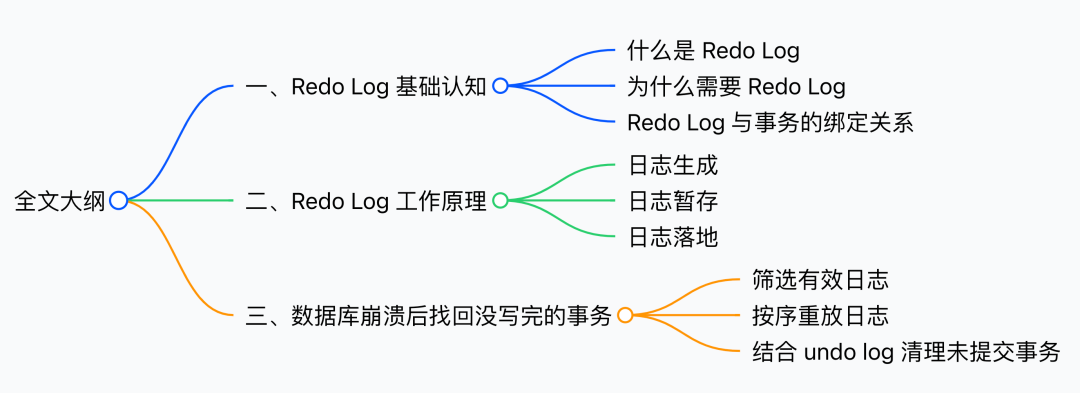
在弄懂它如何帮数据库找回未完成事务之前,我们先理清三个核心问题:它是什么?数据库为什么非它不可?它和我们常打交道的事务,又有着怎样的关联?
作为 InnoDB 存储引擎独有的关键组件,redo log 本质上是一套重做日志:它不关心谁执行了 INSERT/UPDATE,也不记录操作的过程,只聚焦数据被改成了什么样。
例如执行 “把用户 A 的余额从 800 元改成 1000 元”,它只会留下这样一条记录:
“某数据页中,用户 A 的余额字段值更新为 1000”
就像一位 “结果导向” 的记录员,只记最终状态,不记中间步骤。
而它的核心作用也很明确 — 保障数据库事务的持久性(ACID 里的 D)。只要事务显示「执行成功」,就算下一秒数据库崩溃,这笔事务的数据也不能丢。
既然事务持久性这么重要,数据库自身难道没有机制可以保障吗?答案是,还真没有....
数据库的工作逻辑,天生就和持久性存在一个矛盾:
我们知道,数据最终存在于磁盘上,但磁盘的读写速度远慢于内存。如果每次执行事务,都直接把数据写入磁盘,频繁的随机读写会让数据库性能暴跌。
所以,数据库设计了一个缓冲层:先把数据读到内存,像 InnoDB 的 Buffer Pool 就是这样的内存区域。事务修改时先改内存里的数据,之后再由后台线程在合适的时机,把内存里的修改同步回磁盘。
这种先改内存,后写磁盘的方式,能极大提升性能,但也带来了一个风险:
如果内存中的修改还没同步到磁盘,数据库突然崩溃,这部分已完成的事务数据就会永久丢失。
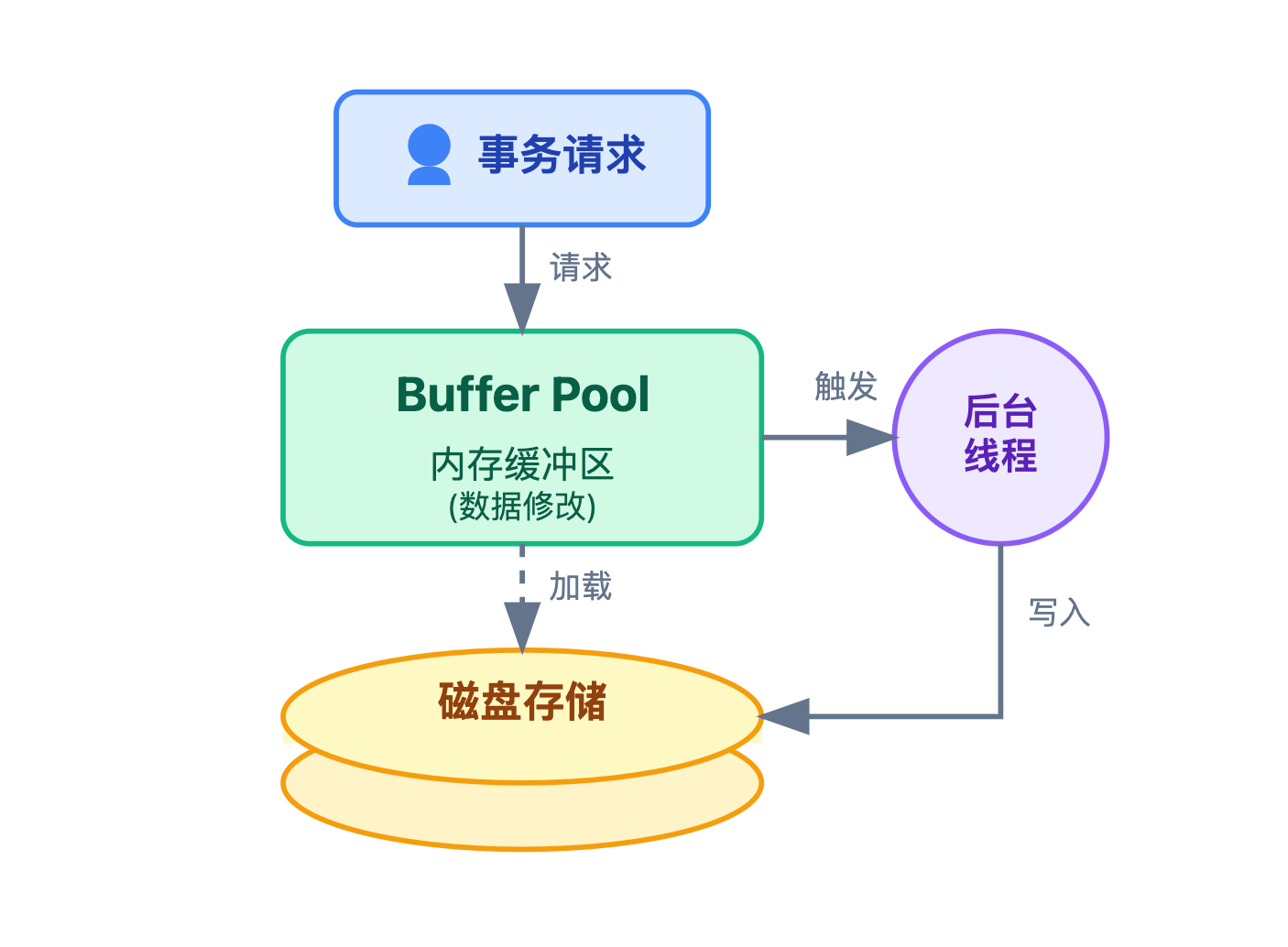
redo log 的出现,就是为了解决这个问题。它就像给数据库装了一个安全气囊:
事务执行时,会同时把数据修改了什么记录到 redo log 里,并且只要 redo log 成功写入磁盘,就算数据还在内存没同步,也认为事务已经持久化了。
它的设计思想也正是遵循数据库领域经典的 WAL(Write-Ahead Logging,预写日志)思想:日志先行落盘,数据滞后同步。
这种机制既不破坏先改内存带来的性能优势,又能通过先写日志到磁盘的策略,给事务上一道安全锁。哪怕数据还在内存,只要 redo log 已经落盘,就能通过它还原出那些没来得及写入磁盘的修改。
可以说,没有 redo log,数据库要么只能直接写磁盘,牺牲性能换安全;要么只能冒险用内存缓冲,牺牲安全换速度,根本无法满足业务又快又稳的需求。
而 redo log 要真正发挥作用,并非孤立运行,它的整个工作流程,都和我们日常开发中频繁打交道的事务深度绑定。
在工作中,我们写的每一个 INSERT、UPDATE、DELETE 语句,最终都会对应数据库的事务操作,而 redo log 就像事务的贴身保镖,从事务开始到结束,全程紧跟、时刻守护:
1.事务执行中:实时记录每一步修改
事务只要执行了数据修改操作,不管是新增数据的 INSERT、更新数据的 UPDATE,还是删除数据的 DELETE,哪怕这时候事务还没提交,redo log 都会立刻 “记笔记”。比如执行 “UPDATE user SET balance=1000 WHERE id=1” 时,redo log 会记录:
“在某个表空间,某个数据页里,id=1 这条记录的 balance 字段,数值从 800 变成了 1000”。
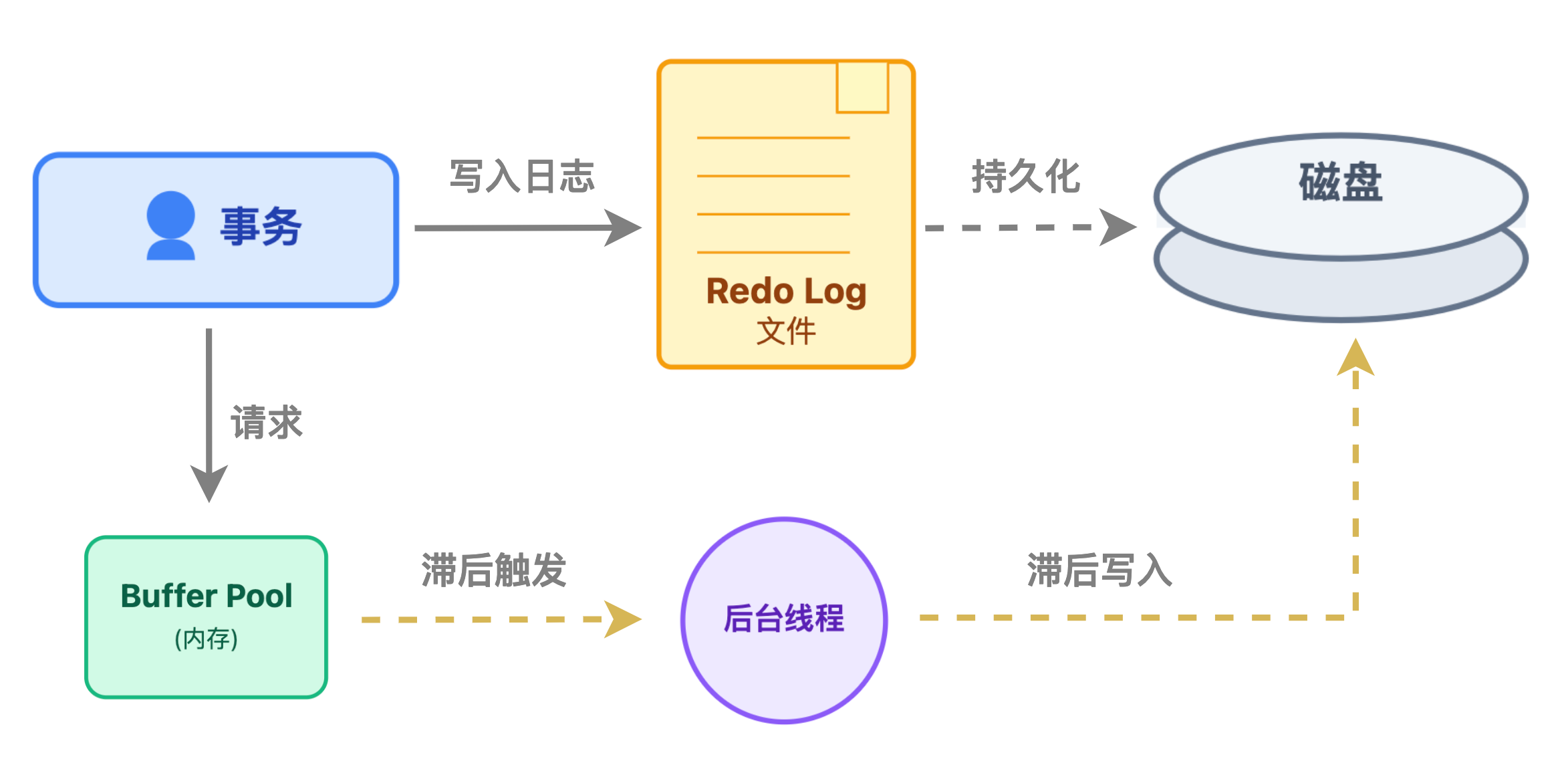
笔记会先存在内存的日志缓冲区(redo log buffer)里,不会立马存到磁盘里,因为事务可能还会继续修改,频繁写磁盘太浪费资源。
2.事务提交时:必须让 redo log 落地
直到事务执行 COMMIT 提交时,数据库才会把内存中这个事务的 redo log 全部写入磁盘,这个过程叫 “刷盘”。而且只有等 redo log 刷盘成功,数据库才会给应用返回 「事务执行成功」 的响应。
只要 redo log 刷盘了,就算数据还在内存没同步到磁盘,事务就被认为是安全的,不怕后续崩溃。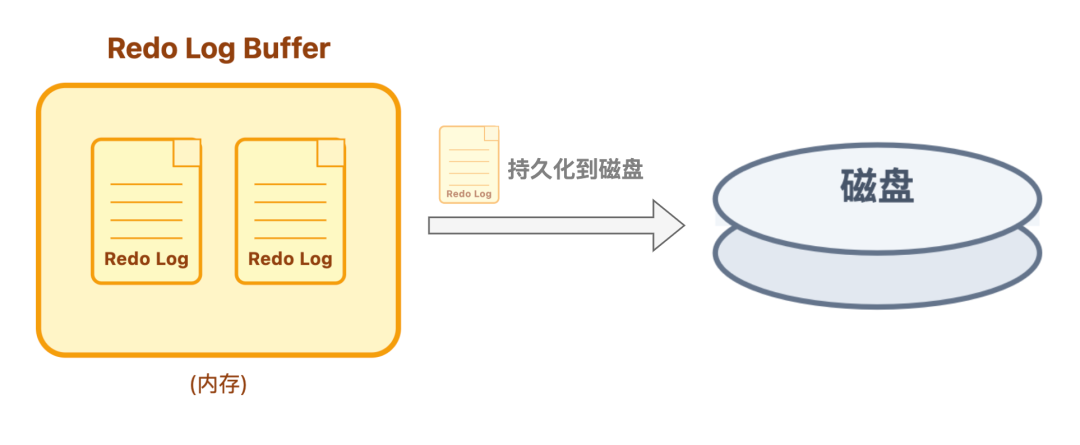
3.事务未提交:redo log 也有用,但会作废
说完了事务提交时的情况,可能有人会问:如果事务没提交,比如执行到一半出错了,或者用户主动 ROLLBACK 回滚,那之前生成的 redo log 怎么办?
其实,未提交事务的 redo log 也会存在内存中,但数据库会给它做个标记。如果事务正常回滚,这部分 redo log 会被直接作废,不会再被刷盘;
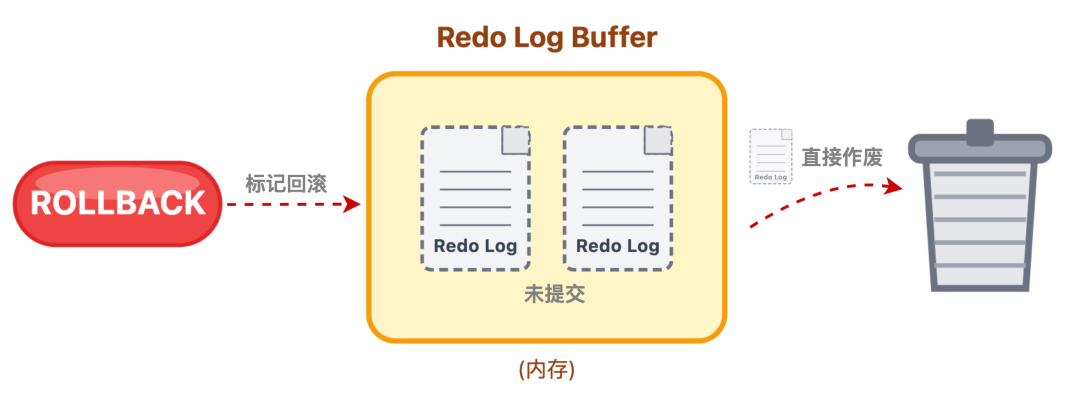
但如果回滚前数据库崩溃了,重启后数据库会结合redo log 和另一种日志即回滚日志(undo log),把未提交事务的修改 ”撤销” 掉,确保数据不会混乱。
简单来说,redo log 这位保镖的职责很明确:事务在的时候,它记录每一步动作;事务要提交时,它必须先存好凭证(刷盘);就算事务中途反悔(回滚),它也会配合其他机制清理痕迹。
清楚了 redo log 与事务的绑定关系,接下来我们拆解它的完整工作流程 —— 从日志生成、暂存到最终落地磁盘,redo 的每一步操作都在平衡性能与安全,就像一套精密的数据备份流水线。
当事务执行数据修改操作时,redo log 会同步生成,它的记录逻辑有两个核心特点:
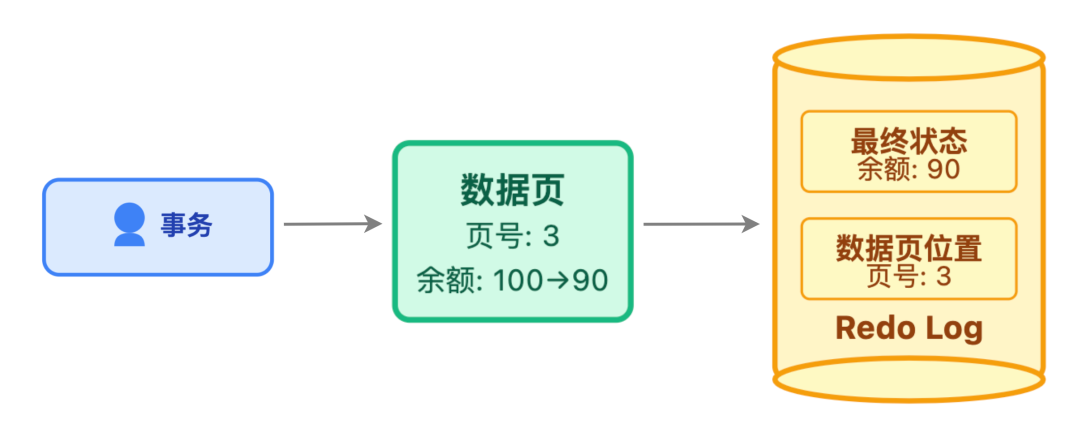
聚焦「最终状态」而非 「执行过程」:redo log 不关心过程性信息,只记录 「数据最终变成了什么样子」 以及 「这个数据在磁盘的具体位置」。比如修改用户余额时,它只会记 “某表空间的某数据页中,用户 A 的余额字段为 1000”,这种方式让后续恢复时能直奔目标,无需重复执行 SQL 逻辑。
以数据页为最小记录单位:InnoDB 中的数据按数据页(默认 16KB)管理,redo log 也遵循这一规则。哪怕只修改了数据页中的一个字段,日志也会关联整个数据页的位置信息。就像修改文档里的一个字,会记录 “在第 3 页第 5 行”,而不是只记 “改了一个字”,这样后续恢复时才能精准定位到目标数据。
此外,同一事务的所有 redo log 会被串联起来,形成一个完整的日志组。比如一个事务同时修改用户余额和订单状态,这两个操作对应的日志会被标记为同属一个事务,确保后续刷盘和恢复时不会遗漏。
刚生成的 redo log 不会立刻写入磁盘,而是先暂存到内存中的日志缓冲区(redo log buffer)。这样设计的核心目的,是避免频繁写磁盘导致性能损耗。
不过,暂存内存并非简单堆积,InnoDB 对 redo log buffer 的管理有着明确的策略,核心是遵循按需刷盘原则:
既要保证内存不会被日志过度占用,又能减少不必要的磁盘 I/O 消耗。
具体来说,它通过 「分组存储」 和 「按需触发」 两种方式,让日志在内存中的暂存和刷盘更高效:
分组存储的核心是通过事务 ID 关联,每个事务生成的日志,都会自带唯一的事务 ID 标识,比如事务 T1 的所有修改日志,都会打上 归属 T1 的标记,和事务 T2 的日志 打上 归属 T2 的标记,就算在 buffer 中混合存放,也能通过标记清晰区分,互不干扰。
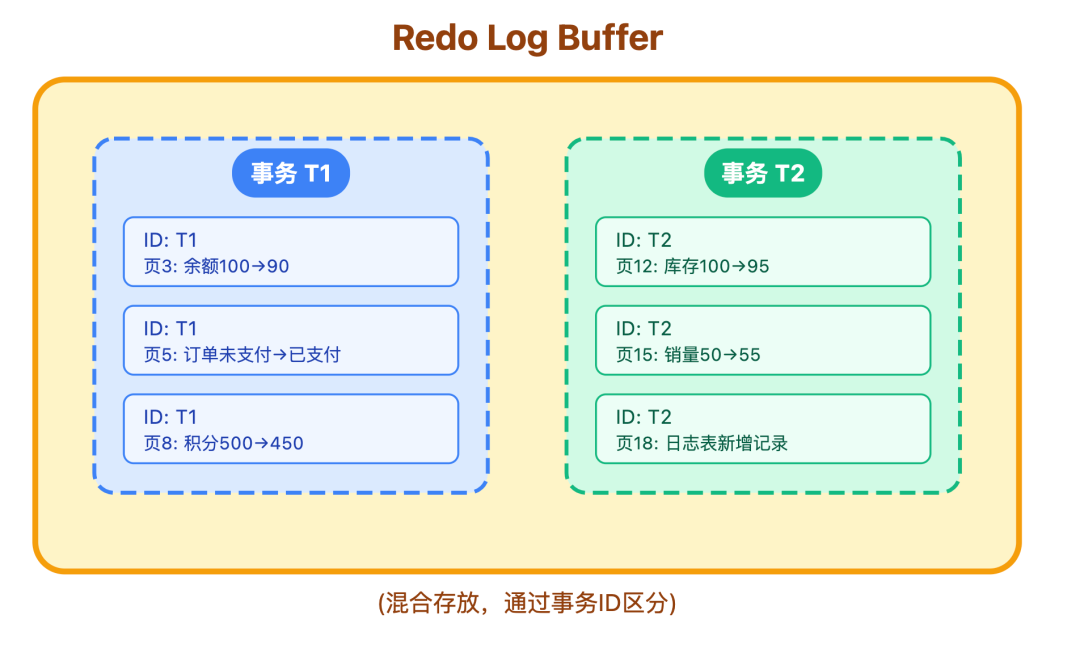
这样设计的好处很直接:
按需触发则会更灵活,它会根据实际场景灵活触发日志从 日志缓冲区(buffer) 刷到磁盘的时机,主要有三种情况:

事务提交时强制刷盘:这是最核心的场景。只要事务执行了 COMMIT 命令,InnoDB 就会立刻将该事务在 redo log buffer 中的所有日志写入磁盘,并且只有等刷盘完全成功,才会向应用返回事务执行成功的响应。
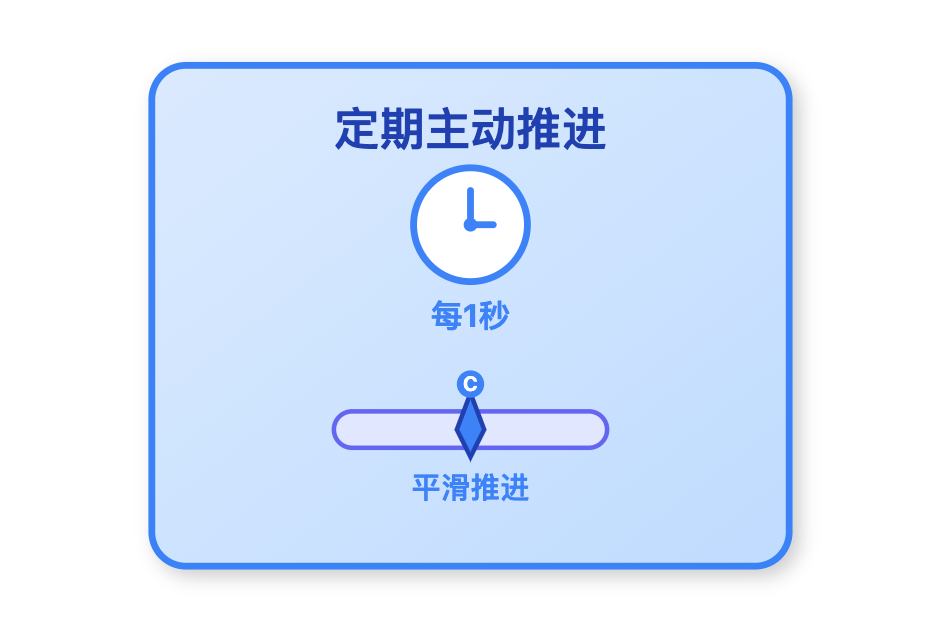
后台线程定期刷盘:InnoDB 会启动专门的后台线程,每隔 1 秒就把 redo log buffer 中的日志批量写入磁盘。即便有些事务还没提交,只要日志在缓冲区中存放了一段时间,也会被同步到磁盘,这样能避免突发断电时,内存中堆积大量未刷盘的日志,降低数据丢失的风险。
内存不足时主动刷盘:当 redo log buffer 的使用率达到预设阈值,比如总容量的 50%,InnoDB 会主动将部分日志刷到磁盘,腾出足够的内存空间,供新生成的日志存放。
当日志从内存刷到磁盘后,会存入专门的重做日志文件即 redo log file 中。这些redo log file 通常会配置多个,组成日志组。
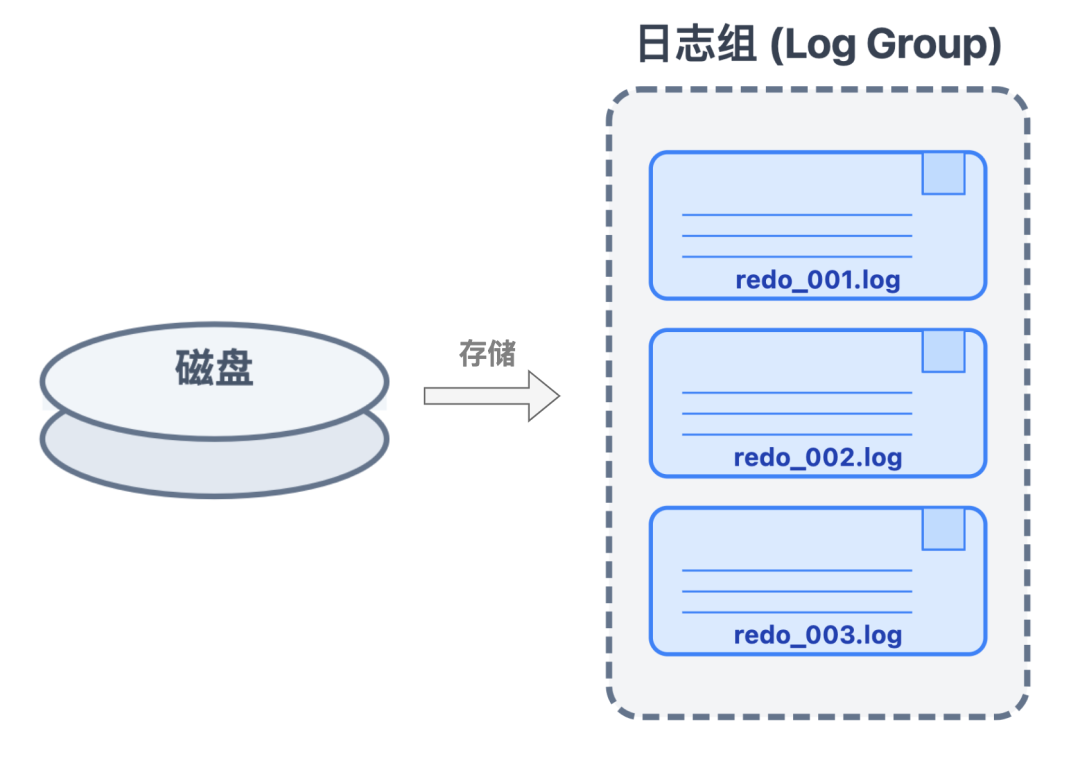
这样做既能避免单个文件过大难以管理,也为后续高效的日志存储和写入打下基础。
而整个日志在磁盘上的管理逻辑,核心围绕如何在有限空间内,既保证日志不丢失,又不影响写入性能展开,具体通过三个关键设计实现:
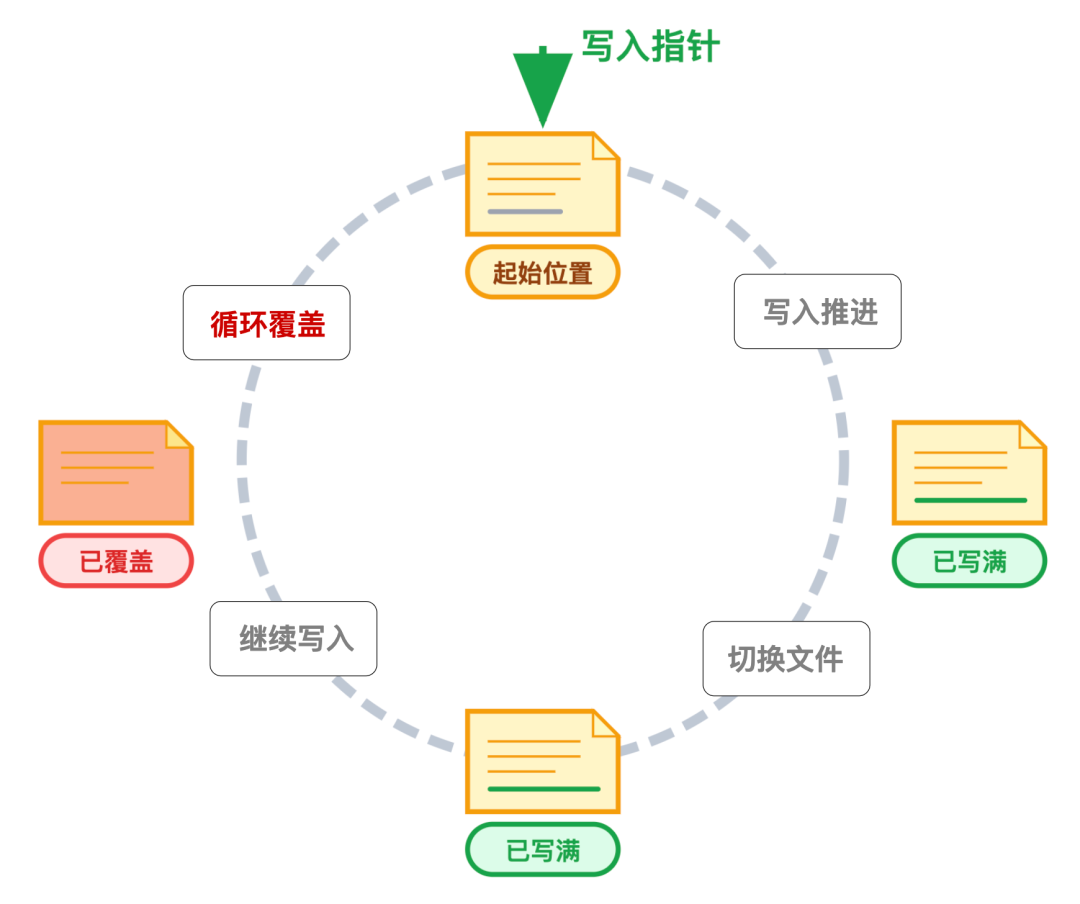
为了让有限的日志文件能持续支撑数据库运行,InnoDB 会将多个 redo log 文件在逻辑上拼接成一个环形存储空间,就像一条首尾相连的跑道。
日志写入时,会从第一个文件的起始位置开始,写入位置逐步向后推进,写满当前文件后,自动切换到下一个文件继续写入;
当最后一个文件也被写满时,不会额外创建新文件,而是回到第一个文件的开头,覆盖最早写入的日志内容。
这种循环利用的方式,既避免了日志文件无限膨胀,又能让写入流程保持连续,无需频繁处理文件创建、删除等额外操作。
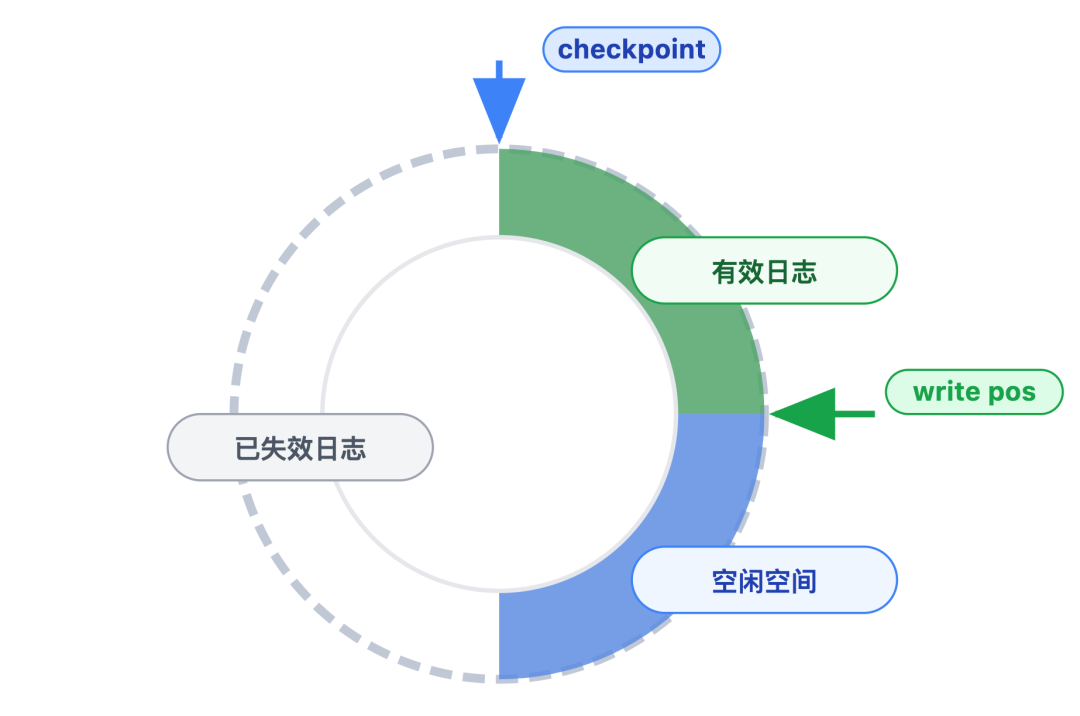
环形存储虽然高效,但存在一个关键问题:如果过早覆盖还有用的日志,会导致崩溃后无法恢复数据。为了解决这个问题,InnoDB 用两个指针来协调写入和覆盖的节奏:
write pos(写入指针):标记当前日志的写入位置。每次有新日志写入,这个指针就会沿着环形空间向后移动,当到达当前文件末尾时,自动跳转到下一个文件的开头。
checkpoint(检查点指针):标记失效日志的边界。当某段日志对应的修改已经成功同步到磁盘数据文件后,这段日志就不再需要保留即失效,此时 checkpoint 指针会向后移动,指向这些失效日志的末尾。
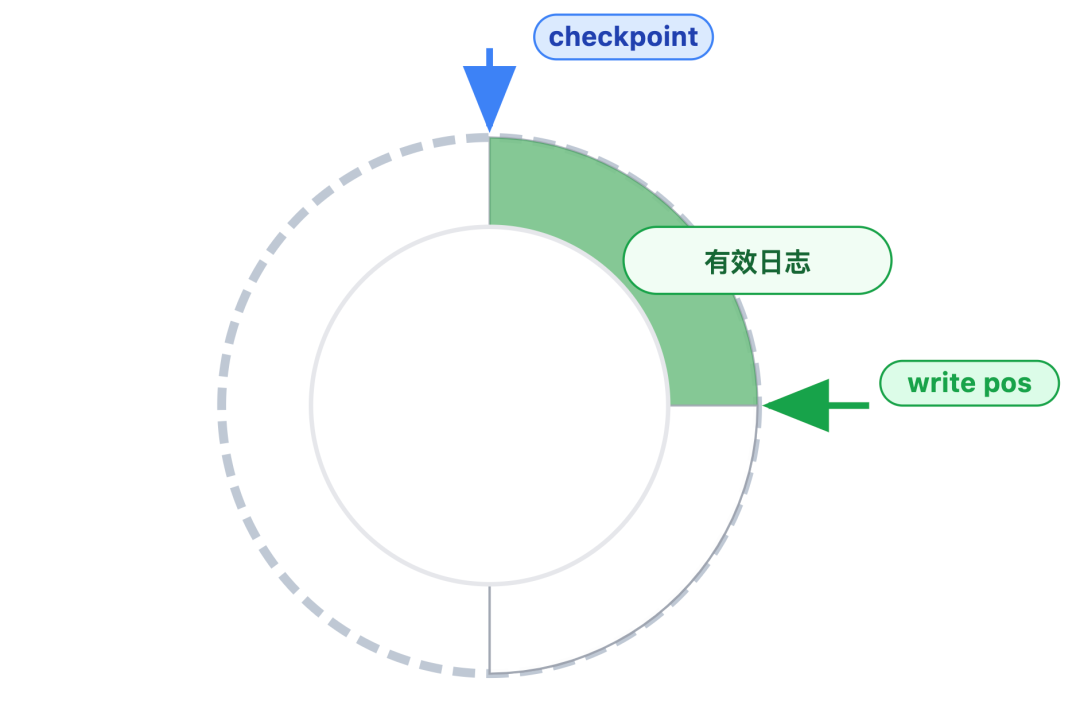
这两个指针之间的区域,就是当前可用的日志空间。要让这块空间高效循环利用,关键在于 checkpoint 指针的移动策略 —— 它并非随机触发,而是通过主动推进为主、被迫推进兜底的策略进行:

日志落地时,还有一个决定性能的关键设计:采用顺序写的方式写入磁盘。这和数据文件的「随机写」形成了鲜明对比:
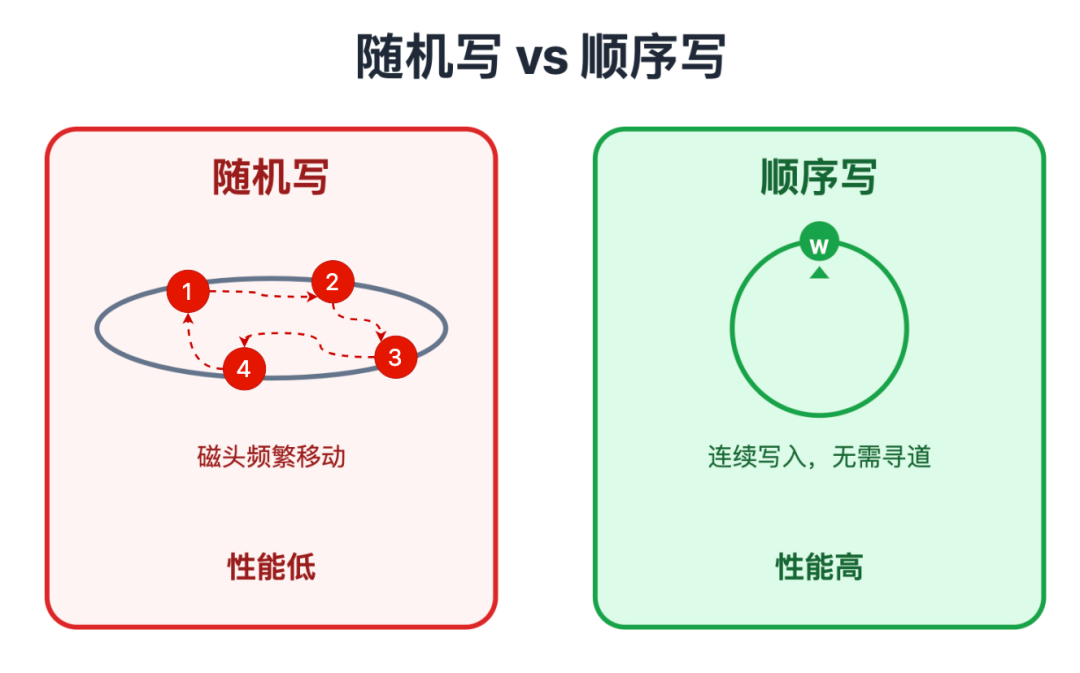
这一设计完美解决了既要通过写磁盘保障数据安全,又要避免性能损耗的核心矛盾,让 redo log 在实现高可靠性的同时,不会成为数据库性能的瓶颈。
不过日志写得再精妙,最终还是要能在关键时刻救场。redo log 真正的 “价值高光时刻”,是在数据库崩溃后的恢复阶段。
这个阶段,数据库会自动完成整套恢复流程,无需人工干预,整个过程形成一条连贯的处理链路:筛选有效日志 → 重放日志补数据 → 清理未提交事务,三步环环相扣,最终确保数据恢复到一致状态。
数据库重启后,首先要做的不是立刻恢复数据,而是先筛选出 redo log 中真正需要处理的有效日志。这个筛选逻辑,正是基于我们前面提到的 「checkpoint 指针」 和 「write pos 指针」:
首先,会直接忽略 checkpoint 指针之前的日志。因为这部分日志对应的修改,早已同步到磁盘数据文件,属于失效日志,恢复时再处理它们只会浪费资源;
接着,会锁定 checkpoint 指针到 write pos 指针之间的日志。这部分日志对应的修改,很可能还停留在内存中,没来得及同步到磁盘,一旦数据库崩溃就面临丢失风险,因此它们是有效日志,也是后续恢复数据的核心依据。
至于 write pos 指针之后的区域,这部分属于环形空间中的 “空闲区域”—— 要么还未写入任何日志,要么早期的日志已被覆盖,自然也无需处理。
举个具体的例子:
如果 checkpoint 指针指向日志文件的第 100 行,write pos 指针指向第 200 行,那么第 100 行到第 200 行的日志,就是需要重点处理的有效日志。
这些日志记录的修改,很可能因为数据库崩溃没能同步到磁盘,必须通过恢复补全。
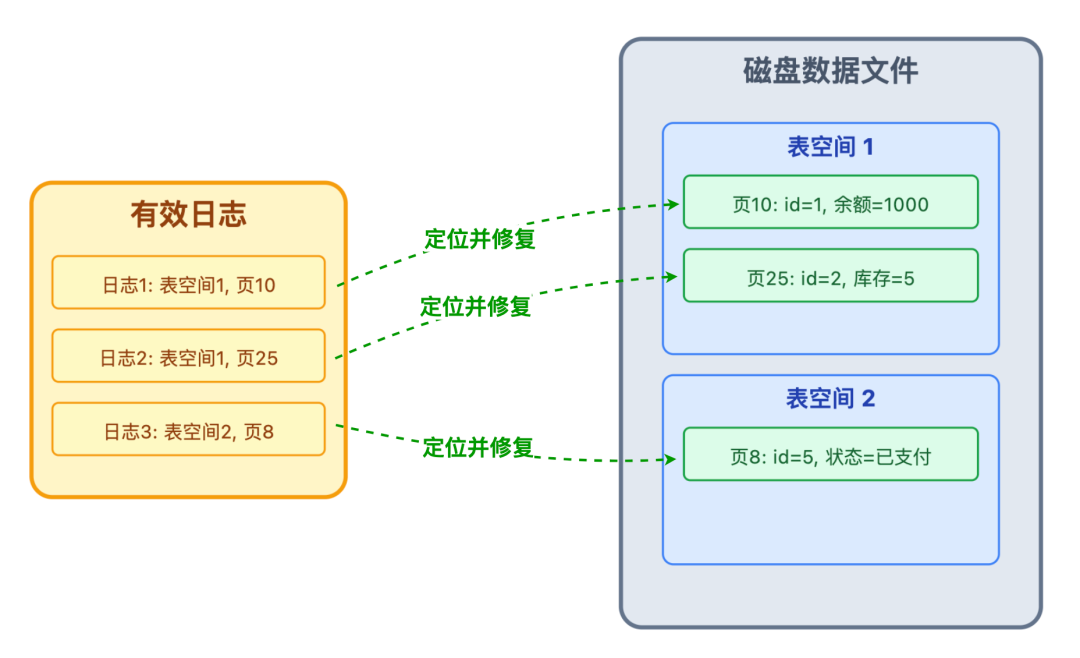
筛选出有效日志后,数据库会按照日志生成的时间顺序,逐一重放(Replay)日志中的内容。这里的「重放」,并不是重新执行一遍原始的 SQL 语句,而是根据日志中记录的精准定位信息和修改结果,直接对磁盘数据文件进行操作。
比如某条有效日志记录着 “表空间 1、数据页 10 中,id=1 的用户余额字段应更新为 1000”,恢复时数据库会直接找到磁盘上对应的表空间和数据页,将该字段的值设置为 1000,相当于把之前没来得及同步到磁盘的修改 “补” 了上去。
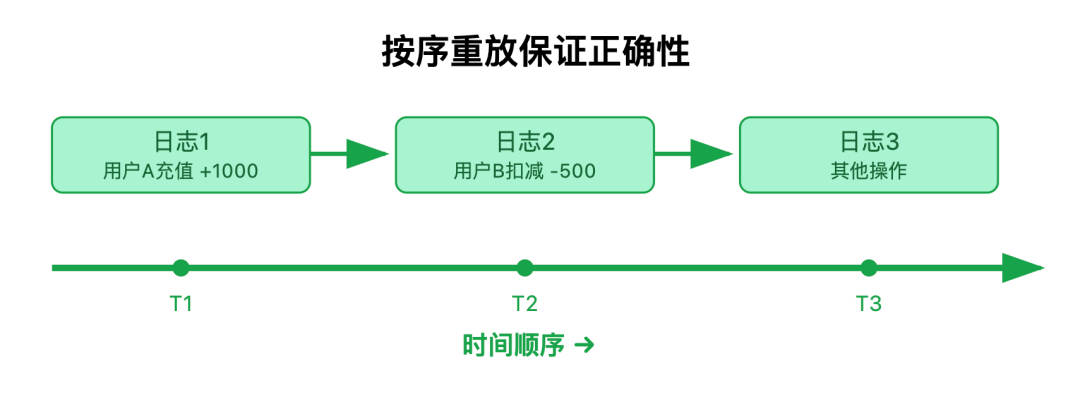
为什么必须按顺序重放?
因为事务的修改可能存在依赖关系,比如先给用户 A 充值,再扣减用户 B 的余额,这两个操作的日志必须按先后顺序执行,才能保证数据逻辑正确。如果打乱顺序,很可能出现扣减在前、充值在后的错误,导致数据混乱。
通过按序重放所有有效日志,数据库就能把崩溃前已经提交、但未同步到磁盘的事务修改,完整地还原到磁盘数据文件中,相当于让这些没写完的事务在磁盘上完成了收尾工作。
不过,redo log 的有效日志中,不仅包含已提交事务的日志,还可能混有未提交事务的日志。因为后台线程会定期执行刷盘操作,即便事务还没提交,它的日志也可能已经被写入磁盘。
如果数据库恢复时直接保留这些未提交的事务,会导致数据不符合业务逻辑,比如用户发起付款操作时事务已经启动,但用户还没点击 “确认付款”,这意味着事务并未提交。若数据库恢复时把这笔付款保留,就会出现“用户没确认付款,账户余额却被提前扣除” 的问题。
这时候,就需要另一种日志 undo log 即回滚日志来配合了。undo log 记录的是事务修改前的数据状态,相当于给数据留了备份,专门用于事务回滚。在恢复阶段,数据库会通过以下逻辑清理未提交事务:
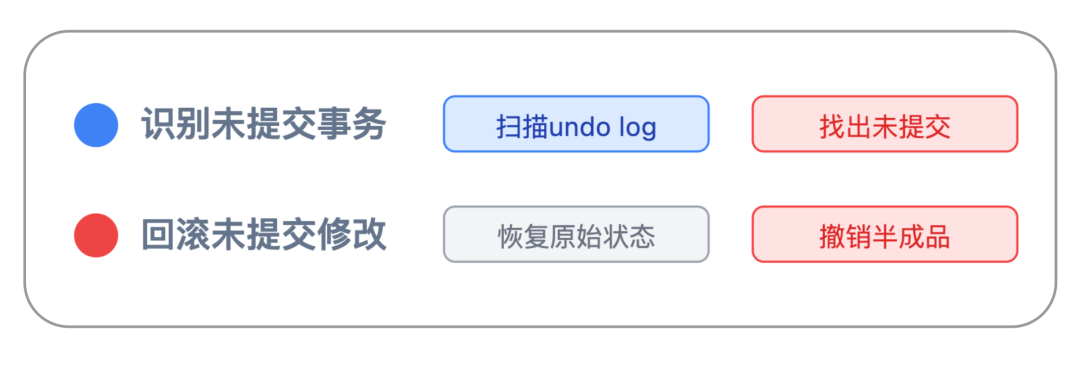
举两个典型案例,就能更直观理解这个过程:
案例 1:已提交事务的恢复
事务 T1 执行了 “给用户 A 充值 200 元” 并成功提交,它的 redo log 已落盘,但对应的数据修改还没同步到磁盘就发生崩溃。数据库重启后,通过重放 T1 的 redo log,将用户 A 的余额从 800 元补全为 1000 元,T1 的操作成果得以保留。
案例 2:未提交事务的清理
事务 T2 执行了 “扣减用户 B 余额 100 元”,但还没提交,它的 redo log 就被后台线程刷到了磁盘。数据库崩溃重启后,redo log 先重放了 T2 的修改,把用户 B 的余额从 500 元改成 400 元;但随后通过 undo log 发现 T2 未提交,又通过 undo log 将余额恢复为 500 元,避免了数据异常。
正是这三步操作,让 redo log 既能找回已提交但未同步的事务数据,又能清理未提交的无效修改,最终让数据库恢复到崩溃前的一致状态。
写到这里,相信你已经明白 redo log 为何能成为数据库 「数据安全的最后一道防线」。它的核心价值在于用一套巧妙的设计,解决了数据库性能与安全的天然矛盾,我们可以用三个关键点来概括它的逻辑:
1. 本质:用「日志先行」保障事务持久性
redo log 不记录操作过程,只记录数据修改后的最终状态 + 精准位置,核心遵循日志落盘即事务持久化的规则。
只要事务显示 “执行成功”,就意味着其对应的 redo log 已成功写入磁盘,哪怕数据还在内存中,后续数据库崩溃了也能通过日志恢复。
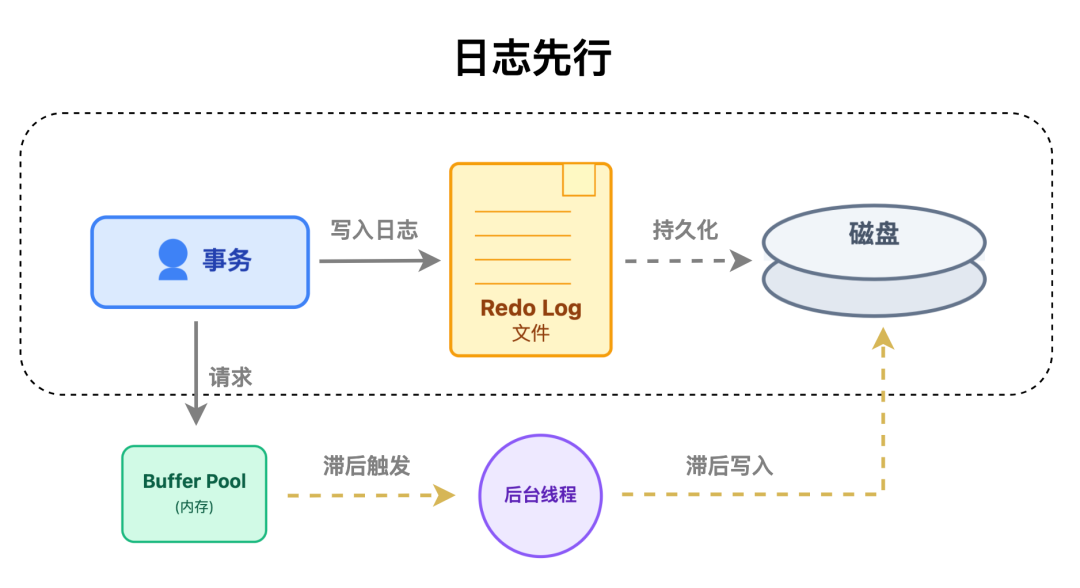
这种日志先行的策略,让数据库既能通过内存缓冲提升性能,又不用担心数据丢失,完美兼顾了快与稳。
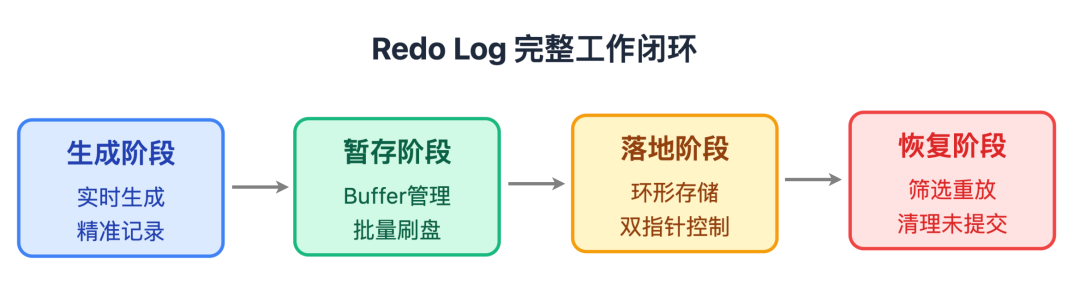
2. 流程:从生成到恢复的全链路闭环
redo log 的工作形成了一套完整的闭环,每个环节都在平衡效率与安全:
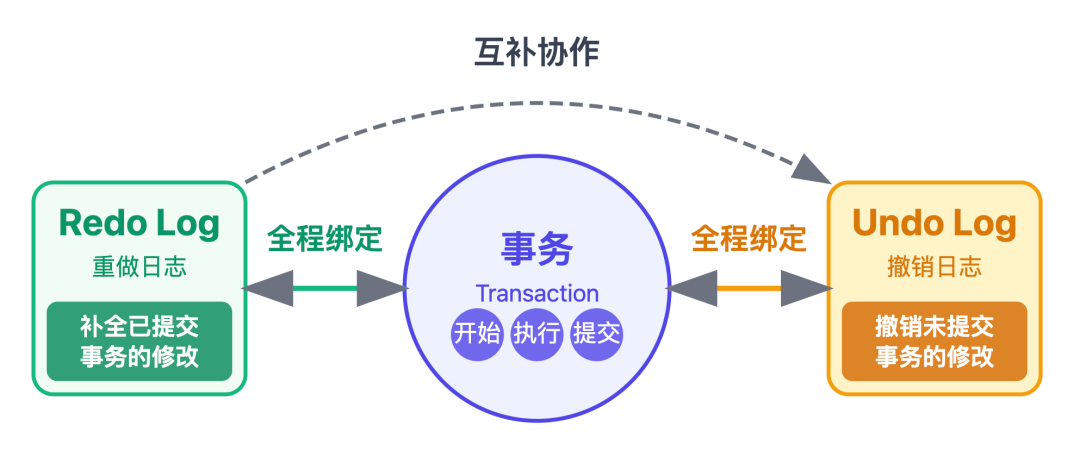
3. 协作:与事务、undo log 的 “三位一体”
redo log 并非孤立工作,而是与事务、undo log 深度协作:
理清了 redo log 的这些逻辑,“数据库崩溃后如何恢复数据” 的谜题就算彻底解开了,不仅如此,我们还能将这份理解延伸到日常开发中,轻松应对更多实际场景:
比如更清晰地理解数据库的性能优化思路,明白为什么调整 redo log 文件大小会影响性能;
也能更高效地排查数据一致性问题,搞清楚为什么未提交事务不会导致脏数据。
这也印证了,跳出表面问题深挖底层原理,才是提升开发效率从容解决技术难题的关键。

