短链系统的核心是如何生成唯一、长度较短的编码。我们有三种思路可供选择:一是采用雪花算法; 二是采用数据库的自增 ID;三是将 url 进行哈希。雪花算法单机每秒可生成百万级 ID,生成速度极快且无 ID 冲突,是最合适的方案。
短链跳转是「读多写少」场景,适合用 Redis 缓存短码对应的原码,完整的映射表则存储在 MySQL 中。必要时还可以使用 MySQL 读写分离技术。主库负责生成短码,从库分担读压力。
雪花算法
- 优点:单机每秒可生成百万级 ID,生成速度极快,且无 ID 冲突,
- 缺点:生成的短链较长,需要考虑时钟回拨问题和机器ID分配
数据库自增主键
- 优点:利用数据库原生保证唯一性,无需额外开发
- 缺点:高并发下大量写请求竞争自增锁会导致吞吐量过低;ID 递增易暴露业务数据量,如order_id=10086可推测订单量。
长链接进行哈希计算取哈希值的前 N 位作为短码
- 优点:哈希结果无序,无法推测原始数据或业务量
- 缺点:哈希碰撞概率较高需要频繁查库确认;哈希结果随机,不便于数据库索引优化,插入效率低。
- (可选)查询原始 url 是否已经在数据库中存在。(查询比生成还慢,数据库容量够的情况下可以不查询。或者在插入的时候再使用唯一索引去重。)
- 使用雪花算法生成一个 64 位 ID
- 使用 base62 或 base64 算法将 64 位整数 ID 转为 10 位字符串 ID
- 将字符串 ID 存入数据库。
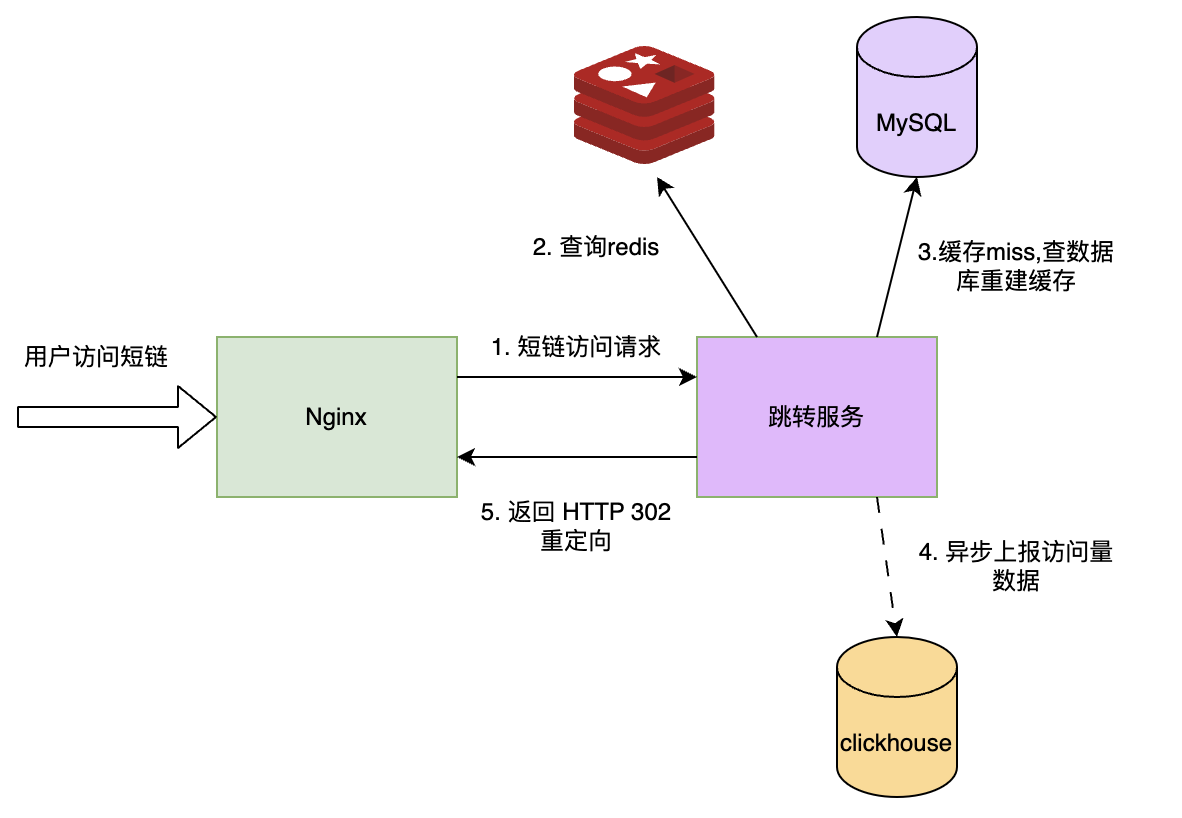
1.用户访问短链请求先到接入层(Nginx)。
- Nginx 转发请求到「跳转服务」集群。
- 跳转服务优先查 Redis:
- 若存在且未过期:直接返回 302 临时重定向(而非 301,因 302 可统计点击量,且长链接变更后能同步更新);
- 若不存在 / 已过期:查 MySQL,查到则更新 Redis 并跳转,查不到返回 404。
- (可选)异步统计:跳转成功后,发送一条消息到 Kafka/RabbitMQ,由「统计服务」消费并更新 click_count、记录访问日志。
高并发优化:
- 缓存:Redis 支撑每秒 10 万 + 读请求,避免 DB 瓶颈。
- 读写分离:MySQL 主库负责生成短码,从库分担读压力。
可用性保障:
- Redis 高可用:主从复制 + 哨兵模式,主库挂了从库自动切换。
- MySQL 高可用:主从备份 + 定时快照,避免数据丢失;支持故障转移。
- 服务降级:极端场景下,关闭统计功能、新建短码功能,优先保障跳转核心流程。
其它优化:
- 防恶意短链:生成短码前校验长链接合法性(如过滤钓鱼、违法链接。
- 防刷限流:接入层用 Nginx 或 Redis 实现 IP 限流(如单 IP 每秒最多 10 次请求)。

