关注牛哥公众号:牛牛码特,回复:1,即可获得秋招大礼包
面经统计表/Java Top100面试题/秋招企业投递表
Kafka 的高性能并非单点突破,而是多个机制协同作用的结果。首先,顺序写入是其最核心的性能保障。传统的随机写操作在磁盘上非常耗时,而 Kafka 通过日志结构,将消息直接顺序追加写入磁盘末尾,这不仅大大减少了磁盘寻址开销,还可以与操作系统页缓存机制协同工作,使写入性能接近内存水平。
另一个关键点是批量处理机制。无论是生产端的批量发送,还是 broker 内部的批量落盘,以及消费者端的批量拉取,这种设计都极大降低了每条消息的网络和 IO 开销,从而提升了单位时间内的处理能力。
此外,Kafka 还借助了零拷贝技术(zero-copy),在消息从文件发送到网络时绕过了用户态内存,从而进一步减少了上下文切换和数据复制开销。
压缩机制也是 Kafka 能在大规模数据传输场景中保持稳定吞吐的利器。通过压缩多个消息在传输层减少数据体积,一方面降低了带宽使用,另一方面也加快了消费端的处理效率。
整体来看,Kafka 的架构理念是将复杂度留在 broker 内部,通过一系列贴近操作系统底层的优化,来换取整体吞吐能力的跃升。这些优化并不神秘,但组合起来却构成了 Kafka 超高性能的基础,下面我们分别针对这些优化来探索:
Kafka 之所以选择顺序写,是出于对性能与复杂度的综合权衡。在传统的数据库或消息系统中,数据写入往往涉及复杂的索引、结构维护、随机寻址等过程,而 Kafka 则反其道而行之,采用类似 append-only log 的模式,将消息持续追加到磁盘文件末尾。
顺序写最大的优势是性能极高。在现代磁盘设备中,顺序写的速度通常比随机写高出一个数量级,尤其是在机械硬盘上表现更加明显。Kafka 不仅将写操作设计为顺序追加,还配合操作系统的页缓存机制,让消息首先写入内存缓存,由系统后台异步刷盘,从而进一步提升吞吐。
而在实际的业务使用中,Kafka 的顺序写策略也带来了系统维护上的便利。写入顺序天然构成了消息的偏移(offset),不仅方便消费者精确控制消费进度,也降低了系统对元数据管理的依赖。
这种设计虽然牺牲了一定的灵活性,例如无法对消息做插入更新等操作,但对于 Kafka 这种高吞吐、流式处理场景来说,顺序写正好满足了最核心的需求,也正是其区别于传统消息中间件的关键所在。
一般而言写磁盘的性能会远远低于操作内存,但是顺序写入则不一样,顺序写入的性能通常而言可以高出随机写入3个以上的数量级,甚至接近内存写入。
为什么顺序写入性能会这么高?为了解决这个问题,我们需要先理解写入磁盘具体是做什么?
我们可以简单一点把写入磁盘分为两步:
1.寻址;2.数据传输,寻址需要磁头转动,是机械操作,是主要耗时的地方,而随机写入,就得每一次都去寻址,这就意味着每一次都需要机械活动,自然就非常慢,所以从磁盘的视角来看,它是很讨厌随机写入的。
有个简单理解其实就差不多了,如果想更深入一点理解,可以把磁盘写入拆得更细致:
1.磁头沿着半径机械移动,最终移动到数据所在的磁柱
2.盘片旋转,是磁盘对齐数据所在扇区
3.数据传输,也就是写入数据
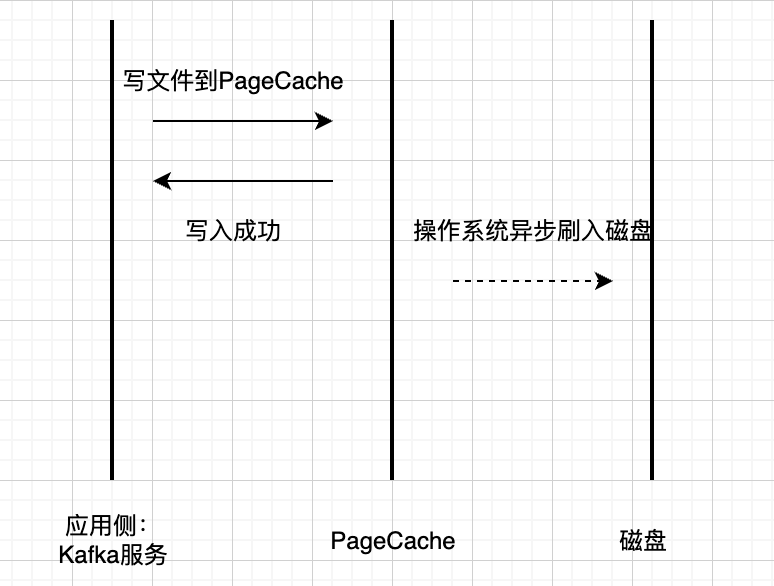
Kafka 的性能优化中,操作系统的 页缓存机制(Page Cache) 起到了非常关键的作用。当生产者发送消息时,这些数据并不是立即落盘,而是被写入操作系统提供的页缓存中。这是一块用于缓存磁盘数据的内存区域,可以延迟刷盘,从而显著提升写入性能。
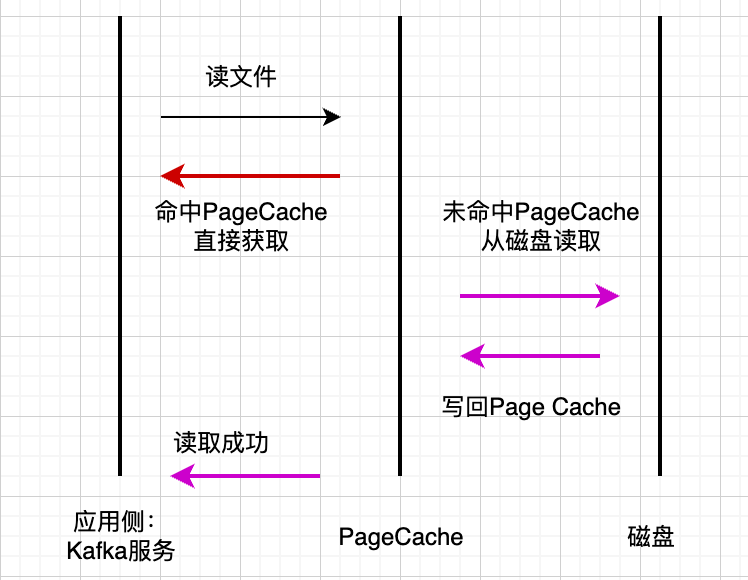
在消费过程中,如果消费者在写入后短时间内就开始拉取数据,那么这些数据往往还停留在页缓存中,不需要再从磁盘读取,这就极大减少了磁盘 IO。Kafka 的“写后即读”特性与 Page Cache 的缓存策略高度契合,形成了一种天然的局部性优化。
此外,Kafka 在设计上将复杂性控制在 Broker 层,配合操作系统的缓存行为,达到了非常高的吞吐表现。即使在高并发写入的场景中,操作系统也能通过批量刷盘、IO 合并等策略,进一步提升整体性能。
当然,Kafka 本身也提供了一些参数配置,可以进一步控制刷盘策略(如 log.flush.interval.messages、log.flush.interval.ms 等),以便在性能与可靠性之间做出平衡。
Kafka 并没有造轮子,而是充分利用了操作系统层面的资源和能力,这是其高性能实现中一个非常 朴素但有效 的思路,也体现出它工程设计上的成熟与克制。
我们先讲一下常规传输方式为何低效,然后会展开讲解Kafka是如何通过零拷贝技术进行优化的。
如果应用程序要从磁盘读取数据发送到网络,那么会经历下图的流程:
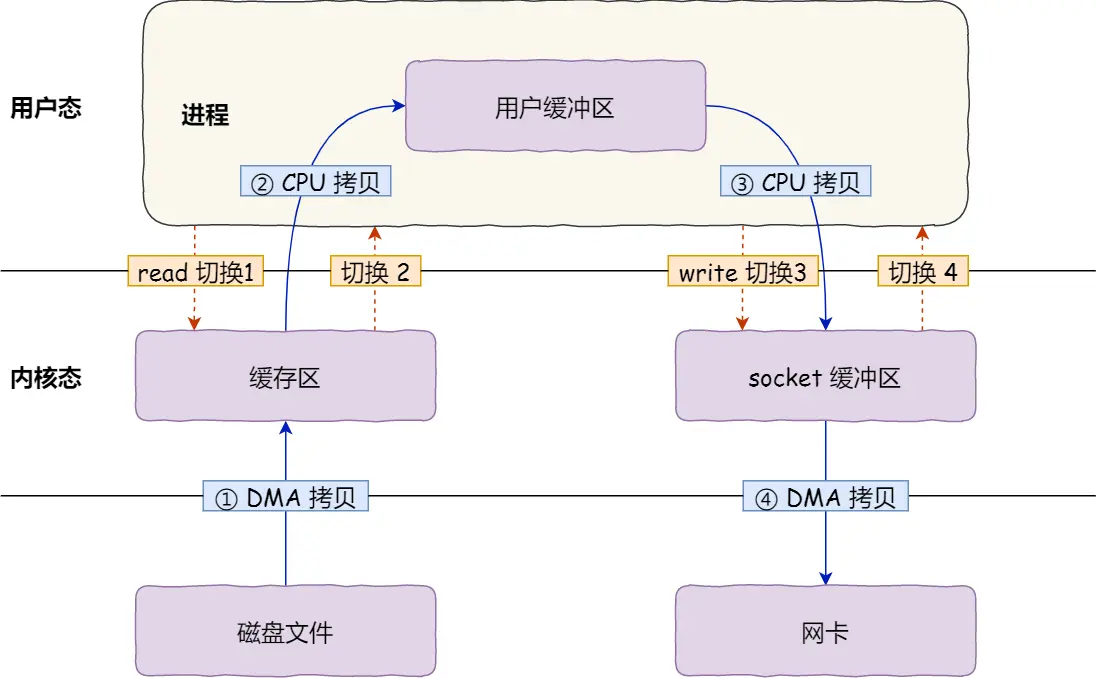
我们从 系统调用 和 数据拷贝 两个角度来分析这个流程。
2次系统调用
一次是 read() ,一次是 write(),每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态,所以共发生了 4 次用户态与内核态的上下文切换。
上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
4次数据拷贝
还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说一下这个过程:
我们回过头看这个数据传输的过程,我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。
这种简单又传统的数据传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
读取磁盘数据的时候,之所以要发生上下文切换,这是因为用户空间没有权限操作磁盘或网卡,内核的权限最高,这些操作设备的过程都需要交由操作系统内核来完成,所以一般要通过内核去完成某些任务的时候,就需要使用操作系统提供的系统调用函数。
而一次系统调用必然会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
所以,要想减少上下文切换的次数,就要减少系统调用的次数。
再来看看,如何减少「数据拷贝」的次数?
在前面我们知道了,传统的文件传输方式会历经 4 次数据拷贝,而且这里面,「从内核的读缓冲区拷贝到用户的缓冲区里,再从用户的缓冲区里拷贝到 socket 的缓冲区里」,这个过程是没有必要的。
因为文件传输的应用场景中,在用户空间我们并不会对数据「再加工」,所以数据实际上可以不用搬运到用户空间,因此用户的缓冲区是没有必要存在的。
那么有没有一种技术,可以是实现数据之间在核心态进行传输,而不需要将数据在核心态和用户态之间来回复制,最终发送给接收端呢?答案是肯定的,下面我们来简单介绍一下零拷贝技术。
所谓的零拷贝是指将数据在内核空间直接从磁盘文件复制到网卡中,而不需要经由用户态的应用程序之手。这样既可以提高数据读取的性能,也能减少核心态和用户态之间的上下文切换,提高数据传输效率。
这种方式的优势非常明显。系统调用次数从两次降为一次,内核态和用户态的切换从四次降到两次,数据拷贝过程也由四次减少到两次。同时,配合 DMA(直接内存访问)机制,还可以进一步减轻 CPU 的负担。
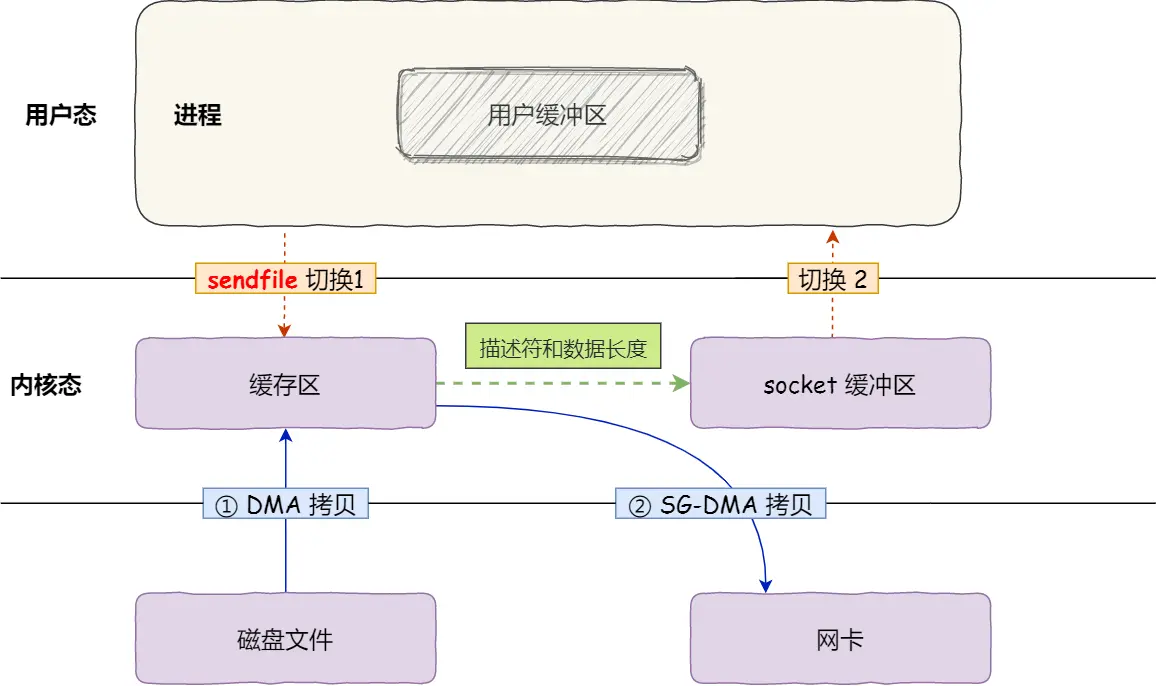
具体流程如下:
Kafka 就利用了「零拷贝」技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
如果你追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo 方法:
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);}如果系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
Kafka 的分层结构体现了经典的分治思想。在架构初期,如果所有消息都写入一个统一文件,很快系统就会出现瓶颈。于是 Kafka 设计了以 Topic 为基本单位的逻辑隔离,每个业务可以独占一个 Topic,保证数据的独立性和管理性。
但单个 Topic 仍无法满足大规模并发需求,于是进一步将 Topic 拆分为多个 Partition,每个 Partition 独立处理消息的写入与消费,从而横向扩展 Kafka 的吞吐能力。
每个Partition还有做进一步拆分,一个Partition实际对应了多个不同的文件,这些文件是分离开来的。分为:
显然,.log就是数据,其它两个文件是不同维度快速定位数据的索引,这样查找的时候,就不是在.log文件直接找,而是先去查找.index或.timeindex这两个文件,这两个文件是要加载到内核内存的,所以不能太多。
有同学可能会问,最后如果某个Topic的某个Partition,因为消息非常多,Partition对应的3个文件不最终也会不堪重负吗?是的,所以Kafka实际还做了进一步分片:按大小滚动,单个文件达到阈值就分裂出一个新的文件继续写。
Partition数据拆分成的多个小文件叫segment,每个segment的大小可以通过log.segment.size配置,默认是1GB,也就是说每1GB,滚动分片一次。
注意,每个小文件也有自己的数据文件和索引文件,索引文件包含偏移索引和时间索引。
比如下面截图中,test-0就是test分区的0号Partition,以目录表示。Partition是由很多segment文件组成,这些segment是根据offset排列,也就是说是有序的,命名方式为当前segment中最小的offset,比如某个segment的最小offset是0,那么对应segment的log文件为:0.log。

正是通过这一套 Topic -> Partition -> 文件 -> Segment 的分层结构,Kafka 实现了从业务逻辑到底层存储的全面扩展能力。
这种分层不仅提升了性能和可维护性,也极大增强了 Kafka 的弹性能力。无论是数据分布、负载均衡,还是磁盘清理、消费追踪,分层设计都是核心支撑。
批量处理是 Kafka 高性能的关键组成部分,在生产、消费和持久化三个环节都有用到批量处理。
首先,从开发者角度来看,Kafka Producer 会先将消息暂存在缓冲区中,等待数量或时间阈值达到后再统一发送给 Broker,这样减少了网络调用次数,提升了传输效率。
比如网络带宽为10MB/S,一次性传输10MB的消息比传输1KB的消息10000次显然要快得多。
影响批量发送的主要是如下3个参数:
1.linger.ms
在发送一个批次消息前等待多少ms,默认是0,即不等待,来一条消息就赶紧发出去,如果想增大单个批次的消息数的话可以增加linger.ms,比较常见的是设置为3s,5s,10s,20s等等。
这种做法其实就类似于很多件快递,一件一件发出去、运输肯定成本高,但是一批快递发在一个集装箱里,发到目的城市,那效率自然会有所提升。
2.batch.size
数据量累计到多大就发送,即使没有达到linger.ms,只要批次字节数达到batch.size也会立刻发送。
默认为16KB。我们可以将批量大小增加到32KB或64KB可以帮助提高请求的吞吐量。每个分区的批次是独立计算的,所以不要将batch.size设置为太高的数字,否则可能会遇到高内存使用率!
3.buffer.memory
该参数控制生产者用于缓存消息的总内存大小。如果生产者发送消息的速度超过了 Kafka 接收的速度,这个缓冲区会被填满,在批量场景要额外注意,比如你希望批量发送64KB的消息,但是你buffer.memory配置只有12KB,这显然是会阻塞生产者写入流程的,所以buffer.memory需要配置得大一些,默认值是32MB,还是很稳的。
这里有一个推荐的高吞吐配置,大多数业务用以下配置都没问题,但是具体是否可行要看实际业务场景和你机器自己的内存大小:linger.ms :20s;batch.size:32kb;buffer.memory:32MB
在消费端,Kafka Consumer 同样采用了批量拉取机制,即一次拉取多条消息进行处理,不仅提升了吞吐,也减轻了网络抖动对消费性能的影响。
配置参数如下:
这里有一个推荐的高吞吐配置,但是具体是否可行要看实际业务场景:
"max.poll.records":500; 即每次poll最多拉取500条记录
"fetch.min.bytes":1024; // 最小拉取1024字节的数据
"fetch.max.wait\.ms":500。 // 最长等待500ms此外,从服务端视角看,Kafka 在写入磁盘时也是打包处理的。Broker 并不是每来一条消息就写一次磁盘,而是将多个消息批量刷入磁盘,这种方式极大减少了磁盘 IO 次数,是服务端性能的核心保障之一。
批量操作的设计非常贴合 Kafka 的流式数据特点,兼顾了网络效率、处理并发能力和 IO 性能,是 Kafka 在大规模消息系统中表现优异的根本原因之一。
Kafka 支持在生产端或 Broker 端对消息进行压缩,以减少网络传输的数据体积。数据压缩适合带宽资源紧张而 CPU 资源相对宽裕的场景,能有效提升整体传输效率,是 Kafka 保持高吞吐的重要机制之一。
Kafka 支持多种压缩算法,如 gzip、snappy、lz4、zstd 等。压缩的本质是以 CPU 换带宽,将原始消息压缩后再传输,从而减少网络负担,提高传输速度。在数据量大、带宽成为瓶颈时,这种做法优势尤为明显。
消息压缩不仅节约网络资源,还能降低磁盘存储开销。尤其是在消息结构重复较多时,压缩效果会非常显著,是 Kafka 架构中典型的空间换时间的优化策略。
通常压缩发生在 Producer 端,即将多个消息压缩后发送给 Broker。Broker 接收到压缩数据后,并不会立即解压,而是按原样存储和转发,直到消费者拉取时再进行解压。这样可以最大化压缩效果,避免重复操作。
Kafka 也支持在 Broker 端进行压缩,但多数情况下建议在客户端完成,便于控制压缩策略与效率。
默认情况下,broker是不开启压缩的,体现在配置上,就是主题压缩定义为compression.type=producer,即即直接继承 producer 端所发来消息的压缩方式,即无论是否压缩,无论采用哪种压缩算法,broker 都原样存储消息。
broker进行压缩享受不了发送环节的性能增长,但还是可以享受更高磁盘利用率。Broker压缩是主题级的,也就是说不同主题可以用不同的压缩算法。
如果Broker开启了压缩,而Producer未开启压缩,那么没有歧义,就在Broker执行压缩即可。
但是如果Broker和Producer端同时开启了压缩配置,那么有如下规则:
1.如果Broker端和Producer端的压缩设置是一样的(例如lz4),那么Broker不会进行重复压缩,消息批次将按原样写入日志文件
2.如果Broker端和Producer端的压缩设置是不一样的,那么Broker将解压缩消息并将其重新压缩为其配置的格式。
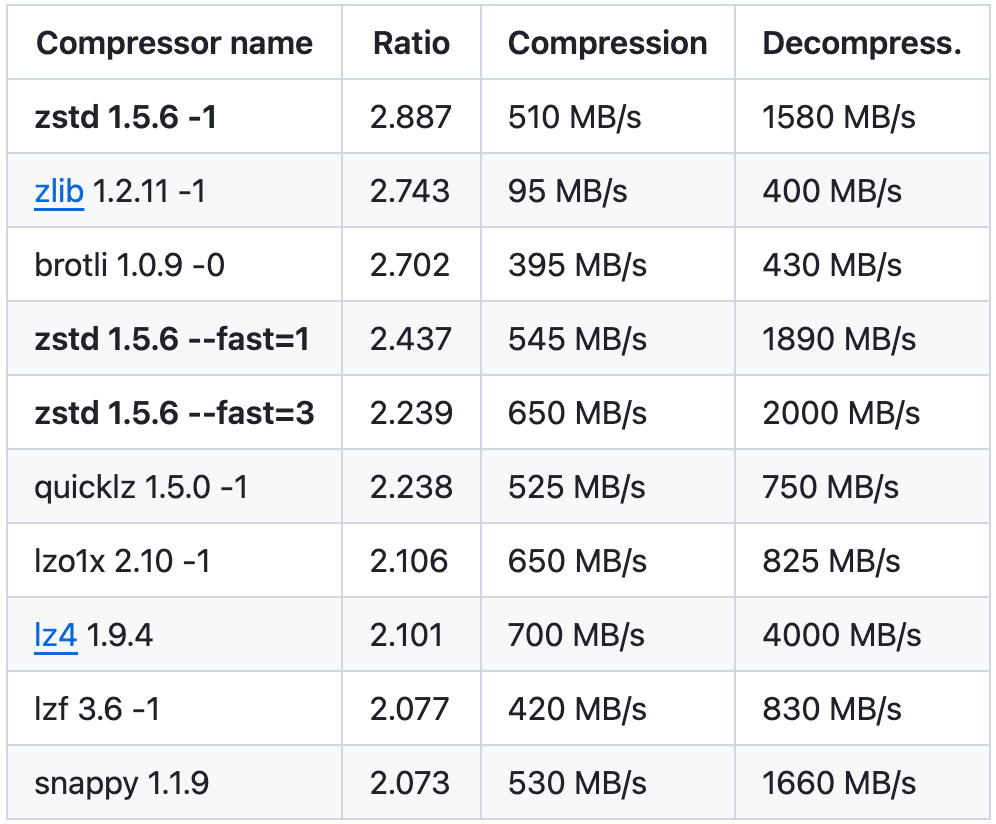
目前 Kafka 共支持四种主要的压缩类型:Gzip、Snappy、Lz4 和 Zstd。关于这几种压缩的特性。
其实Gzip我们可能是平常工作生活中打交道是最多的,它的缺点在于CPU高、速度又不是很快。
Snappy是Google的作品,性能非常棒,也没有什么明显的缺点,各方面都还可以。
Lz4特点在于速度非常快,但是缺点是压缩比率很低,也就是快是快,但是压缩不够到位。
Zstd是 Facebook开源的压缩算法,压缩率和压缩速度都还可以,和Snappy一样比较能打,直到 Kafka 的 2.1.0 版本才引入支持。
zstd在其Github https://github.com/facebook/zstd 也公布了他们的压测对比数据,可以看看。
关于这些压缩算法,有个印象即可,不用去记,如果面试时问到能说出一个就可以了。